来源:ECCV2022
链接:Efficient Point Cloud Segmentation with Geometry-Aware Sparse Networks | SpringerLink
0、Abstract
在点云学习中,稀疏性和几何性是两个核心特性。近年来,为了提高点云语义分割的性能,人们提出了许多通过单个表示或多个表示的方法。然而,这些作品未能保持性能、效率和内存消耗之间的平衡,无法恰当地集成稀疏性和几何体。为了解决这些问题,我们提出了几何感知稀疏网络(GASN),利用点云在单个体素表示中的稀疏性和几何特征。GASN主要由稀疏特征编码器和稀疏几何特征增强两个模块组成。稀疏特征编码器提取局部上下文信息,稀疏几何特征增强增强稀疏点云的几何特性以提高效率和性能。此外,我们在训练阶段提出了深度稀疏监督,以帮助收敛和缓解内存消耗问题。我们的GASN在SemanticKITTI和Nuscenes数据集上都实现了最先进的性能,同时运行速度显著加快和消耗更少的内存。
1 Introduction
大规模室外点云分割一直是自动驾驶系统的关键任务,对效率、性能和内存消耗都有很高的要求。PointNet[29]和PointNet++[30]是直接在原始点云上操作,维护和利用点云的核心属性之一点态几何(精确测量信息)的开创性工作。然而,由于内存消耗和运行时效率的原因,很难将这些方法应用到户外场景中。RandLA[14]采用了随机抽样策略来减少点数以提高效率,但这会导致一些信息的丢失。随着稀疏卷积的普及[10,50],基于稀疏体素的表示(如AF2S3Net[6]和Cylinder3D[59])也有了一定的进展,稀疏体素表示是一种保留度量空间的表示。与点表示方法相比,稀疏体素表示方法的优点在于能够有效地快速扩展接受域,这是点云的另一个重要特性。此外,基于稀疏体素的表示方法,聚集了局部邻域内的点特征,可以显著减少内存的使用。此外,传统的或目前流行的卷积神经网络(convolutional neural networks, cnn)可以直接应用于提取更好的上下文信息。
最近,一些作品认识到单一表示的局限性,并通过组合多个表示来探索更丰富的信息。PVCNN[21]融合了基于点和基于体素的表示与MLP层和密集的3D卷积层,但没有考虑到点云稀疏性。SPVCNN[35]和DRINet[52]设计了稀疏卷积层和逐点运算层,融合了稀疏性和几何特征。此外,RPVNet[47]结合了范围视图、点和体素表示用于点云分割。当前多表示学习的总体框架是利用稀疏卷积进行局域性和稀疏性学习,利用点态运算进行几何学习,目的是将稀疏性和几何性结合起来,以获得更好的性能和效率。虽然这些方法带来了一些性能改进,但由于额外的视图或表示带来了额外的计算成本,它们的效率不足以满足实时系统的需要。同时,从这些方法的实验结果来看,基于体素的表示仍然是主要的表示方法,这些方法已经取得了不错的性能。受到这些观察的启发,我们提出了几何感知稀疏网络,以探索基于单个稀疏体素表示的额外几何属性。我们的几何感知稀疏网络将稀疏性和几何性结合在一个表示中,而不引入多表示融合的额外计算成本。我们的几何感知稀疏网络有两个模块:稀疏特征编码器(SFE)和稀疏几何特征增强(SGFE)。每个模块以另一个模块的输出作为输入,以较低的计算成本和内存使用量充分探索点云的稀疏性和几何形状。在SGFE中(如图1所示),我们提出了一种新型的多尺度稀疏投影层,以探索更多的几何形状和关注尺度选择的多尺度特征选择。除此之外,与最常见的密集方式相比,我们采用了深度稀疏监管来缓解内存消耗的压力。

我们的贡献总结如下:
•我们提出了一种新颖的网络架构,以充分利用稀疏性和几何性质。提出了稀疏几何特征增强中的多尺度稀疏投影层和注意尺度选择来增强几何特征学习。
•提出深度稀疏监管,以稀疏方式设计监管,以降低存储成本。
•我们在大规模户外场景数据集上评估了我们提出的方法,包括SemanticKITTI[1]和nuScenes-lidarseg[3],以证明我们的方法的有效性。在Nvidia RTX 2080 Ti GPU上,我们在两个数据集上都实现了最先进的性能,平均运行速度为59 ms。
2 Related Work
Indoor Point Cloud Segmentation.
室内场景中的点云往往具有定位紧密、范围小的点。现有的室内点云分割方法可以根据其模型表示进行分类。对于基于点的方法,PointNet[29]、PointNet++[29]以及他们基于类似架构的相关作品[19,20,28,31,45,53]是本任务中比较流行的模型。这些作品大多探索了当地的邻里环境,同时保留了点云的固有几何形状。它们使用不同的分组和排列不变操作来提高性能。其他主流方法[16,17,21,25,33]遵循体积表示,将空间划分为离散像素/体素,然后将2D/3D CNN架构应用于规则表示。基于图的点云学习方法[37,40,41,43,48,55]也很流行,这是因为图具有处理无序性和建模点之间关系的能力。目前,随着变压器的普及,一些作品[11,56]通过引入基于变压器的架构,在室内点云学习中取得了最先进的性能。虽然已经提出了许多新的体系结构来改善点云学习,但其中一些无法推广到数千个点的户外场景。
Outdoor Point Cloud Segmentation
与室内点云分割相比,现有的方法由于点云的稀疏性和数量较多而面临很大的挑战。KPConv[38]、RandLA[14]等基于点的方法扩展了PointNet[29]或PointNet++[30]的体系结构,采用采样策略来缓解这些问题,但会导致额外的信息丢失。KPConv[38]引入核点选择过程,生成高质量的采样点。基于距离视图的方法[8,44,46]将点云投影到距离视图或球形表示中,并应用高效的CNN架构。然而,范围视图不能维护度量空间并引入失真,这可能会导致性能下降。其他一些方法[6,7,49,54,59]将点云量化到一些预定义的空间或表示中(例如,极坐标网格、二维网格和稀疏三维网格),然后应用规则卷积神经网络或稀疏卷积[10,42,50]来实现效率和性能之间的平衡。有一组作品集成了多种表示,包括范围视图、体素表示和点表示,以深入挖掘不同表示的潜力[21,35,47,52]。这些作品针对不同的表示采用了不同的架构,并提出了不同的融合策略,与基于单一表示的方法相比,表现出了强大的性能增益,但代价是额外的运行时间。
Image Segmentation to Point Cloud Segmentation.
全卷积网络(FCN)[22]是利用深度学习进行图像分割的先驱作品之一。DeepLab[4]、PSPNet[57]等人在FCN和现有流行的CNN架构的基础上,提出了多尺度或多膨胀率策略来挖掘更层次的局部上下文信息[5,51]。此外,HRNet[34]将不同分辨率的热图融合在一个框架中,保持高分辨率以提高性能。考虑到图像分割的巨大过程,很多作品[26,39,52,54,59]都将这些技巧应用到点云分割中,包括层次学习、注意机制或骨干网。一些著作[7,59]建立在具有稀疏卷积加速度的U-net[32]上。
3 Approach
该方法的整体网络结构由两个模块组成:1)稀疏特征编码器和2)稀疏几何特征增强。稀疏特征编码器(Sparse Feature Encoder)是快速局部上下文聚合的基本块。稀疏几何特征增强以稀疏特征编码器的输出作为输入,通过多尺度稀疏投影和注意尺度选择层对几何信息进行增强。两个模块在稀疏空间中交互,节省了计算量,提高了运行效率。此外,我们在体素水平上应用深度稀疏监督,以缓解密集监督导致的内存问题。图2展示了我们提出的方法的总体框架。

图二。GASN的整体结构。在图的上半部分,首先将LiDAR输入体素化为稀疏特征。然后,稀疏特征编码器利用稀疏卷积对稀疏特征进行处理。此外,稀疏几何特征增强通过多尺度稀疏投影和注意尺度选择层对特征进行增强,生成下一阶段的稀疏特征编码器的输入。稀疏监督作为辅助损耗附加在稀疏特征编码器的输出上。底线描述了多尺度稀疏投影和注意尺度选择的细节。N是点的数量,Mi是体素的数量,CE是通道维数。(这个是怎么循环吗?大概意思是紫色方块内是不同分辨率的体素特征,融合到原始的体素特征上,黄色为不同分辨率融合的的特征,最终要行程一个特征,采用的方式加权,权值是不同分辨率混的的结果)
3.1 Prerequisite
Voxelization.
给定网格尺寸s,体素化是将点pi =(xi,yi,zi)离散为其体素指数Vi的过程,通过以下公式:

其中·为向下取整功能。Vi表示为第i点pi的体素指数的标量,并且。由于每个体素可以包含多个点或多个细粒度的亚体素,我们定义了分散函数Ψ和收集函数Φ,该函数在[52,58]中被广泛使用,其中,前者在较大的体素尺度下进行聚类过程,将点特征或亚体素特征![]() 聚类到体素特征
聚类到体素特征![]() ,而后者则从体素特征V反转到点特征或亚体素特征S:
,而后者则从体素特征V反转到点特征或亚体素特征S:

其中C为通道号,和
为点云的体素索引,
为体素特征
的体素索引,
相同。Eq. 2和Eq. 3主要揭示点特征与体素特征之间的相互转换:散点和聚点。为了将原始点云转换为体素特征,我们使用了类似于在DRINet[52]和Cylinder3D[59]中使用的方法,即GAFE。
3.2 Sparse Feature Encoder
稀疏体素表示使得应用标准的卷积运算来提取局部上下文信息变得容易。因此,为了保持较高的运行效率和探索更多的局部性,我们使用了稀疏卷积层[10,42,50]而不是密集卷积层[21]。稀疏卷积的优点之一在于稀疏性,卷积运算只考虑非空体素。在此基础上,我们利用稀疏卷积构造稀疏特征编码器(SFE),以较低的计算量快速扩展感受野。我们采用ResNet瓶颈[12],而将ReLU激活替换为Leaky ReLU激活[24]。为了保持较高的效率,所有用于稀疏卷积的信道数都设置为64。
3.3 Sparse Geometry Feature Enhancement
在从稀疏特征编码器获得稀疏体素特征后,我们的目标是通过稀疏几何特征增强(SGFE)以更多的几何指导增强体素特征。
Multi-scale Sparse Projection Layer
受前人[30,52,57]的多尺度特征聚合研究的启发,我们注意到分层的上下文信息有助于增强特征提取能力,特别是对于具有固有尺度不变性和几何形状的点云。多尺度特征为点云学习带来了更多的几何增强,因为每个体素尺度反映了一个特定的物理维度属性。但是,由于点云的稀疏性,直接应用PSPNet[57]中的金字塔池模块是不适用的。此外,DRINet[52]通过分散操作提出了点级的点池,但在考虑大规模场景时引入了额外的巨大内存成本。因此,我们通过散射运算提出了多尺度稀疏级别,但在考虑大规模场景时引入了额外的巨大内存开销。因此,我们提出了多尺度稀疏投影层Multi-scale Sparse Projection Layer,以更低的存储成本在稀疏体素水平上利用多尺度特征。
给定输入体素特性![]() ,对应体素索引V,预定义池化比例集S,其中NV为体素数,C为通道数。多尺度稀疏投影在算法1中描述。不同尺度包含不同的几何先验,因为点云中的尺度语义与真实维度成正比,反映了物理度量空间。对于每个池化尺度s,我们首先重新计算尺度s下的体素索引,以确保相同池化窗口内的特性具有相同的体素索引。然后,我们应用Scatter运算Ψ进行稀疏池化,以在每个池化区域内获得局部几何先验
,对应体素索引V,预定义池化比例集S,其中NV为体素数,C为通道数。多尺度稀疏投影在算法1中描述。不同尺度包含不同的几何先验,因为点云中的尺度语义与真实维度成正比,反映了物理度量空间。对于每个池化尺度s,我们首先重新计算尺度s下的体素索引,以确保相同池化窗口内的特性具有相同的体素索引。然后,我们应用Scatter运算Ψ进行稀疏池化,以在每个池化区域内获得局部几何先验![]() 的特征均值,其中NVs为尺度下的体素数,嵌入特征
的特征均值,其中NVs为尺度下的体素数,嵌入特征![]() 是基于具有可学习MLP层的归一化特征。然后,我们使用张量元素乘法来获得尺度s下的投影特征
是基于具有可学习MLP层的归一化特征。然后,我们使用张量元素乘法来获得尺度s下的投影特征![]() 。最后,揭示不同尺度下几何形状的特征被叠加在一起。
。最后,揭示不同尺度下几何形状的特征被叠加在一起。
(这一步获得不同体素尺度下的特征,上图紫色部分)


Attentive Scale Selection.

(怎么和图有点不大一样)
从多尺度稀疏投影层获取多尺度特征后,多尺度特征融合的简单方法是应用张量拼接或张量求和。因此,来自不同尺度的所有特征都具有相同的权重,并被同等对待。在点云中有一个共识,即不同尺度的特征具有不同的几何先验,并侧重于场景理解。从这个角度出发,在SENet[13]和SKNet[18]的激励下,融合多尺度特征的更好方法是在尺度维度上对每个特征通道采用重加权策略,重新分配每个尺度的重要性。
我们首先对第一阶段融合的所有输入张量{Os|s∈s}求和,收集不同尺度的所有信息,如下所示:
 其中
其中![]() 在求和的特征中。受最近流行的关注作品[18]的启发,我们应用了一个尺度上的具有sigmoid激活的MLP层来得到每个尺度的注意嵌入。最后,应用注意权值张量与多尺度特征的张量相乘,得到尺度维的张量和:
在求和的特征中。受最近流行的关注作品[18]的启发,我们应用了一个尺度上的具有sigmoid激活的MLP层来得到每个尺度的注意嵌入。最后,应用注意权值张量与多尺度特征的张量相乘,得到尺度维的张量和:

其中A O∈RNV×C是SGFE模块的输出注意事项。图3展示了整个过程。

3.4 Deep Sparse Supervision
在二维和三维语义分割任务中,对每个像素/体素进行密集监控是一种流行的方法。之前的方法[54,59]通过密集的监督生成密集的特征图。虽然这些作品在其网络架构中考虑了稀疏性,但在设计损耗时却忽略了这一特性,而损耗是2D和3D数据的关键区别之一。事实上,使用细粒度特性映射的密集监控会给内存使用带来严重的过载。例如,当使用0.2 m的网格时,对于具有20个类的单一密集特征图,内存消耗(大约500 Mb)可能会有问题。在此基础上,受[23]的启发,我们提出了一种新的深度稀疏监督(DSS)方法来处理深度稀疏的监督问题。
具体来说,我们在训练阶段生成不同尺度的体素语义标签,监督只对有效体素起作用,而不是对整个密集的特征图起作用。每个体素标签都使用体素内的主要投票点标签进行分配。由于我们在不同尺度上叠加了生成稀疏体素特征的多个SFE块,我们将稀疏监督作为辅助损失逐步应用于输出体素特征,这是一种有用的优化技术。我们还对主最终预测分支应用了稀疏监督。辅助损耗有助于优化训练,而主分支损耗占梯度的大部分。
在测试阶段,所有辅助分支都被禁用,以保持运行时效率。这种训练策略在基于图像的分割[22]中已经证明了其有效性。我们考虑了点云的稀疏性,并以稀疏的方式应用它以节省内存消耗。
(多层分辨率的损失函数旨在训练用,计算损失函数只再有内容的上计算 )
3.5 Final Prediction
对于最终的语义预测,我们将每个稀疏几何特征增强层输出的多阶段特征通过收集操作融合到最细粒度的体素尺度上。为了获得逐点结果,我们还采用了收集策略,即每个点都附加其所在体素的语义特征。我们框架的整个算法在算法2中进行了说明。

4 Experiments
我们在大规模户外场景数据集SemanticKITTI[1]和Nuscenes[3]上进行了实验,验证了所提方法的有效性。除此之外,我们还进行消融研究来验证所提议的组件。
4.1 Datasets
SemanticKITTI.
Nuscenes.
网络细节。我们对两个数据集使用相同的设置。我们沿着xyz维度用0.2 m的体素尺度量化点云,以生成初始稀疏体素特征。我们用稀疏特征编码器和稀疏几何特征增强四个块设计了几何感知稀疏网络。在消融研究中,我们也评估了块数选择对性能和效率的影响。对于多尺度稀疏投影层,我们采用核大小和stride[2, 4, 6, 8],可以覆盖粗池和细池区域。与之前的研究类似,我们在训练阶段采用了随机翻转、随机点辍学、随机尺度和全局旋转等方法。在损耗设计中,我们结合了Lovasz损耗[2]和交叉熵损耗作为监督。使用了Adam优化器[15],初始学习率为0.0002,批处理大小为4,用于50个epoch。学习速率每15个epoch以0.1的比率衰减。
4.2 Results On SemanticKITTI
单次扫描:我们在表1中提供了我们的几何感知稀疏网络以及其他最新方法的每类详细定量结果。与以前的方法相比,我们的GASN在保持实时推理效率的同时实现了最先进的性能。虽然我们的几何感知稀疏网络并不是每个类都能达到最好的结果,但它在所有类之间都达到了平衡的结果。即使与多种表示融合方法相比[35,47,52],我们的方法仍然有相当大的优势。

此外,我们还对一些最先进的方法和表2中的GASN的模型复杂性和延迟进行了定量分析,以说明我们的方法的高性能时间比。与以往的方法相比,该方法以最小的计算成本获得了最佳的mIoU结果,证明了该方法的有效性和有效性。SemanticKITTI验证集上的一些定量结果如图4所示。

SemanticKITTI Multiple Scans:同时,我们也对SemanticKITTI Multiple Scans挑战进行实验,以验证我们的GASN的有效性。在该任务中,我们直接将多个对齐的扫描图像叠加为输入,不需要任何时间融合算法,然后根据算法2生成逐点输出预测。我们不应用任何后期处理来细化。如表3所示,与之前的方法相比,我们的几何感知稀疏网络在两个指标上都有了显著的改进。与同样基于体素的AF2S3Net[6]算法相比,该算法获得了非常有竞争力的收益(约4.4%)。我们的方法几乎在所有方面都超过了现有的方法,证明了我们的方法的有效性和泛化能力。为此,GASN可以作为大规模点云语义分割任务的高效、强大的骨干。

4.3 Results On Nuscenes
为了验证我们的方法的泛化能力,我们还报告了测试集上Nuscenes-lidarSeg[3]任务的结果。如表4所示,GASN取得了非常强的结果,16个大类中有10个优于其他方法。对于行人类、摩托车类等规模较小的类,稀疏几何特征增强效果显著,证明了我们通过分层特征学习和注意尺度选择来捕获和整合多尺度上下文信息的稀疏几何特征增强的有效性。

4.4 Ablation Study
Components Study
我们的基线模型,如表5所示,只使用了稀疏特征编码器,已经取得了不错的性能。结果表明,稀疏卷积体素表示在室外点云语义分割任务中具有较强的特征提取和上下文信息学习能力。多尺度稀疏投影层捕获层次几何信息的能力提高了1.8%。此外,我们运用细心的尺度选择来重新分配每个尺度对每个渠道的重要性。这种策略使网络的焦点集中在更显著的规模上,性能增益约为1.9%。其次,在训练阶段加入深度稀疏监督,mIoU提高到69.4%,提高了1.7%。更重要的是,当推理时,深度稀疏监督将被禁用,不会为部署带来额外的计算成本。

block个数
块数的选择在网络中起着至关重要的作用。更少的块可能会导致欠拟合问题,而更多的块意味着更多的计算成本和内存消耗,这意味着效率低下。为了找到更好的块数,我们进行了改变该参数的实验。当块号为1 - 5时,性能分别为50.8%、61.3%、67.4%、69.4%和69.9%,速度分别为26 ms、33 ms、41 ms、59 ms和70 ms。当块数增加到5时,性能从50.8%增加到70.2%,而运行速度几乎翻倍。此外,当块号为4时,增加一个块会引入额外的11 ms延迟,而mIoU仅提高了约0.5%。因此,我们在实验中选择block number为4。
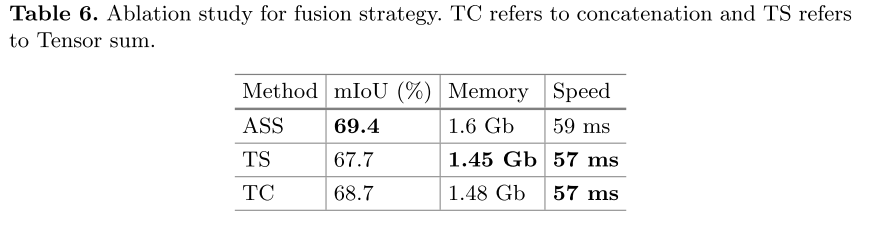
Scale Features Fusion Strategy
通过与不同融合策略的比较,分析了所提算法的有效性。我们采用了特征融合中常用的张量拼接和张量求和方法。对于这项工作,我们使所有其他建议的模块能够进行公平的比较。如表6所示,ASS层是融合多尺度特征的较好方法,与张量求和相比增加了2.0%,但只带来了2ms的代价。表7还显示,其他利用多种表示的模型也可以从ASS策略中受益。与DRINet[52]相比,原来的SPVCNN[35]在逐点分支中不存在分层学习,启用ASS后其性能会有所提高。

Sparse or Dense Supervision
深度稀疏监管是我们GASN的另一个特征。在这个实验中,我们比较了稀疏和密集监控的内存成本和性能。为了简单起见,我们去掉了深度辅助损失分支,只留下主要监督。稀疏和密集监督的内存消耗都只包括预测张量和标记张量,而不包括梯度张量的内存消耗。稀疏监视(6 Mb)的内存占用率仅为密集监视(552 Mb)的1%左右,且两种方法的结果接近,分别为69.4%和69.5%。通过引入稀疏监督,我们可以使用更大的批量进行训练,从而实现高效的训练。
Deep Sparse Supervision.
我们的深度稀疏监督可以作为点云语义分割任务的一个通用组件,并将该策略与其他流行的模型相结合,验证其有效性。如表7所示,深度稀疏监督可以在不增加推理计算开销的情况下提高流行模型的性能。
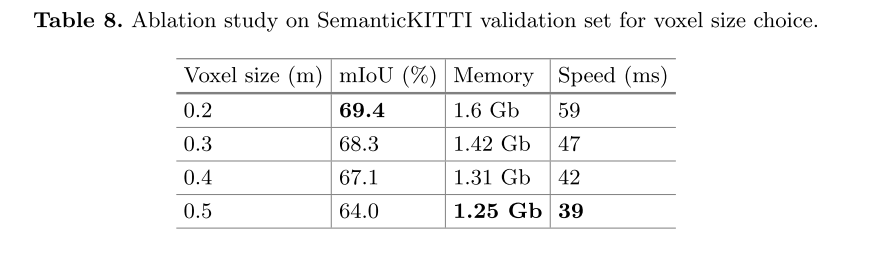
Voxel Size
为了选择最适合实验的体素尺寸,我们还进行了实验来验证效果。如表8所示,运行速度、内存消耗和性能随着体素尺寸的增大而显著下降。因此,我们在实验中选择体素尺寸为0.2 m。
5 Conclusion
在本文中,我们提出了我们的几何感知稀疏网络,作为一个有效的网络体系结构的点云分割。我们的GASN通过充分利用稀疏体素表示中的稀疏性和几何形状来处理点云分割,以保持性能和效率。GASN由稀疏特征编码器(SFE)和稀疏几何特征增强(SGFE)组成。SFE可以提取局部上下文信息,而SFE可以通过多尺度稀疏投影和注意尺度选择来增强几何形状。此外,我们采用深度稀疏监督的方法,以较低的内存开销加速收敛。在大型户外场景数据集上的实验表明,我们的方法实现了最先进的性能和令人印象深刻的运行效率
自己总结:
1、稀疏特征编码器(SFE)和稀疏几何特征增强(SGFE)这两个模块顺序是怎么一次前向传播传递的呢?
2、Attentive Scale Selection 实际上是不同尺度的特征融合的方法
3、稀疏卷积?稀疏监督?