论文名称:Get To The Point:Summarization with Pointer-Generator Networks
模型Pointer-Generator Networks可以简称为PGN
本文是2017年ACL论文。
ArXiv链接:https://arxiv.org/abs/1704.04368
本文是针对长文本生成式摘要的经典工作,主要是为了解决OOV问题使用了copy机制。
文章目录
1. 生成式摘要的背景
具体的内容可以看我别的博文,我就不在这里写了。总之,生成式任务的基本范式都是encoder-decoder+attention
常见缺点:
- OOV:因为词表不够大所以会出现
[UNK](但是说实话这个在LLM场景下已经不多见了。但是对于基于词的古典工作来说,确实挺严峻的,毕竟词表太大了机器受不住) - 重复
- 语义不连贯、语法逻辑性低、重述准确性不高(胡说八道,这个现在LLM也照样)
本文通过融合抽取式模型,来缓解了这些问题。
2. PGN
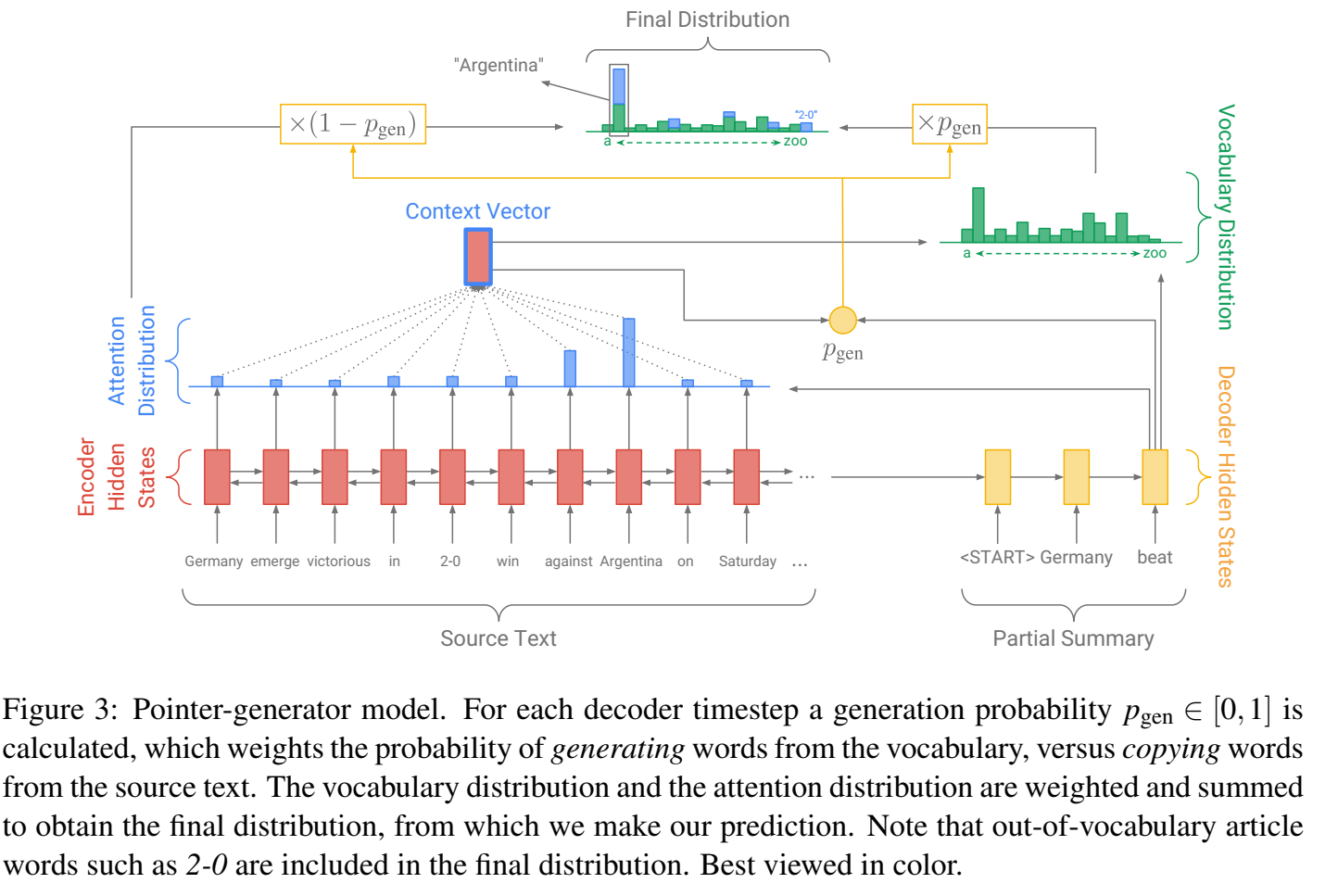
generator:encoder-decoder + attention 直接生成
pointer:从原文中选择
制定阈值,决定用generator还是pointer生成下一个词
解决重复性问题:coverage-mechinism
2.1 generator

encoder:双向序列模型,如Bi-LSTM / Bi-RNN
decoder:因为解码的过程要确保不能见到将来的信息,所以解码器一般是单向序列模型,如单向的lstm/rnn
注意力机制(attention):基于当前step的decoder state 以及encoder所有step的 hidden state 计算 attention score,即对encoder的所有step的 hidden state 的关注程度。然后基于 attention score 加权encoder端的 hidden state 形成当前decoder的 context vector。解码步再基于这个 context vector 和当前 decoder state 去生成词。
2.2 pointer
以generator部分介绍的attention得分为每个token被复制到target中的概率,则每个词是source中所有出现该词的attention得分的总和。
2.3 从generator和pointer中选择用哪个
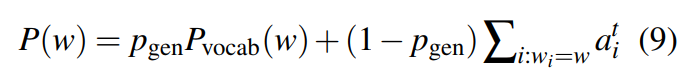
每一个单词被选择的概率由两部分组成(相当于加权求和):被generator选择和被pointer选择
这样没有在词表中的token和没有在source中出现的token就都有概率被选中、可以被生成了。
权重 p g e n p_{gen} pgen通过context vector和decoder hidden state计算得到
2.4 coverage-mechinism
追踪前面已经用过的词:累加当前词在各个step上的attention得分,得到coverage vector:
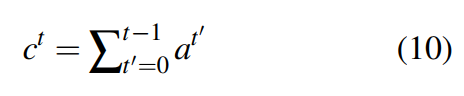
(可以视为pointer的选词重复性)
作为罚项加进损失函数:
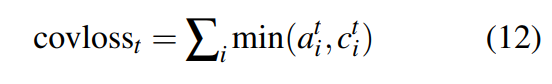
最终总的损失函数为:
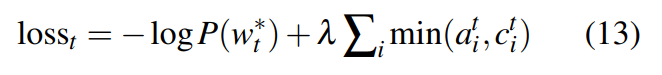
另外也修正generator中计算attention的公式为:
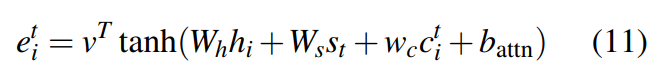
3. 代码复现
官方代码是用Python 2写的。
太古典了,我不可能复现的。
我自己跑通过2份其他人复现的PGN代码,以后补一下怎么实现。
也许有一天我会自己写一份的。One day.