什么是决策树?
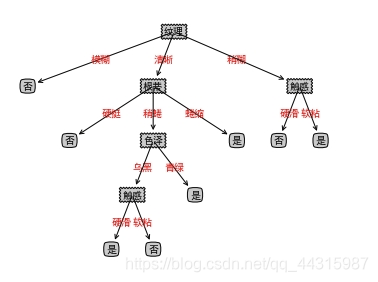
下图是一个是否是好瓜的决策树,其中长方形代表判断模块,椭圆代表终止模块,箭头表示分支
 表格表示为:
表格表示为:

信息熵
信息熵是度量样本集和纯度最常用的一种指标,假定样本集合D中第k类样本所占比例为pk(k=1, 2, 3…, m)
则信息熵定义为
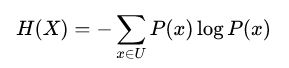
H(X)越小,D的纯的越高
本例中好西瓜的概率为8/17,坏西瓜的概率为9/17,所以根节点的信息熵为:
H(X) = -(8/17 * log2 8/17 + 9/17 * log2 9/17) = 0.998
下面我们用西瓜的色泽来进行划分,由条件概率我们知道
P(好西瓜|色泽青绿) = P(色泽青绿并且是好西瓜)/P(色泽青绿)
由表可知,
P(色泽青绿并且是好西瓜) = n(色泽青绿并且是好西瓜) / n(西瓜总数) = 3/17
P(色泽青绿) = n(色泽青绿) / n(西瓜总数) = 6 / 17
所以P(好西瓜|色泽青绿) = 3 / 6
由表我们也可以验证上面的答案:在六个色泽青绿的西瓜中有三个好的三个坏的
同理P(坏西瓜|色泽青绿) = 3 / 6
所以H(X|色泽青绿) = -(3/6 * log2 3/6 + 3/6 * log2 3/6) = 1.0
同理H(X|色泽乌黑) = -(4/6 * log2 4/6 + 2/6 * log2 2/6) = 0.918
H(X|色泽浅白) = -(1/5 * log2 1/5 + 4/5 * log2 4/5) = 0.722
X为西瓜的好坏
由全概率公式可得
P(X|色泽) = P(色泽青绿) * P(X|色泽青绿) + P(色泽乌黑) * P(X|色泽乌黑) + P(色泽浅白) * P(X|色泽浅白)
注意:这里的公式与课本稍有不同是因为概率空间不同的原因
所以可以得出H(X|色泽) = P(色泽青绿) * H(X|色泽青绿) + P(色泽乌黑) * H(X|色泽乌黑) + P(色泽浅白) * H(X|色泽浅白) = 0.889
定义信息增益为Gain(X, a) = H(X) - H(X|a)
本例的信息增益Gain(X, 色泽) = 0.998 - 0.889 =0.109
一般而言, 信息增益越大,意味着使用属性a来进行划分所获得的“纯度提升越大”
python构建决策树:
from math import log
import operator
class Trees():
def createDataSet(self): # 创建数据
dataSet = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no'], [0, 0, 'maybe']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
def calcShannonEnt(self, dataSet): # 极算香农熵,熵越高,混合的数据越多
numEntries = len(dataSet) # 样本数
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1] # 标签
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 # 标签与对应数量
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries # 概率p(xi)
shannonEnt -= prob * log(prob, 2) # H log(prob, 2) < 0 所以H大于0
return shannonEnt
def splitDataSet(self, dataSet, axis, value): # 按照指定特征划分数据集, axis划分数据集的特征, value需要返回的特征的值
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
# 把featVec[axis] 提取出去
reducedFeatVec= featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(self, dataSet):
numFeatures = len(dataSet[0]) - 1 # 最后一行是label
baseEntropy = self.calcShannonEnt(dataSet) # 计算熵
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): # 遍历所有特征
featList = [example[i] for example in dataSet] # dataSet的第i列即所有样本的第i个特征
uniqueVals = set(featList) # 去除相同的特征
newEntropy = 0.0
for value in uniqueVals:
subDataSet = self.splitDataSet(dataSet, i, value) # 提取value这个特征
prob = len(subDataSet) / float(len(dataSet)) # 计算这个特征占所有特征的比例即权重
newEntropy += prob * self.calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy # 计算ne信息增益, 信息增益越大意味着用第i种属性划分获得纯度提升最大
if (infoGain > bestInfoGain): # compare this to the best gain so far
bestInfoGain = infoGain # if better than current best, set to best
bestFeature = i
return bestFeature # returns an integer
def majorityCnt(classList):
classCount = {} # 创建一个集合
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] # 与kNN.classify0相似,返回出现次数最多的分类的名称
def createTree(self, dataSet, labels):
classList = [example[-1] for example in dataSet] # 获得类label
if classList.count(classList[0]) == len(classList): # 当所有类别都一样时停止分支
return classList[0]
'''
这里可以进行优化
'''
if len(dataSet[0]) == 1: # 当没有更多特征的时候停止分支
return self.majorityCnt(classList) # 返回出现次数最多的类别
bestFeat = self.chooseBestFeatureToSplit(dataSet) # 第i个特征的信息增益最大即使用第i个特征划分
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) # 获得bestfeat的可能取值
for value in uniqueVals:
subLabels = labels[:] # copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = self.createTree(self.splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
if __name__ == '__main__':
t = Trees()
myDat, labels = t.createDataSet()
myTree = t.createTree(myDat, labels)
print(myTree)
