《A DEEP REINFORCED MODEL FOR ABSTRACTIVE SUMMARIZATION》
引言
最近接触到了一个新的概念policy gradient。在强化学习当中,基本思想是根据当前的状态,计算采取每个动作的价值,然后根据价值去贪心选择动作。如果省略中间步骤,直接根据状态,输出动作,也就是强化学习当中另外一种重要的方法。具体的大家可以参考这一篇博客
这一篇文章,主要是在attention上面进行改进,另外在Loss方面增加了,强化学习部分。
1、首先改进了Attention,惩罚之前出现过的分布,防止模型关注同样的输入部分,能够一定程度减少解码时的重复。
2、decoder部分也进行attention,并且作为上下文向量的输入,得到表示,避免重复。但是文章说到其适用于长文本,对于短文本,效果不是很好。
3、Loss中加入了强化学习部分,改进了Log似然exposure bias,提高Rouge得分。
同样还是老思路,从5个方面阐述。
- Motivation
- Model
- Experiment
- Discussion
- Question
1、Motivation
Attentional, RNN-based encoder-decoder models for abstractive summarization have achieved good performance on short input and output sequences.
短文本已经做的比较好,长文本,这些模型会输出重复的语句和不连贯的短语。我们的解决方法就是,通过分别在输入和输出引入内部注意力机制进行解决。
word by word的监督式学习和极大似然目标函数会使得模型存在exposure bias问题,即训练时Teaching,预测时可能会造成累计错误传播。所以希望在训练时引入ROUGE指标,通过比较参考摘要和生成的摘要,给出摘要的评价。但由于ROUGE不可导,无法直接对ROUGE进行梯度计算。因此,可以考虑用强化学习将ROUGE指标加入训练目标,reward函数用Rouge函数替代。
Note:有很多虽然表达不一致,但是语义一致的摘要。但是Rouge并不是解决语义问题,它只是为了能够让得到的tgt更加接近参考摘要。
最大似然只是考虑了word-by-word分布,而Rouge考虑了生成的tgt和参考之间的关系。
2、Model
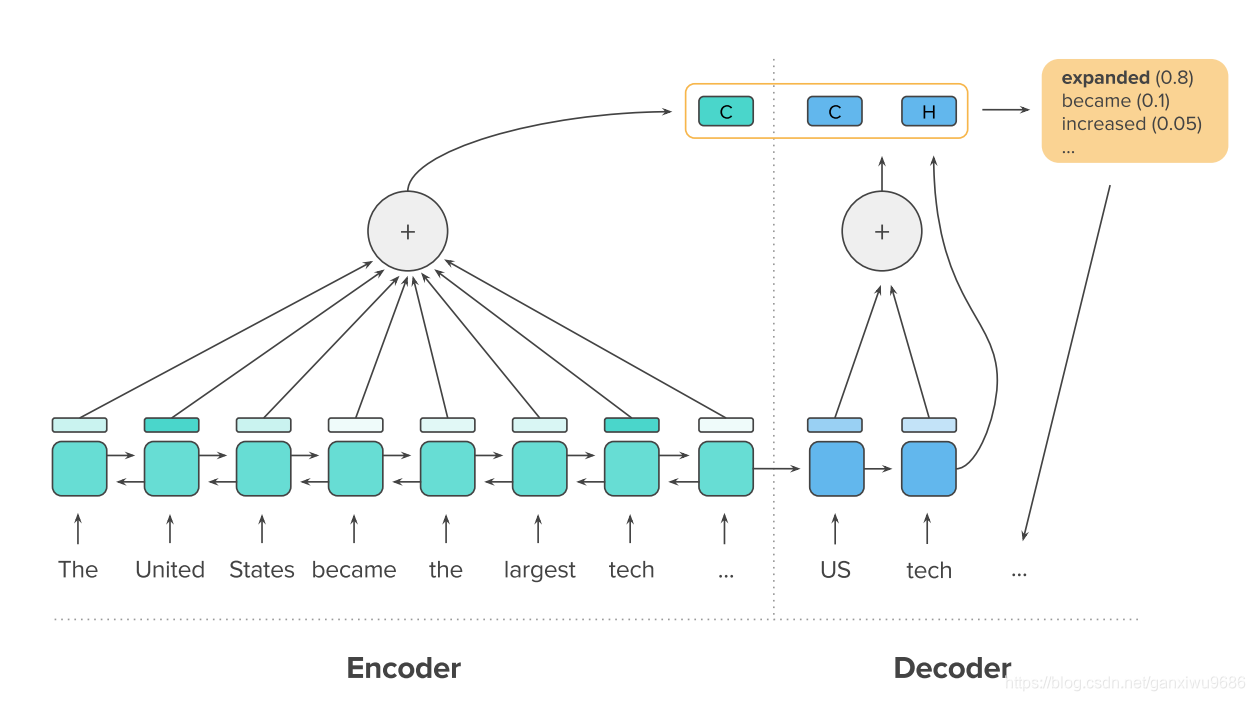
模型结构主要是一个Encoder和Decoder组成。Encoder的部分得到上下文表示,attention的计算方式,也进行了改进。Decoder的部分,不再根据当前时刻的输入、隐藏状态和attention得到下一个词的概率分布,而是由INTRA-DECODER ATTENTION得到。
2.1 Encoder——INTRA-TEMPORAL ATTENTION
相比较之前的attention,改进点如下:
e表示encoder,d表示decoder;
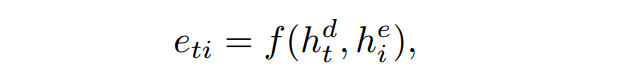
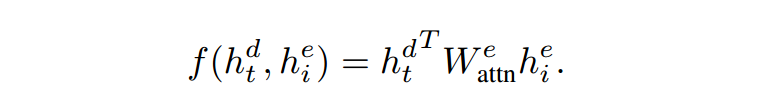
计算得到
之后,照理直接softmax即可,但是为了防止模型关注同样的输入部分,我们对其进行一下处理:
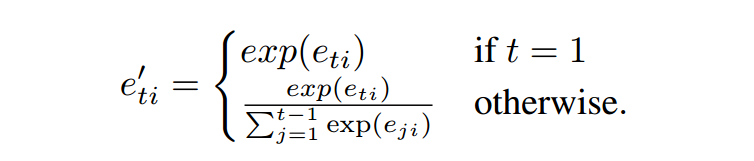
然后再得到上下文表示
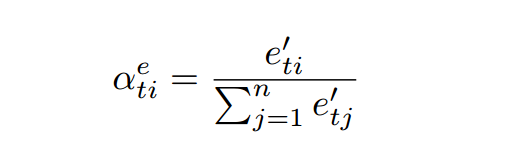
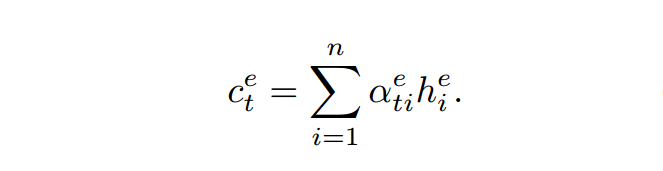
2.2 Decodr-INTRA-DECODER ATTENTION
传统的计算方式
,
经过softmax得到概率分布;
这篇文章
中间向量
变为
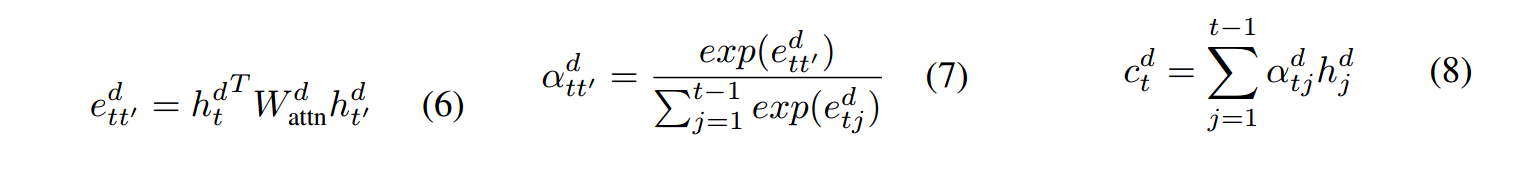
2.3 TOKEN GENERATION AND POINTER
得到概率分布:
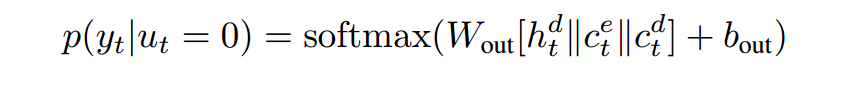
ut as a binary value, equal to 1 if the pointer mechanism is used to output yt, and 0 otherwise
用Input的attention作为源端词的分布:
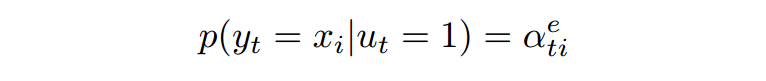
生成概率:
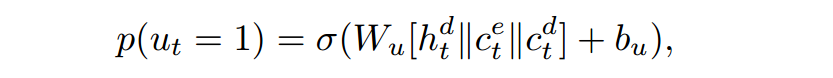
最后得到预测词
的概率大小:
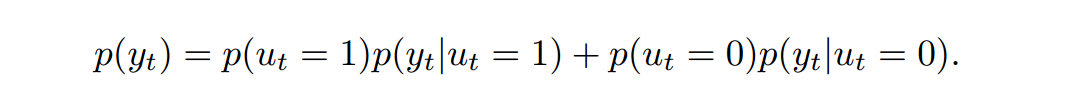
2.4 HYBRID LEARNING OBJECTIVE
2.4.1 同理计算最大似然,其中
为标准答案: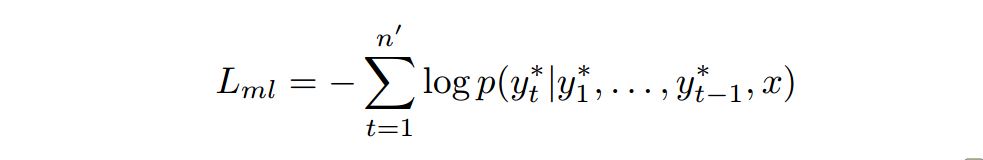
2.4.2 POLICY LEARNING
再每一个解码时刻从 中采样得到 尖是从解码概率分布中选择最大的那一个。
r表示将
和
尖分别与ground truth计算ROUGE
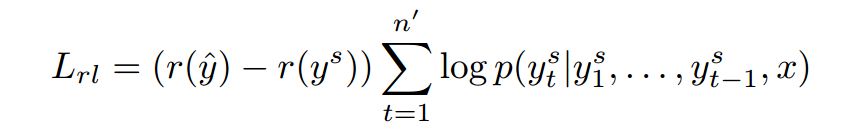
最终优化目标:
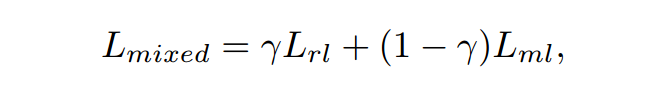
3、Experiment
3.1 Dataset
论文在两个数据集上进行了测试。CNN/DAILY MAIL和NEW YORK TIMES。美国有线新闻网(CNN)和每日邮报网(Daily Mail)中收集了大约一百万条新闻数据作为机器阅读理解语料库。
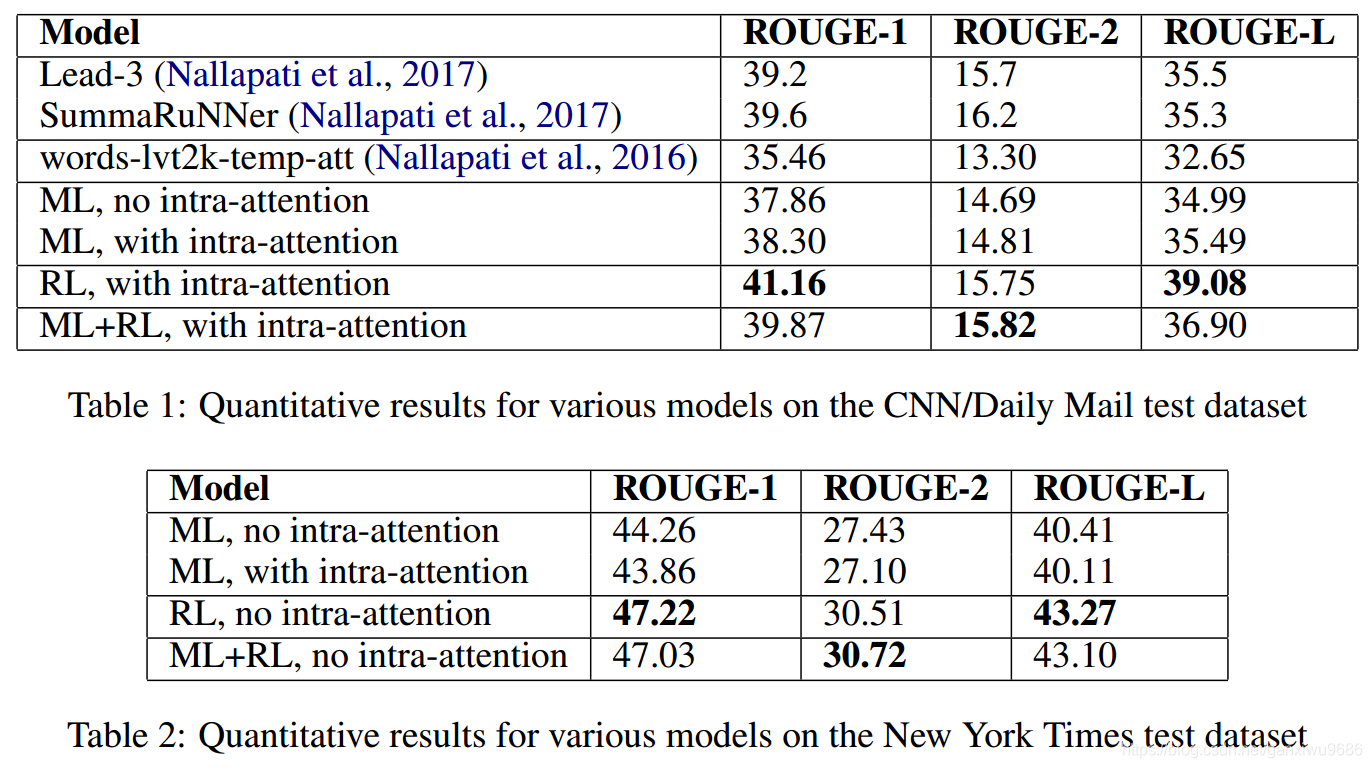
首先看第1个图,第1行表示的是从文章当中,抽取前三个句子进行总结。从图中可以发现,加了改进的注意力及之后,效果得到了提升。通过强化学习,也能提升效果。但是有一个比较奇怪的现象就是,只用强化学习,得到的分数比联合的分数要高。作者在后边做了一个辅助性的实验,说明了原因。
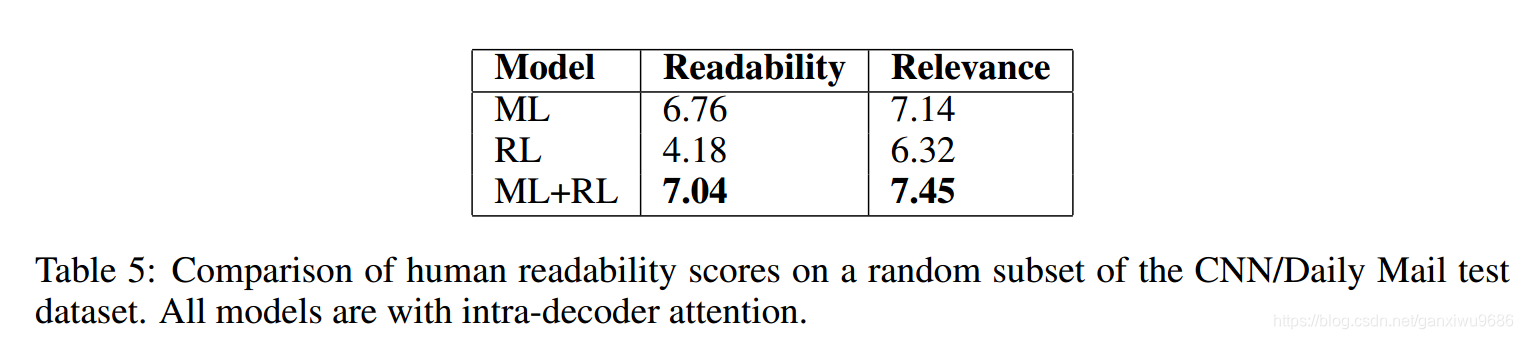
虽然强化学习,在分数上有所提高。但是它的可读性以及相关性较差。可见下图。
实验效果可以和PG net进行比较
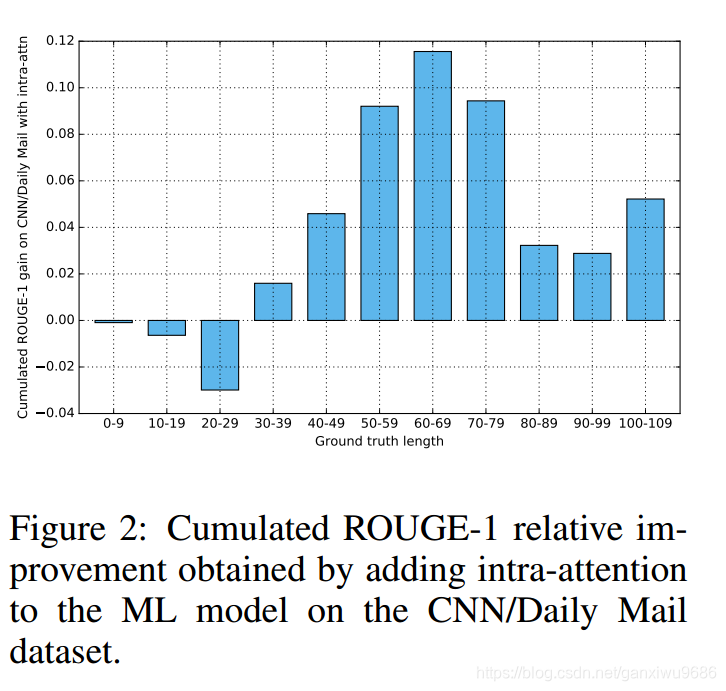
然后再看table 2,发现不加改进的解码端的注意力机制,效果更好。作者又做了另外一个辅助性的实验,这个实验说明 Ground truth的长度,会影响该注意力的效果。该注意力对于比较长的Ground truth效果较好。而NEW YORK TIMES的 Ground truth长度都较短,所以不适用于INTRA-DECODER ATTENTION。
这个也证明了,我们的猜想,在比较长的输出序列中INTRA-DECODER ATTENTION有好的效果。
4、Discussion
对于这篇文章,我觉得最突出的一点就是在损失上面增加了强化学习。虽然他对attention的改变,也在一定程度上,减少了重复词的生成。但是在指针生成网络当中,通过coverage向量,也能够减少重复词的产生。而且从实验效果对比来说,不加强化学习的结果和指针生成网络,得到的结果差不多。
当然了,对attention的改进也可以说是一个创新点,只不过并没有发生质的变化。
缺点就是对于短文本的output,该attention却没有效果,如何构造一个通用的模型是未来值得研究的。
5、Question
1、论文第4页,2.3
The ground-truth value for ut and the corresponding i index of the target input token when ut = 1 are provided at every decoding step during training.
首先是在训练时候,第二个条件是when ut = 1,两个东西被提供,一是t时刻的目标输入,这个肯定提供。第二个是The ground-truth value for ut ,不太理解,应该不是指ground-truth,不然直接说ground-truth就好了啊,for ut是什么?
2、论文2.5节,
Another way to avoid repetitions comes from our observation that in both the CNN/Daily Mail and NYT datasets, ground-truth summaries almost never contain the same trigram twice.Based on this observation, we force our decoder to never output the same trigram more than once during testing.
“almost never contain the same trigram twice”这个“trigram ”是什么?
3.论文第5页,3.2节,
, which is obtained by sampling from the
probability distribution at each decoding time step
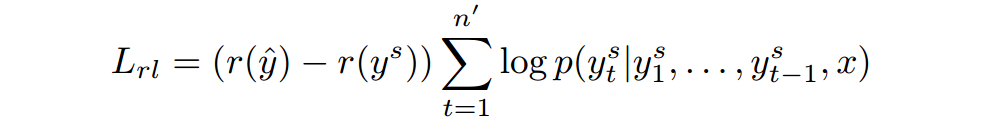
从里面采样,那么这个概率分布
probability distribution怎么得到的?