声明
本文在【何宽】的【参考教程】基础上编写,只保留了最主要的一些操作步骤。如需了解更详细的信息和一些原理,还请参考【原文】。
文章目录
摘要
本文将用最简单粗暴的方式,把代码和运行结果甩出来,直观显示【普通梯度下降】、【Momentum】以及【Adam】三种算法的优劣。
资源获取
首先,你需要在你代码文件所在的目录下添加三个文件:【dnn_utils.py】、【testCase.py】、【opt_utils.py】。我把这三个文件的代码放到文章结尾,不怕麻烦的小伙伴也可以直接从【我的网盘,密码:rska】下载解压后拖到你们的目录下~
导入库
新建一个.py文件。因为我们这次用到的数据集是两个同心圆环,我就把它命名成circle.py啦,你们随意~新建好之后就开始添加下面的代码叭!
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import scipy.io
import math
import sklearn
import sklearn.datasets
import opt_utils
import testCase
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
普通梯度下降算法
def update_parameters_with_gd(parameters,grads,learning_rate):
L = len(parameters) // 2 #神经网络的层数
#更新每个参数
for l in range(L):
parameters["W" + str(l +1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)]
parameters["b" + str(l +1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)]
return parameters
Momentum算法
def initialize_velocity(parameters):
L = len(parameters) // 2 #神经网络的层数
v = {}
for l in range(L):
v["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
v["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
return v
def update_parameters_with_momentun(parameters,grads,v,beta,learning_rate):
L = len(parameters) // 2
for l in range(L):
#计算速度
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads["dW" + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads["db" + str(l + 1)]
#更新参数
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return parameters,v
Adam算法
def initialize_adam(parameters):
L = len(parameters) // 2
v = {}
s = {}
for l in range(L):
v["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
v["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
s["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
s["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
return (v,s)
def update_parameters_with_adam(parameters,grads,v,s,t,learning_rate=0.01,beta1=0.9,beta2=0.999,epsilon=1e-8):
L = len(parameters) // 2
v_corrected = {} #偏差修正后的值
s_corrected = {} #偏差修正后的值
for l in range(L):
#梯度的移动平均值,输入:"v , grads , beta1",输出:" v "
v["dW" + str(l + 1)] = beta1 * v["dW" + str(l + 1)] + (1 - beta1) * grads["dW" + str(l + 1)]
v["db" + str(l + 1)] = beta1 * v["db" + str(l + 1)] + (1 - beta1) * grads["db" + str(l + 1)]
#计算第一阶段的偏差修正后的估计值,输入"v , beta1 , t" , 输出:"v_corrected"
v_corrected["dW" + str(l + 1)] = v["dW" + str(l + 1)] / (1 - np.power(beta1,t))
v_corrected["db" + str(l + 1)] = v["db" + str(l + 1)] / (1 - np.power(beta1,t))
#计算平方梯度的移动平均值,输入:"s, grads , beta2",输出:"s"
s["dW" + str(l + 1)] = beta2 * s["dW" + str(l + 1)] + (1 - beta2) * np.square(grads["dW" + str(l + 1)])
s["db" + str(l + 1)] = beta2 * s["db" + str(l + 1)] + (1 - beta2) * np.square(grads["db" + str(l + 1)])
#计算第二阶段的偏差修正后的估计值,输入:"s , beta2 , t",输出:"s_corrected"
s_corrected["dW" + str(l + 1)] = s["dW" + str(l + 1)] / (1 - np.power(beta2,t))
s_corrected["db" + str(l + 1)] = s["db" + str(l + 1)] / (1 - np.power(beta2,t))
#更新参数,输入: "parameters, learning_rate, v_corrected, s_corrected, epsilon". 输出: "parameters".
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * (v_corrected["dW" + str(l + 1)] / np.sqrt(s_corrected["dW" + str(l + 1)] + epsilon))
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * (v_corrected["db" + str(l + 1)] / np.sqrt(s_corrected["db" + str(l + 1)] + epsilon))
return (parameters,v,s)
用mini_batch加快训练速度
其实这个数据集样本量不大,没必要用mini_batch,这里用了就是想给你们参考下代码怎么写(我只是个没感情的代码搬运工)= =
扫描二维码关注公众号,回复:
9636073 查看本文章

def random_mini_batches(X,Y,mini_batch_size=64,seed=0):
np.random.seed(seed) #指定随机种子
m = X.shape[1]
mini_batches = []
#第一步:打乱顺序
permutation = list(np.random.permutation(m)) #它会返回一个长度为m的随机数组,且里面的数是0到m-1
shuffled_X = X[:,permutation] #将每一列的数据按permutation的顺序来重新排列。
shuffled_Y = Y[:,permutation].reshape((1,m))
#第二步,分割
num_complete_minibatches = math.floor(m / mini_batch_size) #把你的训练集分割成多少份,请注意,如果值是99.99,那么返回值是99,剩下的0.99会被舍弃
for k in range(0,num_complete_minibatches):
mini_batch_X = shuffled_X[:,k * mini_batch_size:(k+1)*mini_batch_size]
mini_batch_Y = shuffled_Y[:,k * mini_batch_size:(k+1)*mini_batch_size]
mini_batch = (mini_batch_X,mini_batch_Y)
mini_batches.append(mini_batch)
#如果训练集的大小刚好是mini_batch_size的整数倍,那么这里已经处理完了
#如果训练集的大小不是mini_batch_size的整数倍,那么最后肯定会剩下一些,我们要把它处理了
if m % mini_batch_size != 0:
#获取最后剩余的部分
mini_batch_X = shuffled_X[:,mini_batch_size * num_complete_minibatches:]
mini_batch_Y = shuffled_Y[:,mini_batch_size * num_complete_minibatches:]
mini_batch = (mini_batch_X,mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
模型函数
def model(X,Y,layers_dims,optimizer,learning_rate=0.005,
mini_batch_size=512,beta=0.9,beta1=0.9,beta2=0.999,
epsilon=1e-8,num_epochs=1000,print_cost=True,is_plot=True):
L = len(layers_dims)
costs = []
t = 0 #每学习完一个minibatch就增加1
seed = 10 #随机种子
#初始化参数
parameters = opt_utils.initialize_parameters(layers_dims)
#选择优化器
if optimizer == "gd":
pass #不使用任何优化器,直接使用梯度下降法
elif optimizer == "momentum":
v = initialize_velocity(parameters) #使用动量
elif optimizer == "adam":
v, s = initialize_adam(parameters)#使用Adam优化
else:
print("optimizer参数错误,程序退出。")
exit(1)
#开始学习
for i in range(num_epochs):
#定义随机 minibatches,我们在每次遍历数据集之后增加种子以重新排列数据集,使每次数据的顺序都不同
seed = seed + 1
minibatches = random_mini_batches(X,Y,mini_batch_size,seed)
for minibatch in minibatches:
#选择一个minibatch
(minibatch_X,minibatch_Y) = minibatch
#前向传播
AL , cache = opt_utils.forward_propagation(minibatch_X,parameters)
#计算误差
cost = opt_utils.compute_cost(AL , minibatch_Y)
#反向传播
grads = opt_utils.backward_propagation(AL,minibatch_Y,cache)
#更新参数
if optimizer == "gd":
parameters = update_parameters_with_gd(parameters,grads,learning_rate)
elif optimizer == "momentum":
parameters, v = update_parameters_with_momentun(parameters,grads,v,beta,learning_rate)
elif optimizer == "adam":
t = t + 1
parameters , v , s = update_parameters_with_adam(parameters,grads,v,s,t,learning_rate,beta1,beta2,epsilon)
#记录误差值
if i % 100 == 0:
costs.append(cost)
#是否打印误差值
if print_cost:
print("第" + str(i) + "次遍历整个数据集,当前误差值:" + str(cost))
#是否绘制曲线图
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('epochs (per 100)')
plt.title("Learning rate = " + str(learning_rate))
plt.show()
return parameters
加载数据集
train_X, train_Y,test_X,test_Y = opt_utils.load_dataset(is_plot=False)
#plt.show()
设置超参数并训练
layers_dims = [train_X.shape[0],15,10,8 ,5,1]
分别用三种算法预测并绘制结果
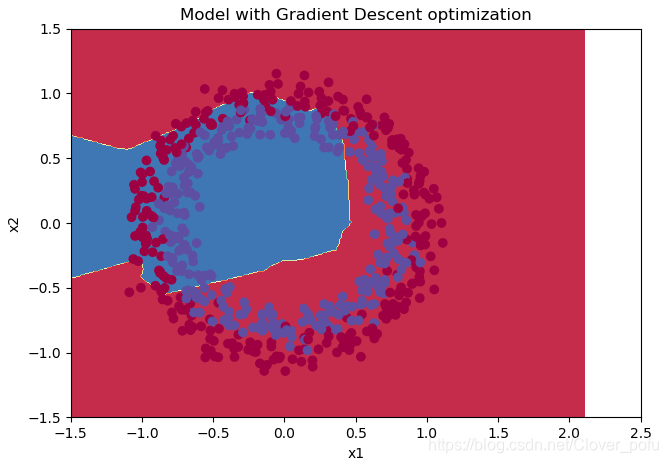
普通梯度下降
#使用普通的梯度下降
parameters = model(train_X, train_Y, layers_dims, optimizer="gd",is_plot=True)
#预测
preditions = opt_utils.predict(test_X,test_Y,parameters)
#绘制分类图
plt.title("Model with Gradient Descent optimization")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1.5, 1.5])
opt_utils.plot_decision_boundary(lambda x: opt_utils.predict_dec(parameters, x.T), test_X, test_Y)
第0次遍历整个数据集,当前误差值:0.7180083824291795
第100次遍历整个数据集,当前误差值:0.6975677064039587
第200次遍历整个数据集,当前误差值:0.6979503500898198
第300次遍历整个数据集,当前误差值:0.6968021578413177
第400次遍历整个数据集,当前误差值:0.6936001758617135
第500次遍历整个数据集,当前误差值:0.6918083441240396
第600次遍历整个数据集,当前误差值:0.6912998027169326
第700次遍历整个数据集,当前误差值:0.6908476652716707
第800次遍历整个数据集,当前误差值:0.6914641297374514
第900次遍历整个数据集,当前误差值:0.6912985667418147
准确度为: 0.5783333333333334
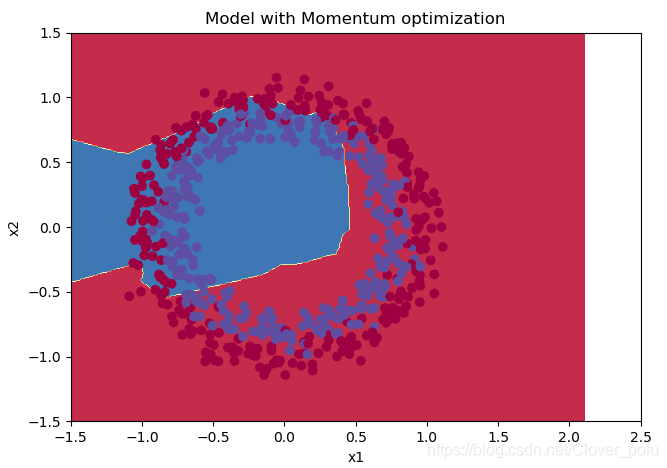
Momentum
#使用动量的梯度下降
parameters = model(train_X, train_Y, layers_dims, beta=0.9,optimizer="momentum",is_plot=False)
#预测
preditions = opt_utils.predict(test_X,test_Y,parameters)
#绘制分类图
plt.title("Model with Momentum optimization")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1.5, 1.5])
opt_utils.plot_decision_boundary(lambda x: opt_utils.predict_dec(parameters, x.T), test_X, test_Y)
第0次遍历整个数据集,当前误差值:0.7185230541978586
第100次遍历整个数据集,当前误差值:0.6975559293094252
第200次遍历整个数据集,当前误差值:0.6978993591969807
第300次遍历整个数据集,当前误差值:0.6968238909519463
第400次遍历整个数据集,当前误差值:0.6936050163600433
第500次遍历整个数据集,当前误差值:0.6918339124188917
第600次遍历整个数据集,当前误差值:0.6913186974582367
第700次遍历整个数据集,当前误差值:0.690866110646283
第800次遍历整个数据集,当前误差值:0.6914781211918172
第900次遍历整个数据集,当前误差值:0.6913184289623246
准确度为: 0.5783333333333334
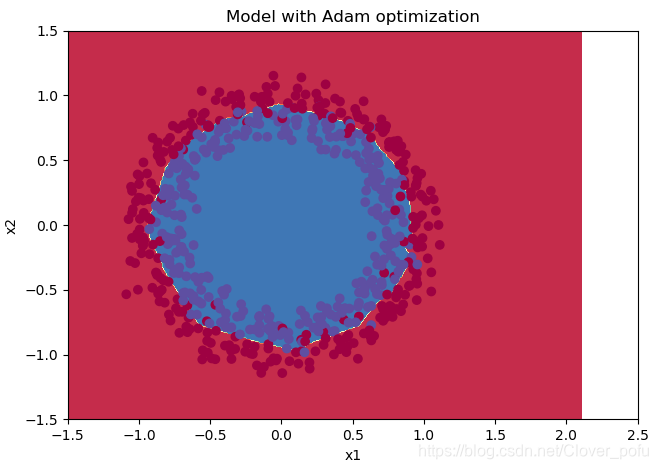
Adam
#使用Adam优化的梯度下降
parameters = model(train_X, train_Y, layers_dims, optimizer="adam",is_plot=False)
#预测
preditions = opt_utils.predict(train_X,train_Y,parameters)
#绘制分类图
plt.title("Model with Adam optimization")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1.5, 1.5])
opt_utils.plot_decision_boundary(lambda x: opt_utils.predict_dec(parameters, x.T), test_X, test_Y)
第0次遍历整个数据集,当前误差值:0.703480218810302
第100次遍历整个数据集,当前误差值:0.22226606286901093
第200次遍历整个数据集,当前误差值:0.2494787640233252
第300次遍历整个数据集,当前误差值:0.2721591577217877
第400次遍历整个数据集,当前误差值:0.25388188117059834
第500次遍历整个数据集,当前误差值:0.2038311727376155
第600次遍历整个数据集,当前误差值:0.25018907769067406
第700次遍历整个数据集,当前误差值:0.21005080975158016
第800次遍历整个数据集,当前误差值:0.21618755738108947
第900次遍历整个数据集,当前误差值:0.24759254182859308
准确度为: 0.9233333333333333
总结
- Adam的优越性还是很明显的,在同样的epoch下,同样的学习率,训练后测试集准确率比另两个高得多,不愧是种子选手。
- 至于Momentum…我尝试换了不同数据集,调整各种超参数(包括学习率、网络层数、节点数),操碎了心,就是希望它能在普通梯度下降面前表现出优越性,登上太子之位。结果!它竟然和普通梯度下降没啥区别(缓缓打出一个?)
- 总而言之,训练就到此结束嘞,如果哪位大佬有便捷的办法区分出【普通梯度下降】and【Momentum】,求赐教昂昂昂昂~~
dnn_utils.py
import numpy as np
def sigmoid(Z):
A = 1/(1+np.exp(-Z))
cache = Z
return A, cache
def sigmoid_backward(dA, cache):
Z = cache
s = 1/(1+np.exp(-Z))
dZ = dA * s * (1-s)
assert (dZ.shape == Z.shape)
return dZ
def relu(Z):
A = np.maximum(0,Z)
assert(A.shape == Z.shape)
cache = Z
return A, cache
def relu_backward(dA, cache):
Z = cache
dZ = np.array(dA, copy=True) # just converting dz to a correct object.
# When z <= 0, you should set dz to 0 as well.
dZ[Z <= 0] = 0
assert (dZ.shape == Z.shape)
return dZ
testCase.py
# -*- coding: utf-8 -*-
#testCase.py
import numpy as np
def update_parameters_with_gd_test_case():
np.random.seed(1)
learning_rate = 0.01
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
dW1 = np.random.randn(2,3)
db1 = np.random.randn(2,1)
dW2 = np.random.randn(3,3)
db2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
return parameters, grads, learning_rate
"""
def update_parameters_with_sgd_checker(function, inputs, outputs):
if function(inputs) == outputs:
print("Correct")
else:
print("Incorrect")
"""
def random_mini_batches_test_case():
np.random.seed(1)
mini_batch_size = 64
X = np.random.randn(12288, 148)
Y = np.random.randn(1, 148) < 0.5
return X, Y, mini_batch_size
def initialize_velocity_test_case():
np.random.seed(1)
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
def update_parameters_with_momentum_test_case():
np.random.seed(1)
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
dW1 = np.random.randn(2,3)
db1 = np.random.randn(2,1)
dW2 = np.random.randn(3,3)
db2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
v = {'dW1': np.array([[ 0., 0., 0.],
[ 0., 0., 0.]]), 'dW2': np.array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]]), 'db1': np.array([[ 0.],
[ 0.]]), 'db2': np.array([[ 0.],
[ 0.],
[ 0.]])}
return parameters, grads, v
def initialize_adam_test_case():
np.random.seed(1)
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
def update_parameters_with_adam_test_case():
np.random.seed(1)
v, s = ({'dW1': np.array([[ 0., 0., 0.],
[ 0., 0., 0.]]), 'dW2': np.array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]]), 'db1': np.array([[ 0.],
[ 0.]]), 'db2': np.array([[ 0.],
[ 0.],
[ 0.]])}, {'dW1': np.array([[ 0., 0., 0.],
[ 0., 0., 0.]]), 'dW2': np.array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]]), 'db1': np.array([[ 0.],
[ 0.]]), 'db2': np.array([[ 0.],
[ 0.],
[ 0.]])})
W1 = np.random.randn(2,3)
b1 = np.random.randn(2,1)
W2 = np.random.randn(3,3)
b2 = np.random.randn(3,1)
dW1 = np.random.randn(2,3)
db1 = np.random.randn(2,1)
dW2 = np.random.randn(3,3)
db2 = np.random.randn(3,1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
return parameters, grads, v, s
opt_utils.py
# -*- coding: utf-8 -*-
#opt_utils.py
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
from dnn_utils import sigmoid,sigmoid_backward,relu,relu_backward
def initialize_parameters(layer_dims):
np.random.seed(7)
parameters = {}
L = len(layer_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1])* np.sqrt(2 / layer_dims[l-1])
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters
#计算节点激活之后的输出
def linear_activation_forward(A_prev,W,b,activation):
Z=np.dot(W,A_prev)+b
assert(Z.shape==(W.shape[0],A_prev.shape[1]))
linear_cache=(A_prev,W,b)
if activation=="sigmoid":
A,activation_cache=sigmoid(Z)
elif activation=="relu":
A,activation_cache=relu(Z)
assert(A.shape==(W.shape[0],A_prev.shape[1]))
cache=(linear_cache,activation_cache)
return A,cache
#隐藏层用relu,输出层用sigmoid
def forward_propagation(X,parameters):
caches=[]
A=X
L=len(parameters)//2
for l in range(1,L):
A_prev=A
A,cache=linear_activation_forward(A_prev,parameters['W'+str(l)],parameters['b'+str(l)],"relu")
caches.append(cache)
AL,cache=linear_activation_forward(A,parameters['W'+str(L)],parameters['b'+str(L)],"sigmoid")
caches.append(cache)
assert(AL.shape==(1,X.shape[1]))
return AL,caches
#计算反向传播
def linear_backward(dZ,cache):
A_prev,W,b=cache
m=A_prev.shape[1]
dW=np.dot(dZ,A_prev.T)/m
db=np.sum(dZ,axis=1,keepdims=True)/m
dA_prev=np.dot(W.T,dZ)
assert(dA_prev.shape==A_prev.shape)
assert(dW.shape==W.shape)
assert(db.shape==b.shape)
return dA_prev, dW, db
def linear_activation_backward(dA,cache,activation="relu"):
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev,dW,db
#计算损失
def compute_cost(AL,Y):
m=Y.shape[1]
cost=-np.sum(np.multiply(np.log(AL),Y)+np.multiply(np.log(1-AL),1-Y))/m
cost=np.squeeze(cost)
assert(cost.shape==())
return cost
#反向传播
def backward_propagation(AL,Y,caches):
grads = {}
L = len(caches)
m = AL.shape[1]
Y = Y.reshape(AL.shape)
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))
current_cache = caches[L-1]
grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, "sigmoid")
for l in reversed(range(L-1)):
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA" + str(l + 2)], current_cache, "relu")
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
#预测函数
def predict(X, y, parameters):
m = X.shape[1]
n = len(parameters) // 2 # 神经网络的层数
p = np.zeros((1,m))
#根据参数前向传播
probas, caches = forward_propagation(X, parameters)
for i in range(0, probas.shape[1]):
if probas[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
print("准确度为: " + str(float(np.sum((p == y))/m)))
return p
#预测
def predict_dec(parameters, X):
# Predict using forward propagation and a classification threshold of 0.5
a3, cache = forward_propagation(X, parameters)
predictions = (a3 > 0.5)
return predictions
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=np.squeeze(y), cmap=plt.cm.Spectral)
plt.show()
def load_dataset(is_plot=True):
np.random.seed(1)
train_X, train_Y = sklearn.datasets.make_circles(n_samples=1400, noise=.08)
np.random.seed(2)
test_X, test_Y = sklearn.datasets.make_circles(n_samples=600, noise=.08)
# Visualize the data
if is_plot:
plt.scatter(train_X[:, 0], train_X[:, 1], c=np.squeeze(train_Y), s=40, cmap=plt.cm.Spectral);
train_X = train_X.T
train_Y = train_Y.reshape((1, train_Y.shape[0]))
test_X = test_X.T
test_Y = test_Y.reshape((1, test_Y.shape[0]))
return train_X, train_Y, test_X, test_Y
