引言
图像,通常被理解为矩阵,矩阵的每个元素是像素,像素是(Red,Green,Blue)三个数值组成的向量。
换个角度,矩阵也可以理解为图谱(Graph),图谱由点(node)和边(edge)组成。相邻的点之间,有边相连。而矩阵是一种特殊的图谱,特殊性表现在两方面:
- 矩阵每个点有固定个数的邻点。 从图谱的角度看,图像中的像素,就是图谱中的点。图像中每个像素,也就是图谱中的每个点,周边总共有 8 个邻点。
- 矩阵每条边的权重是常数。从图谱的角度看,图像中的每一个像素,只与周边 8 个邻点之间有边,边的长短权重,是常数。
图像作为一种特殊的图谱,特殊性体现在这两个限制上面。如果放松了这两个限制,譬如地图、人际关系,论文引用网络、医学知识图谱等等问题,就更复杂了,深度学习算法也会面临更大的挑战。
Graph Attention Networks 尝试将图谱作为输入,并强调不同样本点之间的关系,用深度学习的方法完成分类、预测等。
以上摘自新智元
摘要
堆叠基本的图自注意力层,形成深度学习网络。基本的图自注意力层能够为中心结点(样本)的邻域结点(样本)分配不同的权重,表示邻域结点对中心样本的不同重要性,在空域内可以理解为结构信息等,加权和得到中心样本的新表示。
算法
1:Input : node feature 的集合
h=[h1,h2,⋯,hN]hi∈RF(F表示特征维度)2:为了能够让特征更具表达能力,采用了线性变换先对原始特征进行处理
h′=[h1′,h2′,⋯,hN′]hi′∈RF′
hi′=WhiW∈RF′×F 3: 任意两个样本之间注意力系数的计算公式
eij=a(Whi,Whj)a表示共享注意力机制4:一般来说,通过注意力机制可以计算任意两个样本的关系,使一个样本用其他所有样本来表示,但是第一,基于空间相似假设,一个样本与一定范围内的样本关系较密切,第二,样本较多的时候,计算量非常大。——因此,对于一个样本xi来说只利用邻域内的样本计算注意力系数和新的表示。
这篇文章的问题:1,邻域的计算 2.邻域的取值
αij=softmaxj(eij)=∑k∈Nieeikeeijj∈Ni利用样本邻域计算新的表示公式如上,为方便比较计算,使用softmax函数进行归一化处理。
5: 文章利用权重向量参数化的单层前馈神经网络表示注意力机制a,并使用LeakyRuLU激活结点,所以计算公式具体表示为:
αij=∑k∈NieLeakyRuLU(aT[Whi∣∣Whk])eLeakyRuLU(aT[Whi∣∣Whj])a∈R2F′∣∣表示concat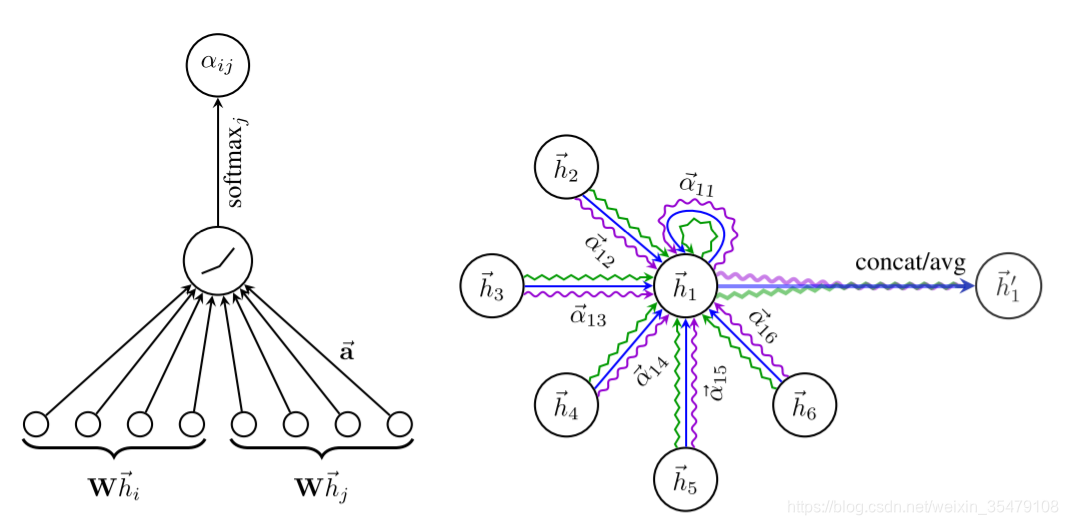
_ 图1左表示特征转换,注意力机制,激活,归一化生成两个样本之间注意力系数的过程。右,表示用结点邻域的以不同注意力机制表示样本结点的过程。_
6:每个结点根据其邻域结点及邻域结点的注意力权重系数计算其新的表示:
h
i′=σ(j∈Ni∑αijWhj)7:图右,不同的箭头表示不同的注意力机制,在非最后一层多头注意力以concat形式结合
h
i′=∥k=1Kσ(j∈Ni∑αijkWkhj)8:最后一层,计算各个注意力机制下的均值:
h
i′=σ(K1k=1∑Kj∈Ni∑αijkWkhj)
实验实现的过程没有邻域的计算,根据数据生成图谱是事先数据处理完成的,无论是训练,交叉验证,还是测试,都是一张完整的图和训练数据,标签数据也是完整的,只是在不同的阶段只有那一部分为真实标签,其余全为0,也就是半监督学习,之前觉得AffinityNet: Semi-supervised Few-shot Learning for Disease Type Prediction还有Non-Local Neural Networks实质一样的,但是具体的实现及灵活性有待商榷。