论文链接:
先说一说Seq2Seq模型,这种常用在两个对应序列建模的模型,在问答、翻译等方面有很多应用。其一种经典的实现方式是通过对输入序列进行RNN(特别的Lstm)建模,之后将最后一个状态(hidden state)作为 context vector (输入序列信息的概括表达),并以此为输出的初始状态进行建模。
将context vector 看作对于输入的“记忆”,一些看法是由于其可能在输入层自身递归过程中难以充分表达所有输入信息,应该将其他输入的状态也加入到“记忆”表示中,于是有人提出了使用attension进行对输入的各个状态进行加权得到 context vector的格式,见下图:
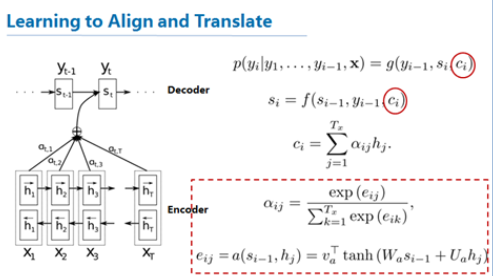
这是一种使用softmax对于输入信息(hidden state)进行选择的方法,其中的softmax是使用了输入序列信息与输出序列信息的某种相关性的度量,从而也可以看作使用相关性对于输入信息的“加权过滤”、“信息筛选”。
对Seq2Seq喂如QA语料就可以进行问答建模,上述attension机制的对应作用就是更好地提取问题中的有效信息,是一种直接在问与答间进行建模的形式。
从问答的场景输入还可能包括对于场景或者历史的“记忆”,即除了问、答外还包含上下文的记忆,如何让模型更好地记住这部分信息是这篇论文要解决的问题,其提出的方法基本上就是前述类softmax attension机制在“记忆候选集”上的对偶实现(这里的对偶是相对Seq2Seq的输入而言的),思路是类似的,对于每一个问题会有很多候选记忆,定义一种softmax对于记忆候选集进行与问题有关的信息筛选就是这篇文章所主要讲的。
文章要点:
1、端对端。
2、定义多层结构,在给出输出(答)之前,充分筛选提取记忆信息。
数据格式与基本模型结构:

模型构造:




def build_memory(self):
self.global_step = tf.Variable(0, name="global_step")
self.A = tf.Variable(tf.random_normal([self.nwords, self.edim], stddev=self.init_std))
self.B = tf.Variable(tf.random_normal([self.nwords, self.edim], stddev=self.init_std))
self.C = tf.Variable(tf.random_normal([self.edim, self.edim], stddev=self.init_std))
# Temporal Encoding
self.T_A = tf.Variable(tf.random_normal([self.mem_size, self.edim], stddev=self.init_std))
self.T_B = tf.Variable(tf.random_normal([self.mem_size, self.edim], stddev=self.init_std))
# m_i = sum A_ij * x_ij + T_A_i
Ain_c = tf.nn.embedding_lookup(self.A, self.context)
Ain_t = tf.nn.embedding_lookup(self.T_A, self.time)
Ain = tf.add(Ain_c, Ain_t)
# c_i = sum B_ij * u + T_B_i
Bin_c = tf.nn.embedding_lookup(self.B, self.context)
Bin_t = tf.nn.embedding_lookup(self.T_B, self.time)
Bin = tf.add(Bin_c, Bin_t)
for h in xrange(self.nhop):
self.hid3dim = tf.reshape(self.hid[-1], [-1, 1, self.edim])
Aout = tf.matmul(self.hid3dim, Ain, adjoint_b=True)
Aout2dim = tf.reshape(Aout, [-1, self.mem_size])
P = tf.nn.softmax(Aout2dim)
probs3dim = tf.reshape(P, [-1, 1, self.mem_size])
Bout = tf.matmul(probs3dim, Bin)
Bout2dim = tf.reshape(Bout, [-1, self.edim])
Cout = tf.matmul(self.hid[-1], self.C)
Dout = tf.add(Cout, Bout2dim)
self.share_list[0].append(Cout)
if self.lindim == self.edim:
self.hid.append(Dout)
elif self.lindim == 0:
self.hid.append(tf.nn.relu(Dout))
else:
F = tf.slice(Dout, [0, 0], [self.batch_size, self.lindim])
G = tf.slice(Dout, [0, self.lindim], [self.batch_size, self.edim-self.lindim])
K = tf.nn.relu(G)
self.hid.append(tf.concat(axis=1, values=[F, K]))
