改善深层神经网络之优化算法
一、mini-batch梯度下降法
- 机器学习的应用是一个高度依赖经验的过程,需要大量的迭代,需要训练大量的模型,所以需要优化算法才能快速训练模型。
- 使用mini-batch的意义:当训练样本集非常巨大时,比如500W个,使用向量化处理数据时每次处理如此巨大的数据会使训练过程非常缓慢。因此,我们可以分批的处理数据,以达到加快训练的目的。划分mini-batch后的X(i),Y(i)转化成X{t},Y{t}.
二、理解mini-batch梯度下降法
- 使用mini-batch时,其cost function曲线是一条波动下降的曲线。
- 三种梯度下降法的比较:(1)如果size=m,则是batch梯度下降;(2)如果size=1,则是随即梯度下降法;(3)如果1 < size <m,则是mini-batch梯度下降法。

3.mini-batch大小的选择(超参数)。(1)小训练集(<2000):适合使用batch梯度下降;(2)典型mini-batch的大小为:64, 128, 526, 512,1024(不常用),应与CPU/GPU的内存相匹配。
三、指数加权平均(数学原理)
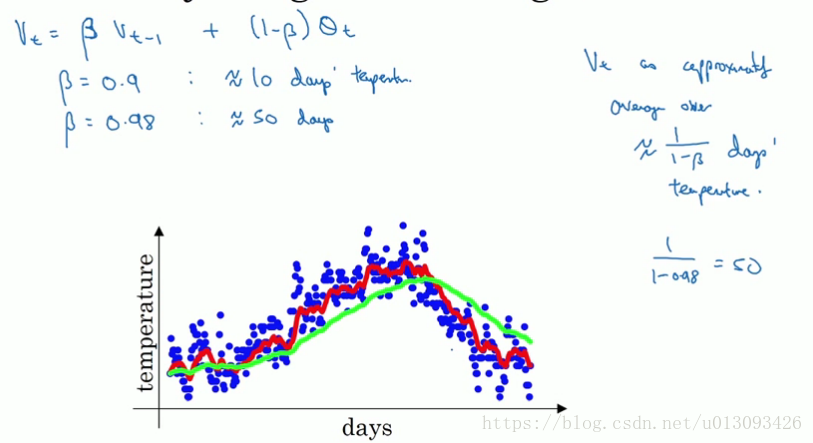
该方法在深层神经网络中主要是用来优化W,b,dW,db等参数?
四、理解指数加权平均
- 计算数据的指数加权平均值目的是使用较小的内存来计算数据的平均值。
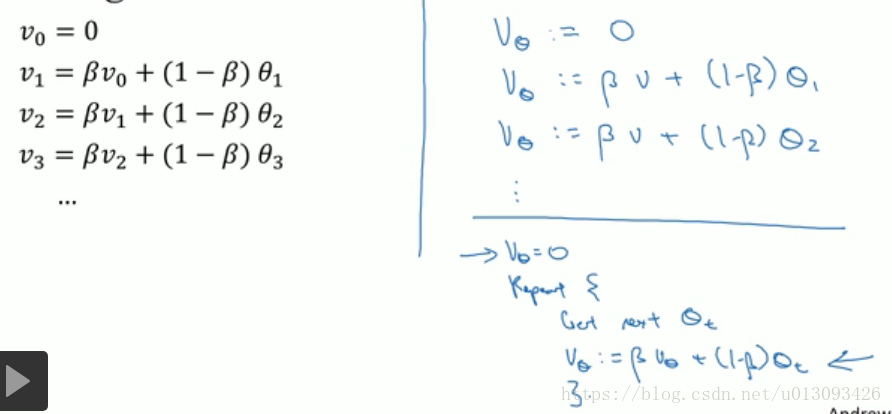
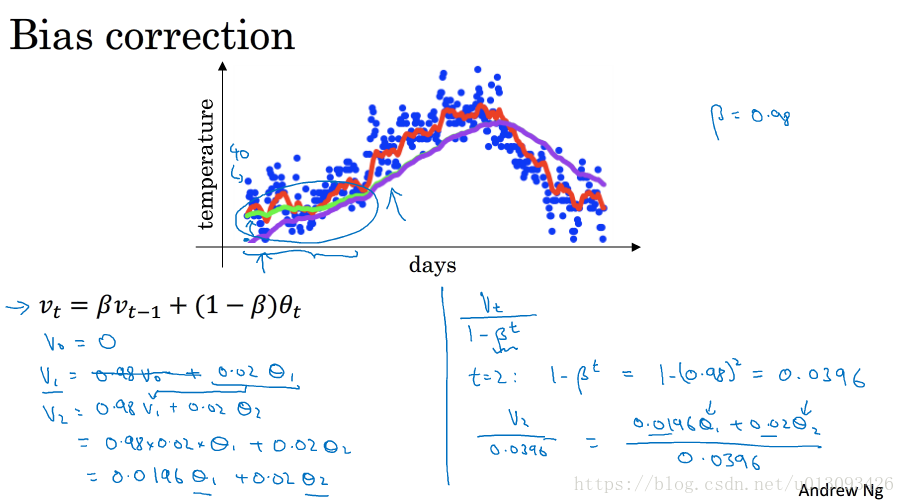
五、指数加权平均的修正偏差
- 修正偏差可以在使用指数加权平均进行学习的早期阶段能够保证估测更准确,方法是让指数加权平均值除以系数(1-beta^t)
六、动量(Momentum)梯度下降法
- 对于碗状曲线要找到极小值,使用梯度下降法时,迭代曲线会经历一个在纵轴上下波动、横轴逐步向最小值逼近的过程,为了优化算法,我们更希望在纵轴上波动减小,这样可以加快逼近的速度,就像从山顶滚落的小球,动量梯度下降法(主要作用是加快梯度下降)使小球在迭代过程中获得一个加速度,跟获得动量类似,这也是该方法名字的由来。
- 在神经网络中,由于迭代次数通常会很大,因此使用momentum时不需要进行偏差修正。

七、RMSprop(Root Mean Square Prop)

八、Adam优化算法
- 本质:Momentum+RMSprop
- 算法中超参的选择:alpha:需要调试;beta1: 0.9(default);beta2:0.999(default);epsilon:10^-8(无关紧要)
- Adam:adaptive moment estimation,其中beta1用于计算dW,称为第一矩(moment 1);beta2用于计算(dW)^2,称为第二矩(moment 2)。

九、学习率衰减
- alpha = alpha_zero * ( 1 / (1 + decay_rate * epoch_num))
- alpha = alpha_zero * 0.95 ^epoch_num
- alpha = alpha_zero * K / np.sqrt(epoch_num )
- alpha = alpha_zero * K / np.sqrt(t ) t: mini-batch number
- 离散学习率,逐次减半
- 学习率确实对算法训练影响很大,但并不是需要最先考虑的优化算法。
十、局部最优问题
- 在高维度的问题中,通常不存在各个维度都是凸或凹的,通常会遇到鞍点(saddle point)
- 我们在训练很大的神经网络时,不需要担心会困在极差的局部最优中,因为有很多维度影响着这个最优点,最终会摆脱出来。
- 问题是如何尽快的走出平稳段(在其中很多维度的导数为0),此时需要应用momentum,RMSprop,Adam算法。