吴恩达深度学习第二课知识总结(一)
仅供自己记录整理
1.1 训练,验证,测试
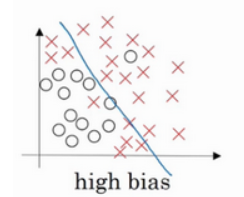
1.2 偏差,方差
偏差:欠拟合
训练集错误率50%,验证集错误率50%
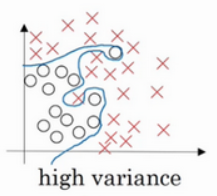
方差:过拟合
训练集错误率1%,验证集错误率50%
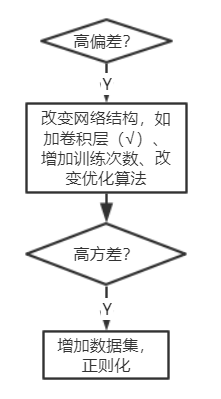
1.3 机器学习基础
训练神经网络的方法:
1.4 正则化——L2正则化
L2正则化:
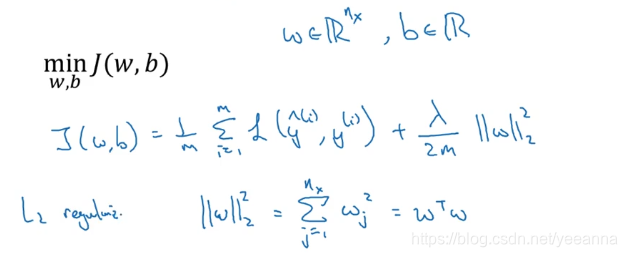 其中lamata是正则化参数,通过调整lamata避免过拟合。
其中lamata是正则化参数,通过调整lamata避免过拟合。
神经网络中的正则化:
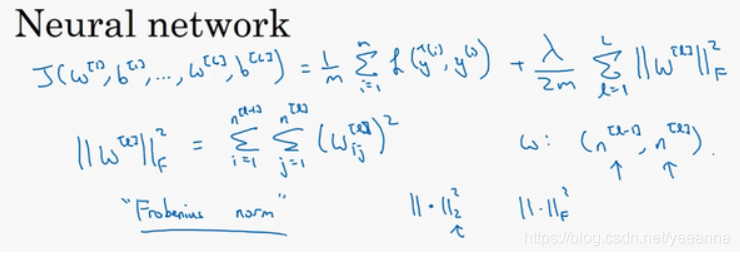
如何使用该范数实现梯度下降:
 此时的L2范数相当于权重衰减。
此时的L2范数相当于权重衰减。
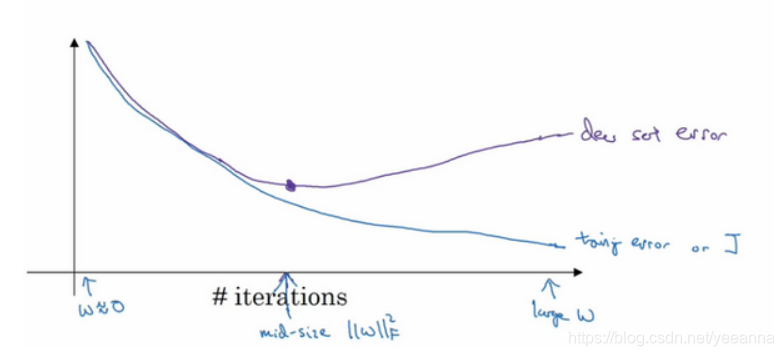
1.5 为什么正则化可以防止过拟合?
不用知道原因,想知道去看视频:https://www.bilibili.com/video/BV1V441127zE?p=5
lamata足够大的话w就可以取很小,w趋近于零的话深层网络的复杂结构就都没了,只剩下一条网络,可以防止过拟合
1.6 正则化——dropout正则化
这个之前已经理解过了,就是随机失活一部分神经元。
注意一点,失活后要将该层的参数除以失活概率,比如失活后保留80%的神经元,就要将w·x/80%,以保证随机失活后均值不变。
注:测试阶段不使用dropout,因为测试阶段是想要根据训练得到的参数权重输出一个尽可能准确的值,并不希望输出结果随机。
1.7为什么dropout起作用
与L2正则化类似。
两种dropout方法:
(1)易于过拟合的层设置失活率更高。缺点:需要更多参数
(2)某些层用dropout,某些层不用。
dropout的缺点:无法确定代价函数J,无法确定损失函数是否收敛。=>所以可以先关闭dropout,确保损失收敛后再打开。
1.8 其他正则化方法
- 数据扩增
- early stoping:即过早停止训练
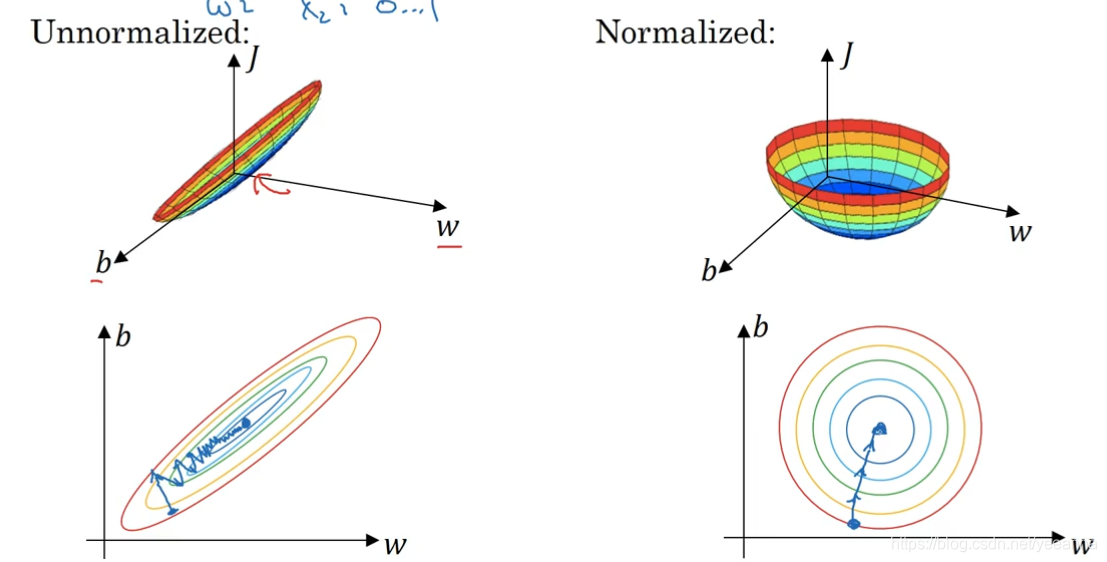
1.9 归一化输入
(1)零均值
(2)归一化方差
=> x’=(x-u)/sigma(类似正态分布的标准化)
x’~均值为0,方差为1。
归一化的原因:可以更快地找到最小损失。损失函数优化更快。
1.10 梯度爆炸和梯度消失
由于参数太多,如果所有参数都大于1,相乘会变成指数级增长,导致最终结果很大趋于∞->梯度爆炸
所有参数都小于1,相乘会指数级减小,结果趋于0->梯度消失
1.11 权重初始化——解决梯度消失爆炸的方法之一
用如下公式初始化参数w:
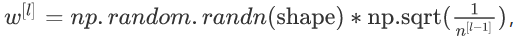
其中n是l-1层的神经元数量。(我的理解是:因为l层有n个参数w,所以乘一个1/n较为合理)这是对于用tanh函数的公式。
若用ReLU激活,视频中建议用:
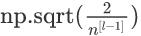
但是相对于其他的优化方法,初始化没那么重要。
1.12 梯度
双边梯度比单边梯度更精确。
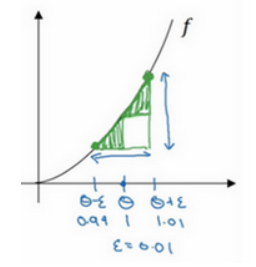
1.13 梯度检验——用于检验反向传播是否正确
算向量的近似值差值的二范数再除以两个向量二范数和(公式如图),值很小说明没有问题。
注:
(1)只在调试过程中检验,不要在训练过程中检验。因为它太消耗计算量了。
(2)一旦结果相差很大,需要调试看究竟哪步的计算结果大。
(3)别忘了正则化。需计算正则化项。
(4)梯度检验不能与dropout同时使用(因为dropout是随机的,无法计算梯度)
