改善神经网络之超参调试、batch正则化和编程框架
一、调试处理
- 超参数:alpha(学习速率),alpha_decay(学习率衰减率),beta(momentum),beta1,beta2,epsilon(Adam),layers(网络层数),hidden_units(隐藏层神经元数),mini_batch_size(mini-bathc的大小)
- 重要等级:一级:alpha;二级:beta、hidden_units、mini_batch_size;三级:layers、alpha_decay;无需调整级:beta1,beta2,epsilon(Adam)
- 参数选择的方法:在早期神经网络选择参数时通常使用网格法,但在深层神经网络中推荐使用由粗到细的随机法,因为我们在选取之前很难准确分析出那一个参数更为重要(举个极端的例子,alpha需要经常调整,但是相对而言epsilon则不需要调整,使用网格法显然不适用。)
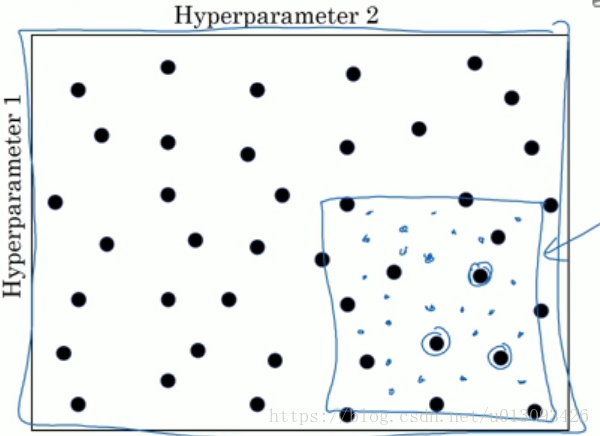
- 在神经网络中,有些参数可以等间距调试,比如:layers,hidden_units等,但alpha这样的参数可能的取值区间跨越的数量级很大,比如:0.0001——1,那么在这个区间等间距选择显然不合理,因此我们自然想到在对数轴上进行等距选择。

三、训练超参数的实践:
- 方式一(Pandas): 由于计算资源有限,长期对一个模型进行优化,直到取得比较好的效果,像照顾熊猫宝宝一样。
- 方式二(Caviar):由于计算能力很强,同时训练多个模型,期望某个可以取得比较好的效果,类似鱼类大量产卵任其自有生长。
四、正则化网络的激活函数
1. batch归一化:在前面的课程中已经验证过归一化特征相对可以加速学习过程,同理对A[l]进行归一化(处理过程中实质是针对Z[l]进行)也会加快对 W[l+1]和b[l+1]的学习,这也正是batch归一化的作用。
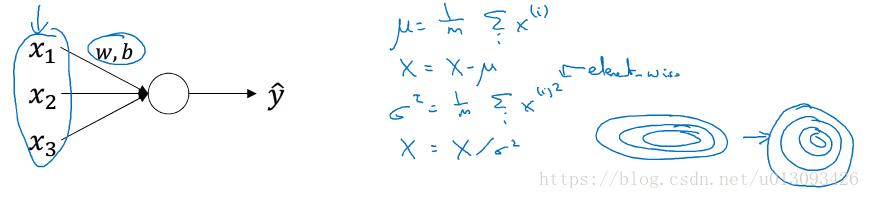
2.batch归一化的实现方法:本质是使隐藏单元值的均值和方差标准化,也就是使Z[i]有固定的均值和方差(可以是0和1,当然也可以是其他值,通过调整Z_tilde中gamma和beta,可以使Z服从不同的分布,从而可以利用激活函数的不同区间段。)

五、将batch归一化拟合进神经网络
1. 算法中使用batch normal会使每一层增加变量gamma[l] 和 beta[l],此时parameters字典中为W[l], b[l], gamma[l] 和 beta[l], 同理grads中为dW[l], db[l], d_gamma[l] 和 d_beta[l],如果在加入Adam、Momentum、RMSprop等算法,在编写代码时需要非常仔细才行,不过由于众多编程框架的开源,比如:tensorflow,我们往往只需要一行代码就可以搞定。tf.nn.batch_normalization()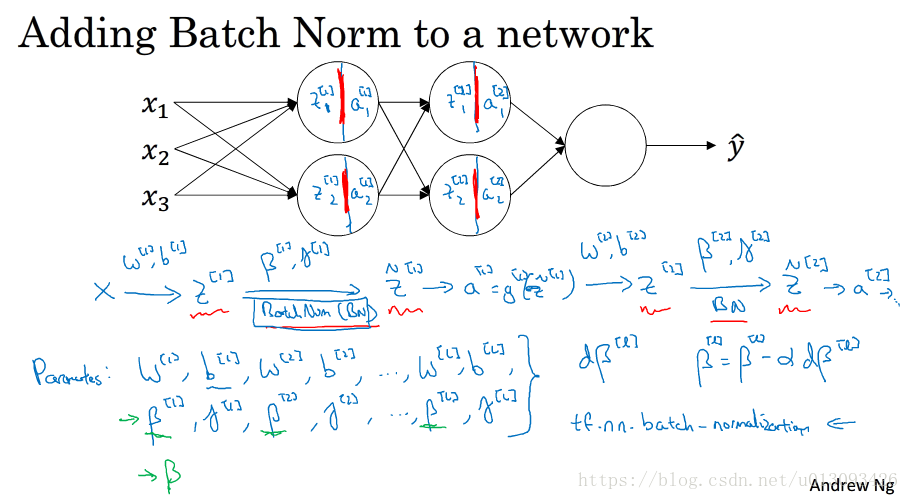
2.batch norm通常和mini-batch一起使用,以mini-batch的形式处理数据。

3.batch norm的梯度下降

六、batch norm为什么奏效?
1.直观解释:(1)是特征输入值和激活函数值各个值都归一化到相同的取值范围。(2)可以使权重比网络更滞后或更深层,就是它可以减弱前层参数的作用与后层参数之间的作用,相当于把该层与后面层次相对独立开来,使得每层可以自己学习,有助于加快网络学习。(3)有一些正则化的效果,因为batch norm是作用在一个batch中,而一个batch的数量是有限的,因此使用一个batch计算出来的均值和方差是有噪音的,这样在向后传递时会迫使得后部单元不会过分的依赖某一个隐藏单元,但由于引入的噪音比较小,因此正则化的效果也是较小的,如果想得到更大的正则化效果,可以和dropout配合使用(注意:随着mini-batch-size的增大,dropout的正则化效果会减弱)。
2.covariate shift (改变数据的分布)如何应用于神经网络:假设有两个不同分布的数据集A,B,使用A训练出来的网络我们不敢奢望对B也非常适用,因此我们可以考虑是否可以对A,B甚至是以后的C,D,E,F都一些处理,使得A-F们能很好的在适用于模型,因此我们使用类似batch norm这样的手段,即使不能保证A,B,C数据不变,但至少我们能保证他们的均值和方差一致,比如为0和1,也就是说减小的输入值的改变程度(从某层往输入方向观察)。

七、测试时的batch norm
1.测试时存在的问题:由于测试时不能够同时对整个测试集中的样本进行测试,通常是一次测试一个样本,这时样本数量少,很难求出一对有效的均值和方差,因此需要使用指数加权平均来根据训练集来进行估算,把每个batch中的均值和方差进行指数加权平均(涵盖所有的batch)作为测试中所需的均值和方差。

八、softmax回归
1.直观理解:在神经网络的输出层使用softmax函数最优激活函数,进行多分类预测。此时输出y_hat是一个(C, 1)的矩阵,其中值为各分类的概率,这与hardmax算法只给数量最大的项赋值为1相对立。
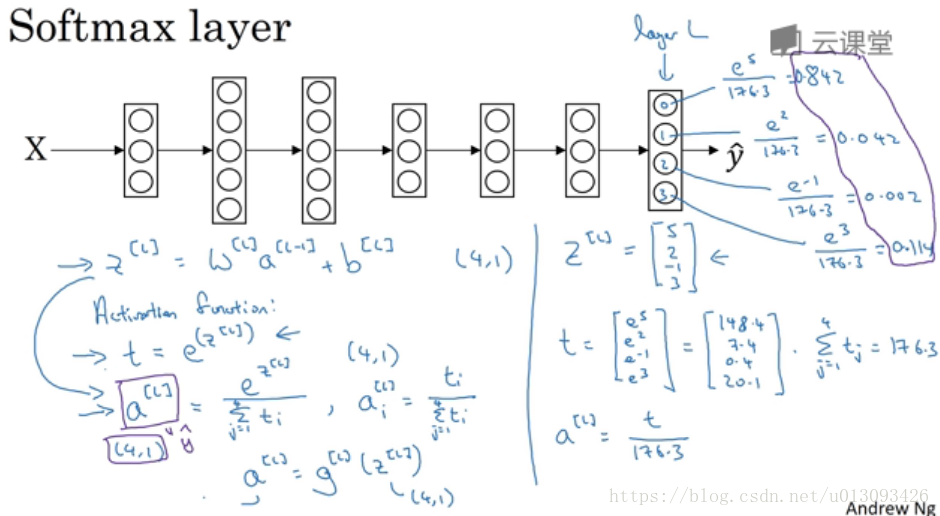
2.为了更好的理解softmax函数,我们去掉深层神经网络的隐藏层,此时softmax层的作用相当于罗辑回归算法,根据输入特征对数据集进行C个分类处理,实质是把逻辑回归二分类推广到C个分类。
1.在将softmax引入神经网络时,基本思路是不便的只是在softmax层输出的y_hat的维度由(1,m)变为(C, m)

十、深度学习框架
1.使用深度学习框架的好处是在搭建神经网络时,你只要保证前向传播时没有问题即可,编程框架会保证反向传播的正确执行。
2.常见的深度学习框架:caffe/caffe2,CNTK,DL4J,Keras,Lasagne,mxnet,paddlepadle,tensorflow,Theano,Torch等。
3.选择深度学习框架的一些原则:(1)是否便于开发和部署;(2)运行速度;(3)是否真正开源并有很好的维护;(4)使用编程语言的习惯;(4)应用领域:计算机视觉、自然语言处理还是线上广告推荐。
十一、Tensorflow介绍
见编程练习题。