原文代码: https://github.com/liuzhuang13/DenseNet
pytorch实现 https://github.com/liuzhuang13/DenseNet/tree/master/models
论文动机:在CNN中靠近输入、输出的层之间如果包含更短的连接,则CNN训练时会更高效、更准确;
提出网络:Dense Convolutional Network(DenseNet);L层的传统卷积网络需要L次连接,而DenseNet需要次连接;
优点:减轻梯度消失问题;加强特征传播;支持特征重用(feature reuse);减少参数数量(因为不需要重新学习冗余的特征图,尽管这个网络结构是dense connectivity,参数反而大大减少);
Introduction
ResNets、Hightway Networks、FractalNets, they all share a key characteristic: they create short paths from early layers to later layers.
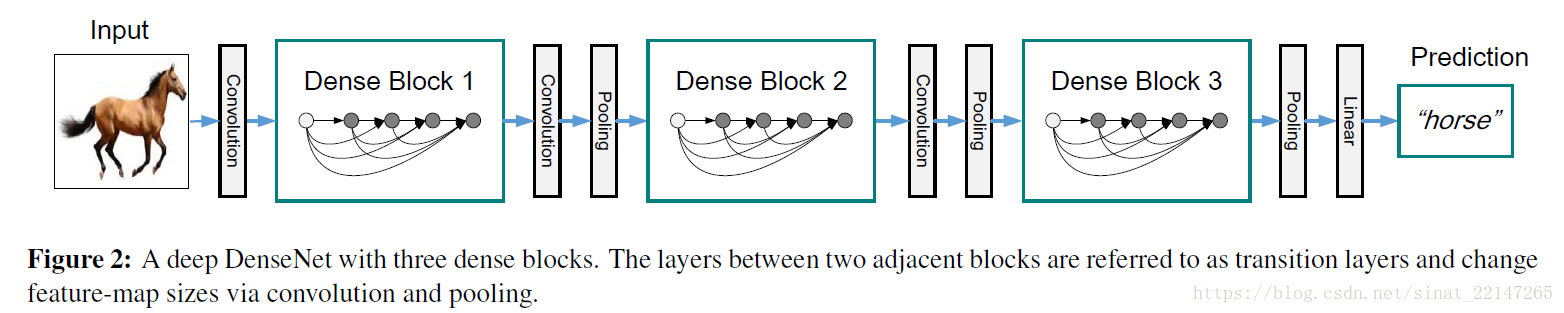
下图时DenseNet结构,意义:
To ensure maximum information flow between layers in the network, we connect all layers (with matching feature-map sizes) directly with each other. To preserve the feed-forward nature, each layer obtains additional inputs from all preceding layers and passes on its own feature-maps to all subsequent layers.

传统的前馈结构可以被看作是具有状态的算法,这个状态在层与层之间传播,每一层接收前面一层传递的状态然后写到下面一层,它改变了状态,但也传递了需要保存的信息。
本文提出的DenseNet结构可以准确区分增加到网络上的信息以及被保存下的信息;同时Dense connections有正则化作用,会在小训练集的任务上减少过拟合的影响;
DenseNets
: 层的索引;
: 非线性转换,是一个复合操作,比如BN、ReLU、Poolingu哦这Conv;
:
层的输出;
------------------------------------
先回忆ResNets:
优点:梯度可以从后面的层通过恒等函数到达前面的层;
缺点:因为采用加和的方式将恒等函数和结合,可能阻碍信息在网络中的传播;
------------------------------------
Dense connectivity:
------------------------------------
考虑到特征图尺寸可能由下采样引起的变化,我们将网络分成多个dense blocks,如下图;
transition layers: 是block和block之间的,卷积和池化操作;
Growth rate:
每个函数产生
个特征图,则
层有
个输入特征图,
是输入层的通道数;
就是网络的Growth rate;
------------------------------------
Bottleneck layers:
1X1的卷积在3X3的卷积前作为一个bottleneck layer,可以提高计算效率;
------------------------------------
Compression:
为了进一步提高模型的compactness,我们可以减少过渡层的特征图的数量。
相关参考 https://blog.csdn.net/u012938704/article/details/53468483