《Get To The Point: Summarization with Pointer-Generator Networks》
Introduction
复现
上篇论文《(Copynet)Incorporating Copying Mechanism in Sequence-to-Sequence Learning》模型与此比较相似,主要用在摘要和对话系统,不过其网络结构比较复杂,混合概率是两者的和(而且目标词属于类别的打分是一个“分段函数”)。
最近看的指针生成网络,其混合概率直接就是decoder端的softmax加上源端的attention分布,而且还有赖于权重 ,该值属于0~1,越大,表示越依赖生成部分。
本篇的架构仍然是五部分:
- Motivation
- Model
- Experiment
- Discussion
- Question
1、Motivation
Seq2Seq的模型结构在摘要的生成方面提供了可能,但是他们有三个缺点,一是无法生成OOV,只能生成词汇表的词;二是会产生错误的事实,比如姓名之间,Amy可能变成Bob;三是自我重复,如German beat German beat German beat …可见下图。


由此,文章提出两种思路解决上述问题。
- 首先使用一种混合的指针生成网络,他能够从源端复制单词,也能够从词表当中去生成词语。这一点和copynet相似。
- 第二,就是使用coverage,去追踪那些已经被总结的单词,以至于不会重复生成。
2、Model
2.1 Base-line
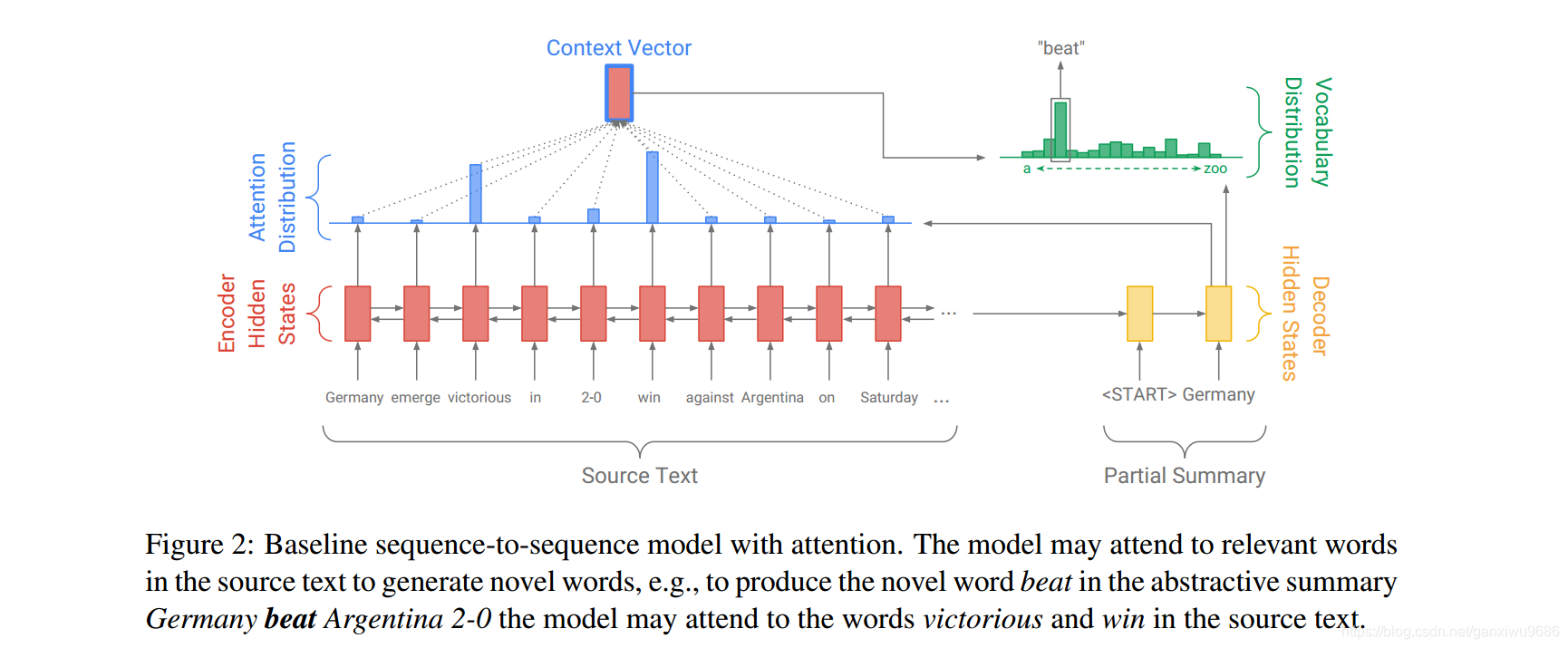
如上图所示,每一个词在编码端,经过双向LSTM,在解码端编码层的隐藏状态和解码端的隐藏状态,做一个加法attention。如公式(1)(2):
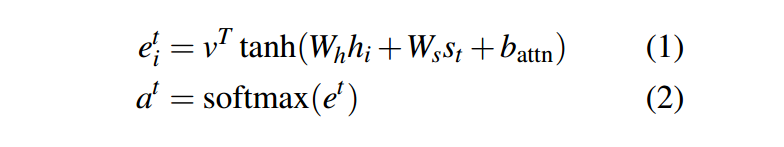
得到上下文向量
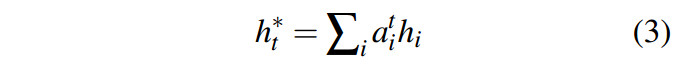
由上下文向量和解码端的隐层状态,经过两层线性层,得到最后的词表概率分布,
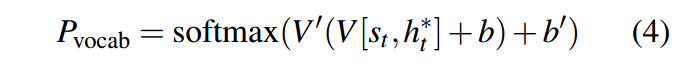
在预测阶段选择概率最大的那个词,作为解码端的输出。在训练的时候,通过求负的对数函数,得到损失函数,令损失函数最小。
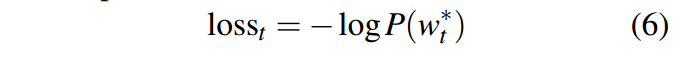
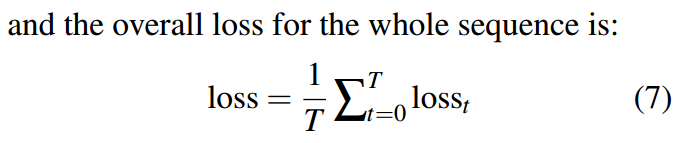
2.2 pointer generator model
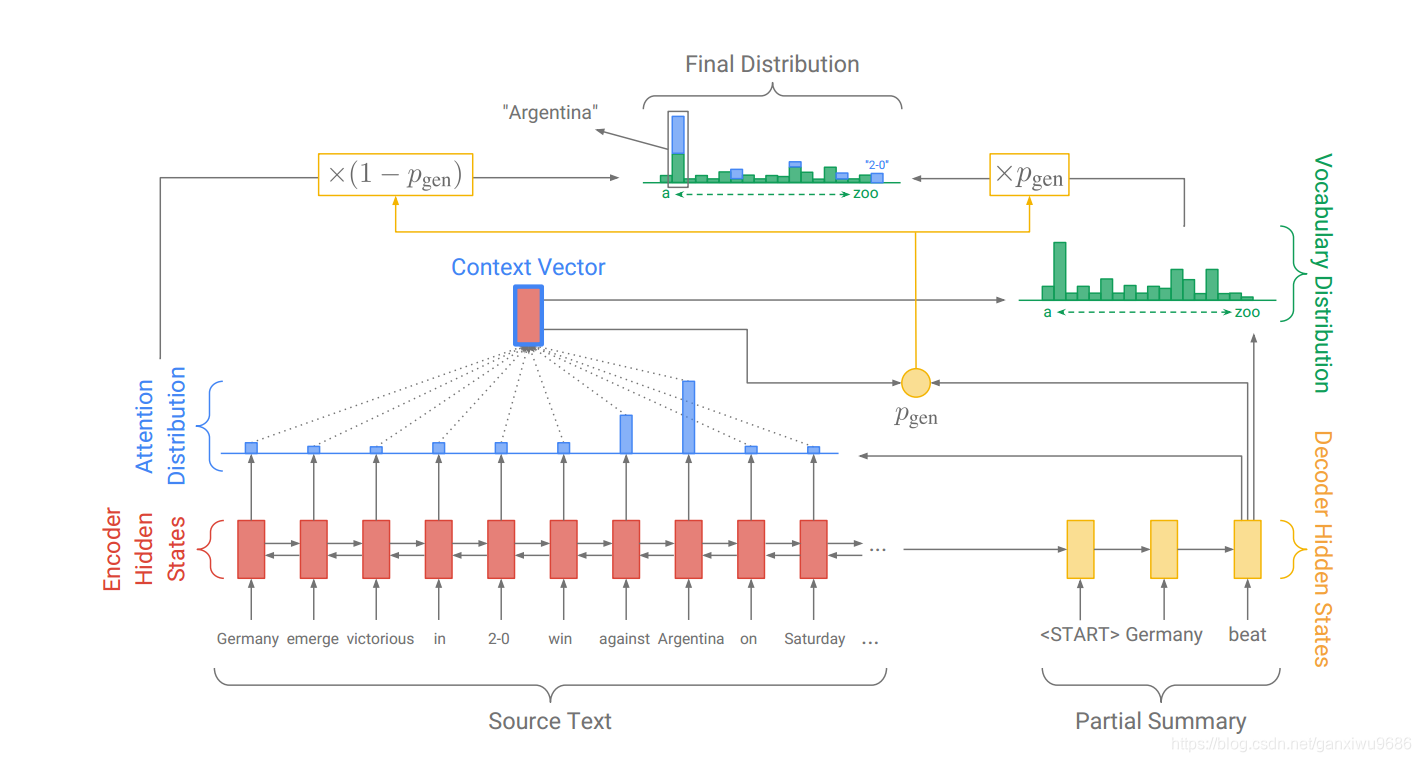

指针生成网络是baseline和指针网络的混合,它可以通过指向去复制,也可以从固定的词表当中去生成词汇。注意力分布的计算和上下文向量的计算不变。
多增加了一个生成概率,属于0~1。对于每一个解码时刻,都存在一个这样由上下文向量,解码状态隐藏层和解码的输入共同计算的概率。可见Figure 3中的2-0。
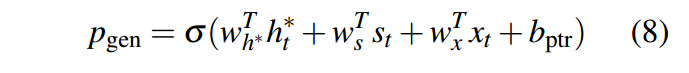
最后词
的概率由词表概率和源端的attention分布共同获得,如果
未在源端出现,则
为 0。在预测阶段,输出一个概率分布,其维度是词表长度加上源端句子中未出现在词表中的单词个数。
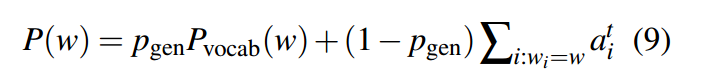
2.3 coverage mechanism
在序列到序列的模型当中,重复是一个普遍的问题,尤其是在长文本摘要生成任务当中。在我们的coverage模型当中,文章使用一个coverage向量
,其代表了当前解码时刻,t之前的所有注意力分布的和。
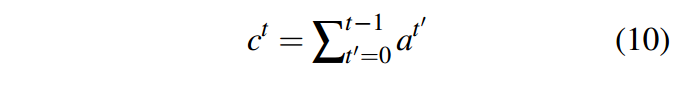
是个零向量,在计算attention得分的时候,我们将词向量作为新的输入。
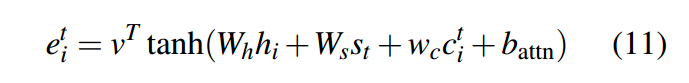
并且也需要增加loss惩罚项:
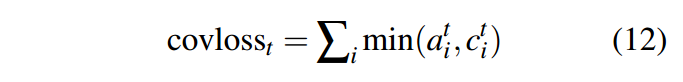
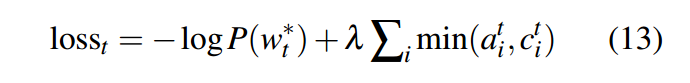
这里可以这么理解,以第一时刻为例,c1表示的是a0,那么a0跟a1当中选择最小的作为loss。如果a0和a1关注的都是同样的分布,那么loss就会比较大,如果他们关注的是不同的分布,因为选择的是两者之中最小的那一个,所以这样的loss会比较小。目的就是想让他每一个时刻关注的分布是不一样的,这样可以避免repeat。
3、Experiment

对于指针网络使用的词表大小是50k,因为它能够去处理OOV问题,所以比这篇文章Nallapati et al.’s(2016)150k源和60k目标端词表要小。但是在baseline模型中,还是用了50k和150k以便比较,然而发现并没有提高评价指标。
除此,指针网络的训练参数也少了很多,the baseline model has 21,499,600 parameters, the pointer-generator adds 1153 extra parameters (wh∗, ws, wx and bptr in equation 8), and coverage adds 512 extra parameters
这一点并不是很理解。
另外,对于coverage的训练,并不是从第一轮就加入coverage loss,作者也进行了这个实验,发现从第一轮就加入该loss,效果不好。训练的时候,在后期才增加了coverage model,多训练了300轮,loss也要加上,不然效果也不明显。这个就比较神奇了,第二点不理解。
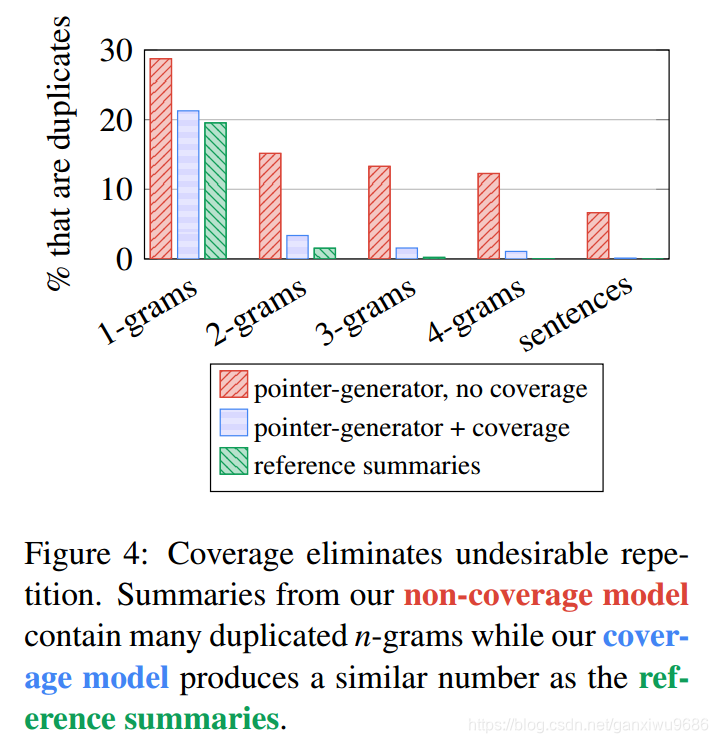
下图是各种模型预测结果的n-gram重复比,发现加了coverage的确实重复比例小很多。
4、Discussion
优点:
- 是一种混合的方法,既考虑了复制,又考虑了生成,而且还有coverage,能够去减少重复文本的产生
- 模型明了,不像copynet那样,但和copynet思路上有点相似。
- 作为一种生成式的摘要,相比以往的抽取式摘要,确实有了很大进步
缺点:
- 直接用文章的前三句话,效果更好,这可能和英文的表达方式有关,总结性的话往往在最开始。如何解决这个问题?
- 参考摘要也是人做出来的,比较具有主观性,有时候生成的摘要完全是正确的,但是和参考摘要去匹配却,只能得到比较低的分。这种评测指标的改进,也是需要被考虑的。
Question
1.指针网络的训练参数也少了很多?why?
2.coverage的训练,并不是从第一轮就加入coverage loss。why?
3.Table1的最后一句话,The METEOR improvement
from the 50k baseline to the pointer-generator model,
and from the pointer-generator to the pointer-generator+coverage model, were both found to be
statistically significant using an approximate
randomization test with p < 0:01.
说使用p <0.01的近似随机化检验发现它们均具有统计学意义 是什么意思。
4.有文章第六页右边开始,说道,For training,
we found it efficient to start with highly-truncated
sequences, then raise the maximum length once
converged.
也不是很理解。
5.文章第9页还提到关于这个生成概率p,在训练的时候,会从0.3逐渐上升到0.53。这说明模型一开始是复制,然后学会去以一半的概率生成。然而在测试阶段,会有一个0.17的平均值。
这个生成概率p难道不是在训练的时候训练好了就固定了,为什么在测试阶段还会变化?
文章给的解释是说,因为在训练的时候会有word by word的监督,但是在测试的时候没有。不是很理解。