一、训练、开发、测试集
1. 可应用的机器学习算法是一个高度迭代的过程,需要不断调整的参数有:层数、隐藏层神经元数、学习速率、激活函数等等。
2. 通常将给定的数据划分为三部分:训练、验证、测试。如果数据集较小:60/20/20, 如果是大数据集(100万条数据以上,验证和测试集各分配1万条即可):98/1/1.
3.如果训练集与验证、测试集来源不同,应保证它们处于同一分布。
二、偏差/方差
1. 模型的偏差和方差要尽可能的综合考虑,在高偏差情况下会出现欠拟合问题,而方差偏高情况会导致过拟合问题。
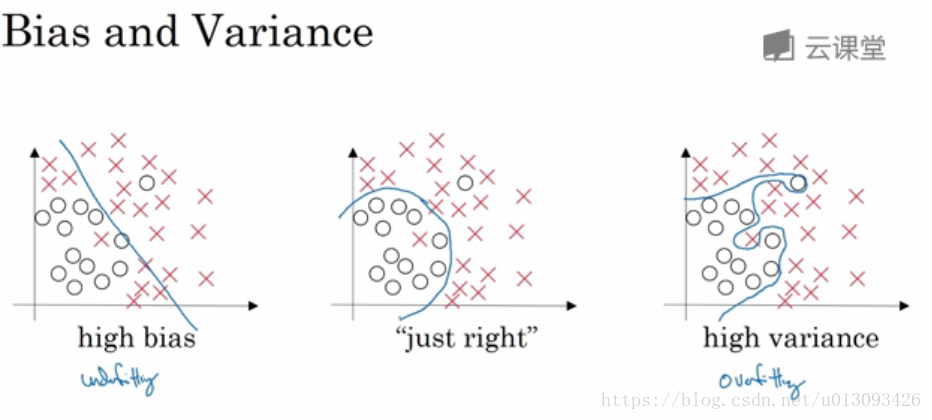
| 高方差(过拟合) | 高偏差 | 高方差和高偏差 | 低方差和低偏差 | |
| 训练集误差 | 1% | 15% | 15% | 0.5% |
| 验证集误差 | 11% | 16% | 30% | 1% |
但是当训练验证集的误差接近最优误差(贝叶斯误差)时,那么也是可以接受的。比如bayers error = 15%,那么上表的第二个案例便是很合理的。
三、机器学习基础
1.由训练集误差和验证集误差判断偏差和方差的大小,以系统的优化算法性能。
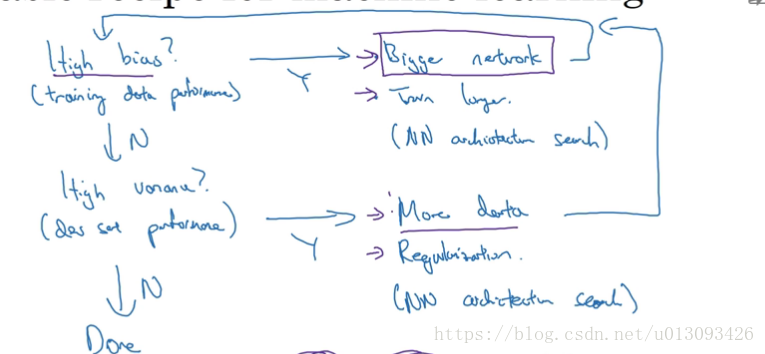
四、正则化
1.遇到高方差问题时首先需想到的是正则化
2.正则化的原理:
(1)对于逻辑回归,L2正则化是最常见的形式。缺点:需要不断的尝试不同的lambd值,导致计算量加大。
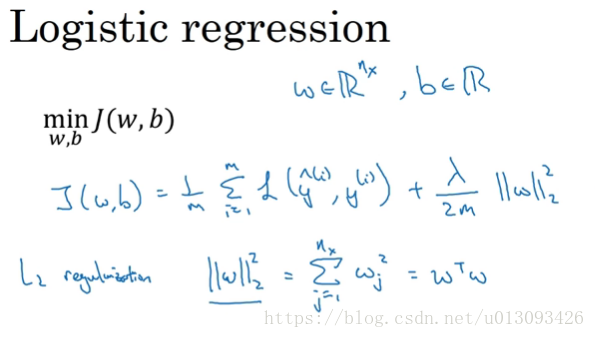
另一种常见的正则化是L1正则化,其通常比较稀疏即包含很多0,形式如下:
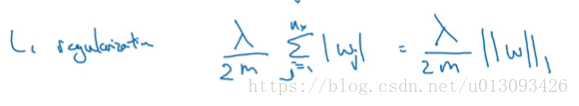
(2)对于神经网络,常采用F范数(弗罗贝尼乌斯范数),其实质也是L2范数。
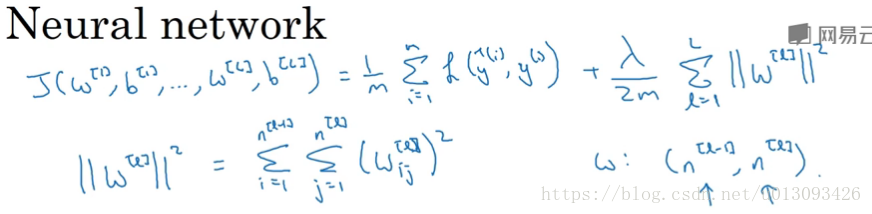
增加的L2范数正则化有时也称之为权重衰减,因为给W[l]引入了一个小于1的权重(1-alpha*lambd/m)

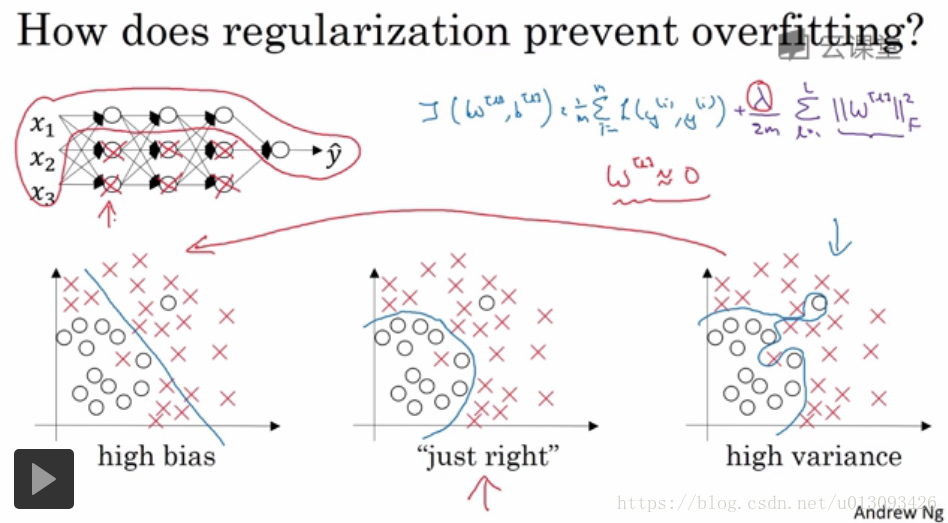
五、为什么正则化有利于防止过拟合(减小方差)
1.直观理解(一):通过正则化引入的lambd可以避免权重过大,甚至可以让W压缩至0,这就可以理解为复杂的神经网络中一些中间层神经元被设置成了0,即变成了逻辑回归模型。
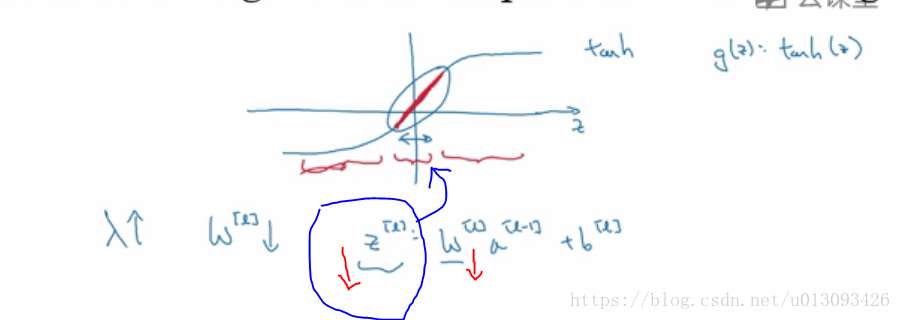
2.直观理解(二),如果Z的取值范围很小,那么相当于深度神经网络的每一层只引入了tanh()的线性部分,这样简化了网络结构,就防止出现过拟合了。
六、dropout正则化(随机失活)
1.dropout处理流程:以掷硬币的方式(0.5的概率)决定每个节点是否被剔除,以达到精简网络结构,这样便可以防止过拟合的发生。
2.实施dropout的方法,最常用的方法是inverted dropout 反向随即失活

3.在预测阶段不要使用dropout
七、理解dropout
1.直观认识:
(1)使用dropout每次迭代后神经网络结构会缩小,这和使用正则化直观感觉类似。
(2)由于dropout是随即的删除某个节点的输入节点,因此在给各个输入节点分配权重时可避免大权重的出现(因为可能在某次迭代中被删掉),这样最终的结果会和L2范数一样起到缩减权重的效果,而且更适用于不用的取值范围。
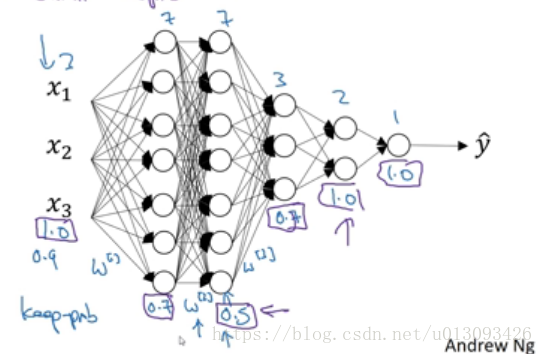
2.不同层可以选择不用大小的keep_prob值,对于复杂的权重Wkeep_prob值应较小,这样可以更加弱化两层之间的拟合。而对于节点很少的层则可不使用dropout(将keep_prob设置为1)
3.在计算机视觉中应用dropout很多,因为很多输入数据且常有无用数据,而在其他场景中应用较少。
4.缺点:cost function不能被明确定义,因为每次随即失活节点。因此在使用时,可以先去除dropout画出J的迭代曲线,运行无误后再加入dropout
八、其他正则化方法
1.扩大数据(水平翻转图像,裁剪,扭曲(如对数字))
2.early stopping(提前结束神经网络的迭代过程),也就是说在dev error和J accuracy满足后就停止下来,这样W就不会被迭代的过于复杂。缺点:正交化很差。因为提早结束训练J(W,b)会使W不够小,这样J就不够小。优点:不需要像L2正则化那样,不断调整超参数lambd,只需要一次梯度下降即可。
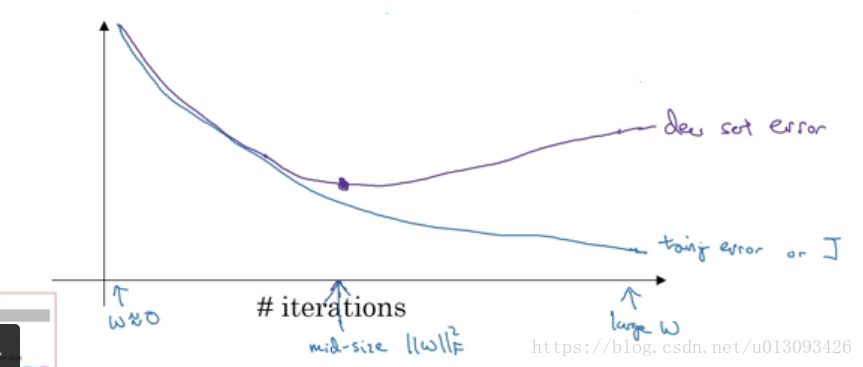
3.神经网络两个关键步骤:(1)优化损失函数J(W,b);(2)防止过拟合(overfitting)
4.正交化:如果处理(1)时的效果不影响(2),在处理(2)时也不影响(1),这个原则称为正交化
九、提升网络训练速度方法一:正则化输入(归一化)
1.步骤:
(1)零均值化:Mu = np.sum(x[i]) / m x[i] -= Mu
(2)归一化方差: sigma**2 = np.sum(x[i] ** 2) / m x[i] /= sigma
2.好处:使输入的各个特征都在同一取值区间,输入更规整,可以使J优化起来更快速找到极值点
十、梯度消失或梯度爆炸
1.梯度消失或梯度爆炸的理解
在深层神经网络中,由于W中的值大于或小于1,导致网络中一些与W[L]相关的函数(J,导数,梯度等)以指数级的速度进行增或减,这样情况称为梯度消失或梯度爆炸,这个给神经网络的训练带来很大困难。
十一、提升网络训练速度方法二:权重初始化
1. 目的:谨慎的选择随即初始化参数,解决梯度消失或梯度爆炸问题
2.实现:
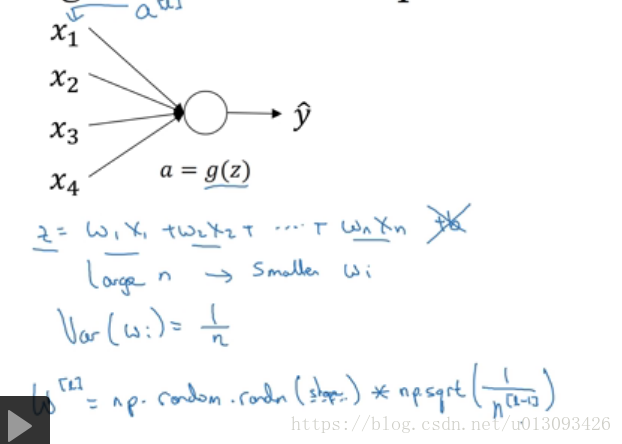
如果激活函数使用的是relu

如果激活函数为tanh
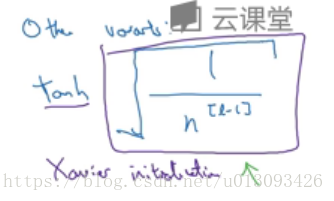
3.改进:
如果想引入方差,则只需在np.sqrt(2/n[l-1])中引入方差系数。
十二、梯度的数值逼近(确保梯度下降正确执行(一))
1.实质:正确实施偏导数计算
十三、梯度检验
1.目的:检验梯度下降是否正确实施

十四、梯度检验实现
1.提示:
(1)不要在训练神经网络时使用梯度检验,这只适用于调试中
(2)如果梯度检验失败,需要检查问题处在哪一层,逐一检查该层的各个组成元素
(3)记得正则化
(4)不能使用dropout(如果算法中使用了dropout,需先关闭且程序运行正确后在梯度检验)