TensorFlow
欢迎来到这周的最后一个视频,有很多很棒的深度学习编程框架,其中一个是TensorFlow,我很期待帮助你开始学习使用TensorFlow,我想在这个视频中向你展示TensorFlow程序的基本结构,然后让你自己练习,学习更多细节,并运用到本周的编程练习中,这周的编程练习需要花些时间来做,所以请务必留出一些空余时间。
先提一个启发性的问题,假设你有一个损失函数 需要最小化,在本例中,我将使用这个高度简化的损失函数, ,这就是损失函数,也许你已经注意到该函数其实就是 ,如果你把这个二次方式子展开就得到了上面的表达式,所以使它最小的 值是5,但假设我们不知道这点,你只有这个函数,我们来看一下怎样用TensorFlow将其最小化,因为一个非常类似的程序结构可以用来训练神经网络。其中可以有一些复杂的损失函数 取决于你的神经网络的所有参数,然后类似的,你就能用TensorFlow自动找到使损失函数最小的 和 的值。但让我们先从左边这个更简单的例子入手。
我在我的Jupyter notebook中运行Python,
xxxxxxxxxx
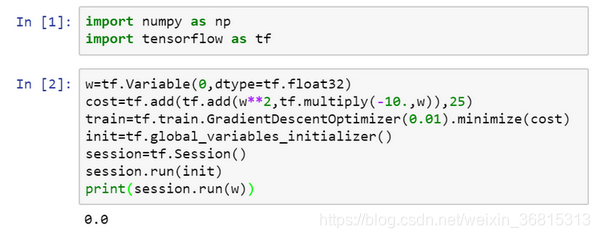
import numpy as np
import tensorflow as tf
#导入TensorFlow
w = tf.Variable(0,dtype = tf.float32)
#接下来,让我们定义参数w,在TensorFlow中,你要用tf.Variable()来定义参数
#然后我们定义损失函数:
cost = tf.add(tf.add(w**2,tf.multiply(- 10.,w)),25)
#然后我们定义损失函数J
然后我们再写:
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
#(让我们用0.01的学习率,目标是最小化损失)。
#最后下面的几行是惯用表达式:
init = tf.global_variables_initializer()
session = tf.Session()#这样就开启了一个TensorFlow session。
session.run(init)#来初始化全局变量。
#然后让TensorFlow评估一个变量,我们要用到:
session.run(w)
#上面的这一行将w初始化为0,并定义损失函数,我们定义train为学习算法,它用梯度下降法优化器使损失函数最小化,但实际上我们还没有运行学习算法,所以#上面的这一行将w初始化为0,并定义损失函数,我们定义train为学习算法,它用梯度下降法优化器使损失函数最小化,但实际上我们还没有运行学习算法,所以session.run(w)评估了w,让我::
print(session.run(w))
所以如果我们运行这个,它评估 等于0,因为我们什么都还没运行。
xxxxxxxxxx
#现在让我们输入:
$session.run(train),它所做的就是运行一步梯度下降法。
#接下来在运行了一步梯度下降法后,让我们评估一下w的值,再print:
print(session.run(w))
#在一步梯度下降法之后,w现在是0.1。

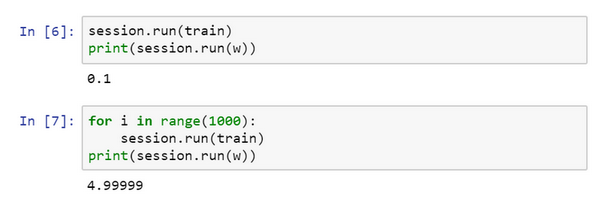
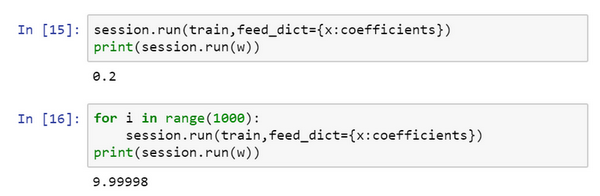
现在我们运行梯度下降1000次迭代:

这是运行了梯度下降的1000次迭代,最后 变成了4.99999,记不记得我们说 最小化,因此 的最优值是5,这个结果已经很接近了。
希望这个让你对TensorFlow程序的大致结构有了了解,当你做编程练习,使用更多TensorFlow代码时,我这里用到的一些函数你会熟悉起来,这里有个地方要注意,
是我们想要优化的参数,因此将它称为变量,注意我们需要做的就是定义一个损失函数,使用这些add和multiply之类的函数。TensorFlow知道如何对add和mutiply,还有其它函数求导,这就是为什么你只需基本实现前向传播,它能弄明白如何做反向传播和梯度计算,因为它已经内置在add,multiply和平方函数中。
对了,要是觉得这种写法不好看的话,TensorFlow其实还重载了一般的加减运算等等,因此你也可以把
写成更好看的形式,把之前的cost标成注释,重新运行,得到了同样的结果。
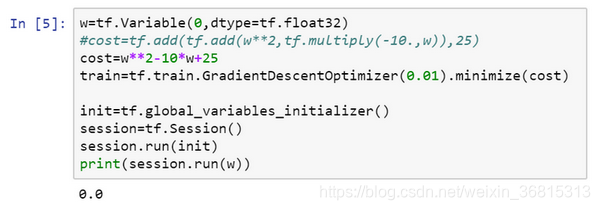
一旦 被称为TensorFlow变量,平方,乘法和加减运算都重载了,因此你不必使用上面这种不好看的句法。
TensorFlow还有一个特点,我想告诉你,那就是这个例子将 的一个固定函数最小化了。如果你想要最小化的函数是训练集函数又如何呢?不管你有什么训练数据 ,当你训练神经网络时,训练数据 会改变,那么如何把训练数据加入TensorFlow程序呢?
我会定义
,把它想做扮演训练数据的角色,事实上训练数据有
和
,但这个例子中只有
,把
定义为:x = tf.placeholder(tf.float32,[3,1]),让它成为
数组,我要做的就是,因为
这个二次方程的三项前有固定的系数,它是
,我们可以把这些数字1,-10和25变成数据,我要做的就是把
替换成:cost = x[0][0]*w**2 +x[1][0]*w + x[2][0],现在
变成了控制这个二次函数系数的数据,这个placeholder函数告诉TensorFlow,你稍后会为
提供数值。
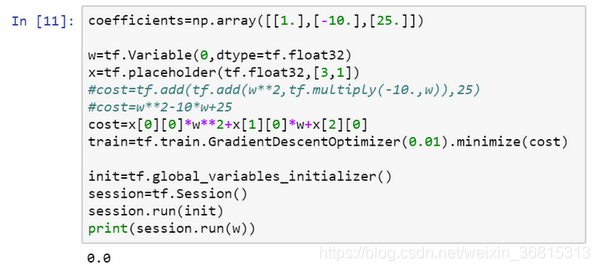
让我们再定义一个数组,coefficient = np.array([[1.],[-10.],[25.]]),这就是我们要接入
的数据。最后我们需要用某种方式把这个系数数组接入变量
,做到这一点的句法是,在训练这一步中,要提供给
的数值,我在这里设置:
feed_dict = {x:coefficients}
好了,希望没有语法错误,我们重新运行它,希望得到和之前一样的结果。
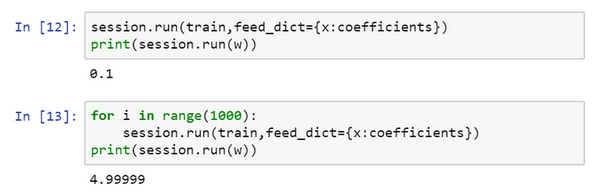
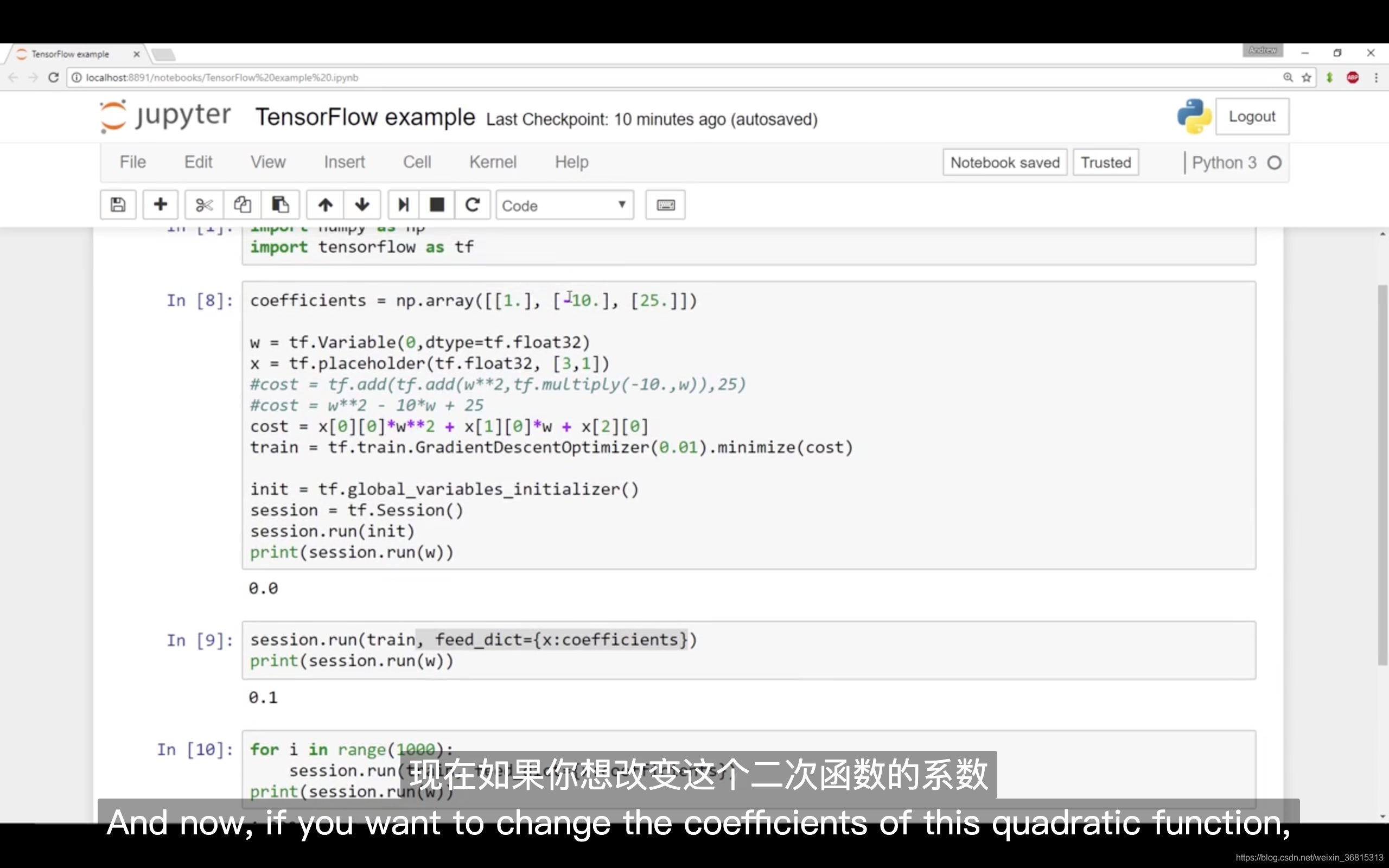
现在如果你想改变这个二次函数的系数,假设你把:
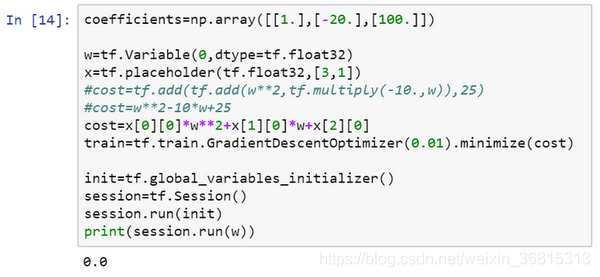
coefficient = np.array([[1.],[-10.],[25.]])
改为:coefficient = np.array([[1.],[-20.],[100.]])
现在这个函数就变成了 ,如果我重新运行,希望我得到的使 最小化的 值为10,让我们看一下,很好,在梯度下降1000次迭代之后,我们得到接近10的 。
在你做编程练习时,见到更多的是,TensorFlow中的placeholder是一个你之后会赋值的变量,这种方式便于把训练数据加入损失方程,把数据加入损失方程用的是这个句法,当你运行训练迭代,用feed_dict来让x=coefficients。如果你在做mini-batch梯度下降,在每次迭代时,你需要插入不同的mini-batch,那么每次迭代,你就用feed_dict来喂入训练集的不同子集,把不同的mini-batch喂入损失函数需要数据的地方。
希望这让你了解了TensorFlow能做什么,让它如此强大的是,你只需说明如何计算损失函数,它就能求导,而且用一两行代码就能运用梯度优化器,Adam优化器或者其他优化器。

这还是刚才的代码,我稍微整理了一下,尽管这些函数或变量看上去有点神秘,但你在做编程练习时多练习几次就会熟悉起来了。

还有最后一点我想提一下,这三行(蓝色大括号部分)在TensorFlow里是符合表达习惯的,有些程序员会用这种形式来替代,作用基本上是一样的。
但这个with结构也会在很多TensorFlow程序中用到,它的意思基本上和左边的相同,但是Python中的with命令更方便清理,以防在执行这个内循环时出现错误或例外。所以你也会在编程练习中看到这种写法。那么这个代码到底做了什么呢?让我们看这个等式:
cost =x[0][0]*w**2 +x[1][0]*w + x[2][0]#(w-5)**2
TensorFlow程序的核心是计算损失函数,然后TensorFlow自动计算出导数,以及如何最小化损失,因此这个等式或者这行代码所做的就是让TensorFlow建立计算图,计算图所做的就是取 ,取 ,然后将它平方,然后 和 相乘,你就得到了 ,以此类推,最终整个建立起来计算 ,最后你得到了损失函数。

TensorFlow的优点在于,通过用这个计算损失,计算图基本实现前向传播,TensorFlow已经内置了所有必要的反向函数,回忆一下训练深度神经网络时的一组前向函数和一组反向函数,而像TensorFlow之类的编程框架已经内置了必要的反向函数,这也是为什么通过内置函数来计算前向函数,它也能自动用反向函数来实现反向传播,即便函数非常复杂,再帮你计算导数,这就是为什么你不需要明确实现反向传播,这是编程框架能帮你变得高效的原因之一。

如果你看TensorFlow的使用说明,我只是指出TensorFlow的说明用了一套和我不太一样的符号来画计算图,它用了 , ,然后它不是写出值,想这里的 ,TensorFlow使用说明倾向于只写运算符,所以这里就是平方运算,而这两者一起指向乘法运算,以此类推,然后在最后的节点,我猜应该是一个将 加上去得到最终值的加法运算。
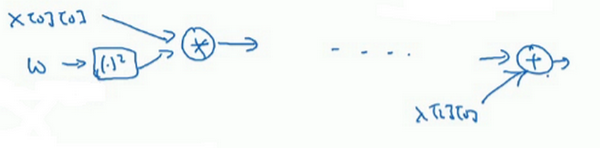
为本课程起见,我认为计算图用第一种方式会更容易理解,但是如果你去看TensorFlow的使用说明,如果你看到说明里的计算图,你会看到另一种表示方式,节点都用运算来标记而不是值,但这两种呈现方式表达的是同样的计算图。
在编程框架中你可以用一行代码做很多事情,例如,你不想用梯度下降法,而是想用Adam优化器,你只要改变这行代码,就能很快换掉它,换成更好的优化算法。所有现代深度学习编程框架都支持这样的功能,让你很容易就能编写复杂的神经网络。
我希望我帮助你了解了TensorFlow程序典型的结构,概括一下这周的内容,你学习了如何系统化地组织超参数搜索过程,我们还讲了Batch归一化,以及如何用它来加速神经网络的训练,最后我们讲了深度学习的编程框架,有很多很棒的编程框架,这最后一个视频我们重点讲了TensorFlow。有了它,我希望你享受这周的编程练习,帮助你更熟悉这些概念。
课程PPT