吴恩达第2课第2周编程习题
目标:使用mini—batch来加快学习速度;比较梯度下降,momentum,adam的效果
核心:指数加权平均值得计算及其意义,它是momentum,RMSProp,Adam算法的基石
不足:本例程没有使用学习率衰减的步骤,同时本例程只适于3层的二分法的神经网络
常记点:
1. 偏差修正时是除以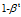 ,此处是-,t从1开始;
,此处是-,t从1开始;
2. L=len(parameters) //2 ,这个L不等于网络层数,range(1,L+1)=range(1,len(layers_dims))
3. Adam算法求s时,需要平方(np.square),便于后面分母除根号(np.sqrt)
4. np.random.permutation(m),把range(m)重排列,用于把样本打乱,每一代都要打乱一次
5. arr[:,:]:逗号前面表示行的选取,后面表示列的选取
-
'''''
-
本例程需要做几个优化对比
-
不写出整个深度学习网络了
-
1.不做任何优化
-
2.mini-batch
-
3.momentum
-
4.Adam
-
'''
-
import numpy as np
-
import matplotlib.pyplot as plt
-
import scipy.io
-
import math
-
import sklearn
-
import sklearn.datasets
-
-
import opt_utils
-
import testCases
-
-
plt.rcParams['figure.figsize']=(7.0,4.0)
-
plt.rcParams['image.interpolation']='nearest'
-
plt.rcParams['image.cmap']='gray'
-
-
#不适用任何优化,梯度下降更新参数
-
-
def update_parameters_gd(parameters,grads,learning_rate):
-
L=len(parameters)//2 #parameters是一个字典,储存了W,b
-
for l in range(1,L+1):#L要加1是因为这个L并不指的是层数了
-
parameters['W'+str(l)]=parameters['W'+str(l)]-learning_rate*grads['dW'+str(l)]
-
parameters['b'+str(l)]=parameters['b'+str(l)]-learning_rate*grads['db'+str(l)]
-
-
return parameters
-
'''''
-
mini-batch
-
'''
-
# 把样本随机,然后分割
-
def mini_batches(X,Y,mini_batch_size=64,seed=0):
-
np.random.seed(seed)
-
m=X.shape[1]
-
mini_batches=[]
-
indexs=np.random.permutation(m)
-
X_random=X[:,indexs]
-
Y_random=Y[:,indexs].reshape(1,m)
-
T=m // mini_batch_size
-
for k in range(T):
-
X_mini=X_random[:,k*mini_batch_size:(k+1)*mini_batch_size]
-
Y_mini=Y_random[:,k*mini_batch_size:(k+1)*mini_batch_size]
-
-
mini_batch=(X_mini,Y_mini)
-
mini_batches.append(mini_batch)
-
#如果没有整除掉,那么还会剩余一次,但数据大小不会是mini_batch_size
-
if m % mini_batch_size:
-
X_mini=X_random[:,T*mini_batch_size:]
-
Y_mini=Y_random[:,T*mini_batch_size:]
-
mini_batch=(X_mini,Y_mini)
-
mini_batches.append(mini_batch)
-
return mini_batches
-
-
'''''
-
使用momentum
-
'''
-
#初始化v
-
def initialize_v(parameters):
-
v={}
-
L=len(parameters) //2
-
for l in range(1,L+1):
-
v['dW'+str(l)]=np.zeros_like(parameters['W'+str(l)])
-
v['db'+str(l)]=np.zeros_like(parameters['b'+str(l)])
-
return v
-
-
#更新参数
-
def update_parameters_momentum(parameters,grads,v,beta,learning_rate):
-
L=len(parameters) //2
-
for l in range(1,L+1):
-
v['dW'+str(l)]=beta*v['dW'+str(l)]+(1-beta)*grads['dW'+str(l)]
-
v['db'+str(l)]=beta*v['db'+str(l)]+(1-beta)*grads['db'+str(l)]
-
-
parameters['W'+str(l)]=parameters['W'+str(l)]-learning_rate*v['dW'+str(l)]
-
parameters['b'+str(l)]=parameters['b'+str(l)]-learning_rate*v['db'+str(l)]
-
-
return parameters ,v
-
-
'''''
-
Adam算法
-
'''
-
#初始化v以及s
-
def initialize_adam(parameters):
-
L=len(parameters) //2
-
v,s={},{}
-
for l in range(1,L+1):
-
v['dW'+str(l)]=np.zeros_like(parameters['W'+str(l)])
-
v['db'+str(l)]=np.zeros_like(parameters['b'+str(l)])
-
-
s['dW'+str(l)]=np.zeros_like(parameters['W'+str(l)])
-
s['db'+str(l)]=np.zeros_like(parameters['b'+str(l)])
-
return v,s
-
-
#更新参数
-
def update_parameters_adam(parameters,grads,v,s,t,learning_rate=0.01,beta1=0.9,beta2=0.999,epsilon=1e-8):
-
#t,遍历数据集的次数
-
L=len(parameters) //2
-
v_corrected,s_corrected={},{}
-
for l in range(1,L+1):
-
#梯度指数加权平均
-
v['dW'+str(l)]=beta1*v['dW'+str(l)]+(1-beta1)*grads['dW'+str(l)]
-
v['db'+str(l)]=beta1*v['db'+str(l)]+(1-beta1)*grads['db'+str(l)]
-
#偏差修正
-
v_corrected['dW'+str(l)]=v['dW'+str(l)]/(1-np.power(beta1,t))
-
v_corrected['db'+str(l)]=v['db'+str(l)]/(1-np.power(beta1,t))
-
#梯度指数加权平均
-
-
s['dW'+str(l)]=beta2*s['dW'+str(l)]+(1-beta2)*np.square(grads['dW'+str(l)])
-
s['db'+str(l)]=beta2*s['db'+str(l)]+(1-beta2)*np.square(grads['db'+str(l)])
-
#偏差修正
-
s_corrected['dW'+str(l)]=s['dW'+str(l)]/(1-np.power(beta2,t))
-
s_corrected['db'+str(l)]=s['db'+str(l)]/(1-np.power(beta2,t))
-
-
parameters['W'+str(l)]=parameters['W'+str(l)]-learning_rate*(v_corrected['dW'+str(l)]/np.sqrt(s_corrected['dW'+str(l)]+epsilon))
-
parameters['b'+str(l)]=parameters['b'+str(l)]-learning_rate*(v_corrected['db'+str(l)]/np.sqrt(s_corrected['db'+str(l)]+epsilon))
-
#分子用v,分母用s,以防s=0,所以s加上epsilon
-
return parameters,v,s
-
-
'''''
-
测试
-
'''
-
train_X, train_Y = opt_utils.load_dataset()
-
-
def model(X,Y,layers_dims,optimizer,learning_rate=0.0007,mini_batch_size=64,beta=0.9,beta1=0.9,beta2=0.999,epsilon=1e-8,
-
num_epochs=10000,print_cost=True,is_plot=True):
-
-
L=len(layers_dims)
-
costs=[]
-
t=0
-
seed=10
-
#初始化param以及v,s
-
parameters=opt_utils.initialize_parameters(layers_dims)
-
if optimizer=='gd':
-
pass
-
elif optimizer=='momentum':
-
v=initialize_v(parameters)
-
elif optimizer=='adam':
-
v,s=initialize_adam(parameters)
-
else:
-
print('optimizer is error')
-
exit(1)
-
#迭代学习
-
for i in range(num_epochs):
-
seed=seed+1
-
minibatches=mini_batches(X,Y,mini_batch_size,seed)
-
#注意此处不能使用mini_batches,如果使用,会造成全局变量使用错误
-
for minibatch in minibatches:
-
mini_batch_X,mini_batch_Y=minibatch #取出mini_batch中储存的X,Y
-
#前向传播
-
A3,cache=opt_utils.forward_propagation(mini_batch_X,parameters)
-
-
#损失函数计算
-
cost=opt_utils.compute_cost(A3,mini_batch_Y)
-
-
#反向传播
-
grads=opt_utils.backward_propagation(mini_batch_X,mini_batch_Y,cache)
-
-
#更新参数
-
if optimizer=='gd':
-
parameters=update_parameters_gd(parameters,grads,learning_rate)
-
elif optimizer=='momentum':
-
parameters,v=update_parameters_momentum(parameters,grads,v,beta,learning_rate)
-
elif optimizer=='adam':
-
t=t+1
-
parameters,v,s=update_parameters_adam(parameters,grads,v,s,t,learning_rate,beta1,beta2,epsilon)
-
-
if i%100==0:
-
costs.append(cost)
-
if print_cost and i%1000==0:
-
print('after iterations of '+str(i)+':'+str(cost))
-
if is_plot:
-
plt.plot(costs)
-
plt.ylabel('cost')
-
plt.xlabel('epoch')
-
plt.title('learning rate:'+str(learning_rate))
-
plt.show()
-
return parameters
-
-
'''''
-
运行代码
-
'''
-
layers_dims = [train_X.shape[0],5,2,1]
-
parameters = model(train_X, train_Y, layers_dims, optimizer="gd",is_plot=True)
-
parameters = model(train_X, train_Y, layers_dims, beta=0.9,optimizer="momentum",is_plot=True)
-
parameters = model(train_X, train_Y, layers_dims, optimizer="adam",is_plot=True)
-
'''''
-
综合比较
-
adam大法好,准确率比另两种高很多
-
'''