二、决策树
决策树也是机器学习算法中的入门算法,算法原理简单效果良好,尤其是以树模型为基础的各种集成算法,更是功能强大,预测准确,还适用各种数据。决策树作为树一族算法的基模型,我觉得非常有必要认真梳理一下。
(一)决策树的基本原理
语言太苍白,看下图:

1、左边的表格是和决策树算法匹配的数据形式,前面讲KNN时,一开始就是说,了解一个算法之前首先要了解它的数据。决策树算法的数据也是一个二维表格数据,就是有行有列,行表示样本,列表示特征,当然还得有标签列,因为决策树也是一个有监督模型,没标签是没法建树的。这是决策树的数据结构,你别拿一个图片数据说用决策树算法来跑跑,那就见笑了,你必须还得仔细思量一下你的图片数据如何转化成二维表格数据。
2、右边的倒树就是算法从左边数据中学习完毕后创建的单颗决策树,就是我们建立的模型、算法,我们就是用这棵倒树来预测新样本的。
3、你仔细看看,是不是发现,右边的树其实就是对左边表的描述、归纳和总结!对的,是的,所以创建决策树就是对数据规律的学习和挖掘,或者说右边的决策树本质就是左边数据的另外一种表示形式。所以我们创建决策树的本质就是挖掘数据的规律,或者说我们创建决策树的本质就是把二维表格数据用树的形式来表示!
4、你再看是不是发现,树的椭圆结构都是表的特征名称,这些椭圆叫决策树的节点,第一个是根节点,其他的都是中间节点。
树的方框部分都是标签的类别,就是样本的标签,这些方框也是决策树的节点,但它叫叶子节点。
5、你再看,是不是左边表格中的所有样本(10个)都一个不拉得分到了右边决策树的叶子节点!是的,右图叶子节点下面的灰色数字就是对应的样本索引号。就是不管哪个样本,不管你的特征取值是什么,决策树我都会把你分到我的一个叶子节点上,然后给你打个标签!言外之意,决策树是通过递归的方式实现的,这个只有自己手动写决策树算法是才有真正的体会。
6、那么,对应一个不变的数据,就是左边的二维表格数据不变,是不是可以生成一棵唯一的右边的决策树呢?非也!我可以生成很多很多棵不同的倒树!比如我的根节点可以是婚姻情况这个特征啊,我从婚姻情况开始分支生成树难道不可以嘛?是滴,是可以的,那同理我就也可以从年收入开始生,甚至我用ID号生也可以,其他特征都不用,只用ID号,根节点是ID号,下面长10个叶子节点,这也是棵树啊!所以一个表格数据是可以用很多很多棵树结构来表示的。所以后续如何生成一棵最优的树就成了一个大命题。也所以一棵树不行,我建一片森林可否,于是有了后来的集成算法随机森林。
7、那么,到底哪棵树好呢?那就看哪棵树能帮助我们更好的预测新样本了。比如6中的按照ID列生成的10支树,显然是不能帮我们预测新样本的,再来一个ID号是11的样本,那这棵树是不是就懵了,就判断不出11号到底能不能按期偿还债务。再比如上右图的树,是否拥有房产,总共10条样本,也就是10个人,有3个拥有房产,而且3个人都是可以偿还的标签。如果说10个人就是全部样本,那只要你拥有房产,你就100%会按期偿还债务。即使第11号是总体中的新样本,那只要这个11号拥有房产,我们就可以推断出它100%概率会按期还款。如果11号没有房产,即使我们也不知道11号婚姻状况和年收入,那我们也可以推断它4/7的概率是按期偿还,3/7的概率是违约,当然如果再知道11号的婚姻状况和年收入等更多信息,那我们推断它还不还款的概率就更精准了。当我们精准的知道一个还款的概率,我们是不是就可以精准的放贷了。所以上图的决策树帮助了我们进行决策。也所以一颗优秀的树是可以辅助决策的,而一颗不优的树就相当于瞎猜。
8、即使上图的决策树可以帮我们进行决策,那那棵树就是最优的树吗?不一定!在都能帮我们做决策的时候,我们还得找一个最优的树,比如谁的决策最准、谁的决策决策最快,所以这就涉及到决策树生成过程中的一些细节和优化剪枝的一些细节。这里先把一个结论放这儿:即使我们追求的是最优的树,但是在递归的建树过程中,我们只能做到局部最优,无法做到全局最优。而局部最优不一定就是全局最优。有人说“从所有可能的决策树中选取最优决策树是个NP完全问题”。就是无法做到吧,那我们也必须有底线,就是至少要生成一颗有效的树吧。
9、我们继续梳理如何生成一棵有效的决策树?前面6说了,一个二维表格数据可以生成很多很多个不同的树,那是我以我作为人类的眼睛和大脑看到左边的表格数据后做出的树模型的结构,那要用算法生成一棵树,算法只知道数字的加减乘除和if else等判断,所以一个算法工程师要写出一个决策树模型,首先左边的二维表格数据中特征名称都要用0123代替了,每个特征下的取值,比如“是”与“否”的这种非数值型的都得先处理成0123这种数字编码型的,算法工程师才能开始写算法。
其次,算法工程师要继续考虑的是,我以什么依据来提问特征,就是我是从“拥有房产”这个特征开始提问还是从“婚姻情况”开始提问,那对硅基生物来说,你得给它指定规则或者给出计算公式。所以比如针对大型的二维表格数据,比如特征有数万个的情况下,算法工程师是可以给出你随机的规则的,就是你从这万多个特征中随机挑一个特征开始生长吧,所以我们眼花缭乱的决策树算法中就有一个算法叫Extra Tree, 以后你看到Extra Tree你就知道这个算法和别的算法最大的不同就是随机挑选特征进行分支。当然随机太随意了啊,我们必须给出一个计算公式,按照公式计算出哪个特征就用哪个特征来分支,那究竟用什么公式能表示你的特征选择呢?在纠结公式之前先想想我们的目的是什么?我们的目的就是我用这个特征分裂,会把所有训练样本分成的子样本的标签不纯度降低得最多,那我就用这个特征开始分。那用啥公式来计算标签的不纯度呢,那这种事情就不是我们一般人可以想得出的,这种事情一般都是伟人做的,最早就是一个叫香农的大牛,它想出来一个叫“熵”的公式来衡量不纯度,当然后来随着技术的发展,后人又发明了用基尼指数来衡量。所以现在市面上主流的决策树算法:ID3.5、C4.5、CART树,就是用了不同的计算不纯度方式而取得不同名字。其中ID3.5用的是信息增益,而信息增益的底层就是熵,C4.5用的是信息增益率,显然信息增益率是信息增益的改进版,CART树则用的是基尼指数来衡量。
10、第9点虽然说了很多,那按第9点的公式逐个计算每个特征并筛选出要分裂的特征,还是会遇到一些问题。问题1,如果这个特征是个连续特征呢,连续特征我怎么分裂并计算个子样本的不纯度,这里就牵扯到连续特征的离散化技术,具体怎么做,后面我单独再展开讲,总之你现在只要知道这个问题被克服了,我们再也不怕二维表格数据中有连续特征了。问题2,如果我的标签是连续的呢?!就是这压根就不是一个分类任务,是一个回归任务!那怎么办?答案是也和连续特征的处理方法一样去处理。所以最早的ID3.5算法是只能做分类不能做回归,而后来改进的C4.5、CART算法是既可以做分类也可以做回归。问题3,如果某个特征的取值非常多怎么办,比如我前面写的elo案例中,商品类型就有数十万种,我生成树的时候,加入我随机选到这个特征了,我是要计算数十万的子样本的不纯度度吗?或者说我们是要在这个节点上分数十万个叉吗?显然都是不可行的,要么计算量太大效率低,要么就是模型过拟合,根本没法预测准确率低!所以我们目前主流的ID3.5、C4.5、CART这三个算法都是二分叉树,就是不管你这个特征下面有多少种取值,都二分叉,那又衍生一个问题按哪个值来二分叉?遍历所有的二分类,看依照谁分叉后的不纯度最低,就按谁喽。只有在ID3.5之前的ID3是多叉树。问题4,如果有缺失值怎么办?其实这个问题计较好解决,只要给缺失值标注一个值即可。但是ID3.4是不支持训练数据中有缺失的,但是后来的C4.5、CART都进行了改进,有缺失值也不用怕了。
11、上面说的都是如何生成一棵树,那当一棵树生成后,如何剪枝呢,就是接着第8点继续说。从上图也可以看到,我们的树是要一直长到叶子节点的,只要节点上的样本的标签还有不一样的,就得继续分,继续长。试想一个像elo案例中几十万样本,数千上万个特征,这得生成多大的一棵树啊,所以必须要剪枝,一是剪枝可以提高效率,二是剪枝可以防止过拟合overfitting。树模型是很容易就过拟合,对抗过拟合是树模型的重点。而剪枝就是去掉部分叶子节点,让对应的中间节点变成叶子节点。这也很容易看出,剪枝后的模型的准确率肯定是要下降了,比如上图中,假如我们把年收入这个中间节点后面的叶子全部剪掉,那年收入的节点就变成了叶子节点,这个节点就是没有拥有房产的、婚姻情况是未婚的所有样本,就是样本5、8、10、3这4个样本,这4个样本中5、8、10的标签是无法偿还,3号样本是可以偿还,那这4个样本贡献一个叶子节点,那这个叶子节点的标签自然是按照少数服从多数,是无法偿还了,所以此时样本3就是错判的。在我们没有剪枝前,上图右边的树模型对训练集是100%正确判断的,现在我们把年收入这个节点剪了,那这棵树对训练样本的准确率就从100%下降到90%了。此时如果来一个新样本,刚好是没有房产没有结婚,年收入大于80k,但模型就会误判为无法还款,我们信贷人员如果严格参考模型的建议,那就漏掉了优值客户。
所以,剪枝是必须的,但剪枝又是一项技术活和经验活。
12、11说得太感性,理性的说法是:在实际操作中剪枝分预剪枝(Pre-Pruning) 与后剪枝(Post-Pruning),其中后剪枝又牵扯到很多算法,所以本部分后面再单独讲。
以上是决策树的基本原理和部分细节的一个总结,下面是针对上面总结中的一些重点细节的展开:
(二)生成一棵树
上面小结的时候有提到“不纯度”、“熵”、“尼基系数”、“信息增益”等概念,这里把这几个概念详细梳理一下。这几个公式你搞懂了,决策树背后的数学你就明白了,以后模型出现什么问题,你就可以有方向的寻找问题的源头了。要说的是,网上写决策树的人非常多,也有很多展示数学公式的,但是大家都是按照自己的理解,公式写的五花八门,各种符号和脚标,但又没有符号和脚标的说明,往往是几个人有几种写法。我本人也不擅长敲数学公式,所以我也是能截图就截图,但下面这个图我是花了老大劲去修改的,其实我想说的是公式不难,难得是你说清楚计算过程。
1、我们所说的“不纯度”指的都是标签列取值的纯度,如上图A处就是我们训练集的标签列。如果A列取值都是"是"或者“否”,那A列是非常纯的。如果A列总共有10个元素,它就有10种不同的取值,那它的不纯度是非常高的。
2、“不纯度”可以用信息熵来度量也可以用基尼系数来度量。由于最早人们都是用熵来度量的,所以ID3和C4.5都是用熵来计算的,后来的CART树是用基尼系数来度量的。下面我们按照熵和基尼系数的公式,计算几组不纯度:
可见:
(1)不管是用熵还是尼基系数计算一个组数的不纯度,都是这组数的取值越多,不纯度值越大;数组的取值越少,不纯度值越小,最小为0。
(2)不管这组数到底有几个元素,不纯度值的大小只与这组数的取值种类的比例相关,而与这组数的元素个数无关。比如本例中的数组是有10个元素,如果它有5个元素的取值是“是”,另5个元素的取值是“否”,那它的不纯度就是1。如果一个数组是[2,3],也就是只有2个数,而且取值还是1:1,那这个数组的不纯度也是1。同理,一个有100个元素的数组,如果这100个元素的取值也是1:1,那它的不纯度也是1。结论:不纯度的大小只与一个数组的取值的多样性有关,而与数组的长度无关。
(3)信息熵比基尼系数对不纯度更加敏感。从上面的计算结果就可以看出:同样一个数组,用信息熵计算的不纯度的值要大于尼基系数计算出来的不纯度值。所以当你用信息熵作为指标时,决策树的生长会更加“精细”,因此对于高维数据或者噪音很多的数据,信息熵很容易过拟合,基尼系数在这种情况下效果往往比较好。当然,这不是绝对的。
(4)信息熵在计算过程中要用到对数计算,而尼基系数不用,所以适用基尼系数效率要高。
3、计算标签列的不纯度干嘛用?当然给我们生成树提供参考指标的呀。决策树是怎么生成的?我们先假设最简单的情况,假设训练数据都是离散型的,而且每个特征的取值都是有限的几个的。那这个数据要生成一个决策树,就是先找一个特征,然后按照这个特征的所有取值进行分支,然后每个分支里的数据又看成一个子数据,继续挑除了前面已经挑过的特征,然后再继续分支,如此往复,这就是递归得生成一棵树。
那现在的问题是挑哪个特征进行分支?我们自然是挑这样的特征,就是用这个特征分支后,所有的子数据的不纯度最小的那个特征。那这个过程的数学度量就是“信息增益”。就是逐个特征去计算,如果按照它来分支的话,分完后所有子数据的加权不纯度和,看谁前后的不纯度差最大(就是信息增益最大),就用谁来分支。下面我用例子展示一下信息增益的计算过程,也就是挑选特征进行分支的过程: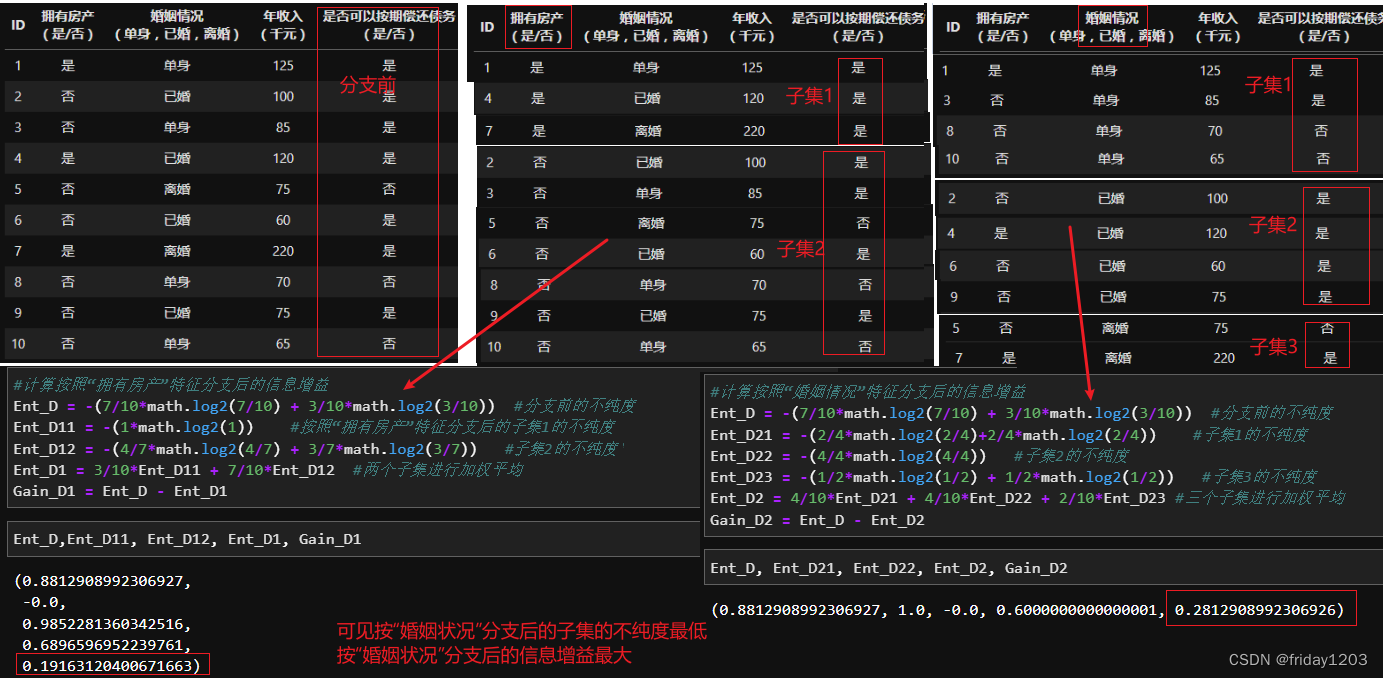
说明:
(1)上图只是举了2个特征的例子,实际中是要遍历所有的特征,计算每个特征的信息增益,找出信息增益最大的那个特征,按照那个特征进行分支。
(2)可见,树的生成是按照信息增益最大的特征进行创建的。我们最早的ID3树背后的数学就是:用信息熵来计算信息增益,选择信息增益最大的特征进行分支。但是有没有发现一个问题:当一个特征的取值种类越多,那它的信息增益是不是就越大。以上图的ID列为例,假如我们把ID列也当成特征带入计算了呢,是不是按ID列进行10分支,分支后的10个子集的熵都是0,加权熵自然也是0,那ID列的信息增益是不是就是最大的!所以上述的计算方式对有较多特征取值的特征有利,模型倾向于选择取值较多的特征进行分支。显然这是不合理的,所以后来的C4.5算法把信息增益改成了信息增益率,选择信息增益率最大的特征进行分支。从上上图的信息增益率的公式来看,信息增益率就是将信息增益除以该特征列自身的不纯度。还用上图的例子,我演示一下信息增益率:
可见,改成信息增益率进行分支可以避免模型倾向选择取值较多的特征。但是它又倒向了另一个极端,就是算法又倾向于选择特征取值较少的特征。假如有一列特征它取值全是0或者全是其他某个数,那这列特征自身的不纯度就是0,当0作为分母时,它的结果不就是趋向无限大嘛,那不就又倾向于用这种特征进行分支了,显然这种特征毫无分类意义啊。鉴于此C4.5做了一个隐式的规则:先找出信息增益高于平均水平的特征,再从中选择增益率最高的,这种折中方法。
以上是按照信息熵来计算不纯度然后挑选特征的方法,后来的CART算法直接抛弃了熵,用的是gini系数,前面有截图展示了gini系数的计算过程,其他步骤都一样。用gini系数,一是计算会快一些,二是会避免树长得过于精细而过拟合。
(3)这里又衍生出2个小问题:问题1,ID3.5、C4.5、CART不是都是二分叉吗,现在怎么是多分叉了?问题2,如果某个特征或者标签是连续型的,那怎么处理?
问题1:由于多分叉会生成非常精细而且非常大的一棵树,显然这样的树是过拟合的,所以大家都使用二分(Binary Split):就是在特征筛选过程中,都对样本数据进行二分。比如当遍历到“婚姻状况”这个特征的时候,就把数据划分为“单身”和“非单身”,然后计算信息增益,再把数据划分为“已婚”和“非已婚”计算信息增益,再把数据划分成“离婚”和“非离婚”计算信息增益,就是计算三次信息增益,然后保留最大的那个值。当遍历完所有特征后,对比所有特征的最大值,选择最大中的最大值对应的特征进行split。所有现在的树都是二分叉树。
问题2:其实和处理多分叉是一个道理,比如我们的特征“年收入”就是一个连续特征,先把年收入的值从小到大排列:60,65,70,75,85, 100, 120, 125, 220,然后计算两两之间的中值:62.5, 67.5, 72.5, 80, 92,5, 110, 122.5, 172.5,然后就是和问题1中的思路一样,不断计算小于和大于这些中值的信息增益,然后保留信息增益最大的那个中值作为该特征的信息增益,然后再PK所有特征的信息增益,选最大的进行分支。
同理,如果是标签列是连续型的话,也是把所有标签取值排序,取中值,然后连续的标签就被看出了离散标签,其他就是分类任务没有区别。
4、至此,我们知道一棵树是怎么生成的了吗?就是计算全部特征的所有二分结果的不纯度--再计算信息增益或者信息增益率--根据信息增益和信息增益率选取最优的特征,按这个特征开始分支。分支完毕后,下一轮分支,就是在上一轮分的两个子集上,分别重复第一轮的分支方法:计算不纯度--计算信息增益或信息增益率--选择最优特征分支,不断重复这个过程,直到没有更多的特征可用,或者所有的样本都被正确分类了,决策树就停止生长。这就是递归得生成一颗完整的树的全部过程。树是生成了,这棵树的效果好不好,就看你的剪枝技术了。
(三)剪枝
对树模型来说,剪枝和生成树是一样的重要。剪枝分预剪枝(Pre-Pruning) 与后剪枝(Post-Pruning)。
我们的树都是递归地生成的,就是直到没有特征可分为止或者直到标签全部都一样为止,树就自动停止生长了。从定义上看,预剪枝就是你在生成树的过程中就设定一些规则,当符合规则后,树就停止生长。比如:
设定树的最大深度:就是超过设定深度的树枝全部剪掉,这是用的最为广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所以限制树深度能够有效地限制过拟合。
设定分支时的最小信息增益量:就是如果不纯度下降的非常小时,小到你设置的阈值时,那就不要继续生长了,这个节点自己就当一个叶子节点吧。
设置叶子节点的样本数:就是如果一个节点中的样本量小于某个阈值时,就没必要继续分了。
上面只是举了几个例子,还可以从很多细节去限制树的生长。但是我想说的是预剪枝本身就有很多弊端,因为预剪枝就相当于先设置好树的形状,然后再装数据。其实实际中,我们往往是先有数据,然后希望根据我的数据生成一个适合我数据的树,所以后剪枝的欠拟合的风险会更小,同时泛化能力往往还会高于预剪枝。但缺点就是开销相对大。
后剪枝则是先根据训练集生成一颗完整的决策树,然后根据相关方法进行剪枝。常用的剪枝方法有下面四种:
其中,REP剪枝算法是CART树采用的后剪枝算法,即先生成决策树,然后产生所有可能的剪枝后的CART树,然后使用交叉验证来检验各种剪枝的效果,选择泛化能力最好的剪枝策略。也就是说,CART树的剪枝算法可以概括为两步,第一步是从原始决策树生成各种剪枝效果的决策树,第二步是用交叉验证来检验剪枝后的预测能力,选择泛化预测能力最好的剪枝后的数作为最终的CART树。
PEP剪枝算法是在C4.5决策树算法中提出的,该方法基于训练数据的误差评估,因此比起REP剪枝法,它不需要一个单独的测试数据集。但训练数据也带来错分误差偏向于训练集,因此需要加入修正1/2(惩罚因子,用常数0.5),是自上而下的修剪。 之所以叫“悲观”,可能正是因为每个叶子结点都会主观加入一个惩罚因子,“悲观”地提高误判率。 PEP采用自顶向下的方式 将符合上述不等式的非叶子结点裁剪掉。该算法看作目前决策树后剪枝算法中精度比较高的算法之一,同时该算法仍存在一些缺陷。首先,PEP算法是唯一使用自顶向上剪枝策略的后剪枝算法,但这样的方法有时会导致某些不该被剪掉的某结点的子结点被剪掉。虽然PEP方法存在一些局限性,但是在实际应用中表现出了较高的精度。
(五)调包实现一个决策树模型
其实决策树的原理和背后的数学都不难,难的是细节太多,它背后攒了太多的细节的处理和规则,就很难一一列举。真是屏着气梳理出了上面的十几个点。大家也应该看到剪枝这块儿我已经是应付的状态了,没关系,只要你知道有这几种剪枝算法,你自己再去百度细细梳理吧,因为你要想非常清楚每种算法,就不是一言两语的事,所以这里我就不展开了。
另外,我要说的是,看网上有很多人都自己手写一个决策树,其实也是没有很大必要的,原因还是,一是你自己的经历和时间有限,你写的只能应付小型数据,因为你只能写一个决策树的生成,决策树的剪枝优化呢,如果这些都写全,那工作量是很大的,所以对于大型数据或者复杂数据,你自己写的效果肯定不行。二是决策树这个算法也不是一个新算法,经过这么长时间的很多人的优化和改进,现在已经很成熟,干嘛要重复造轮子,而且你还不一定能造出比现在的轮子更好的轮子,所以我们还是掉包吧。
1、sklearn.tree模块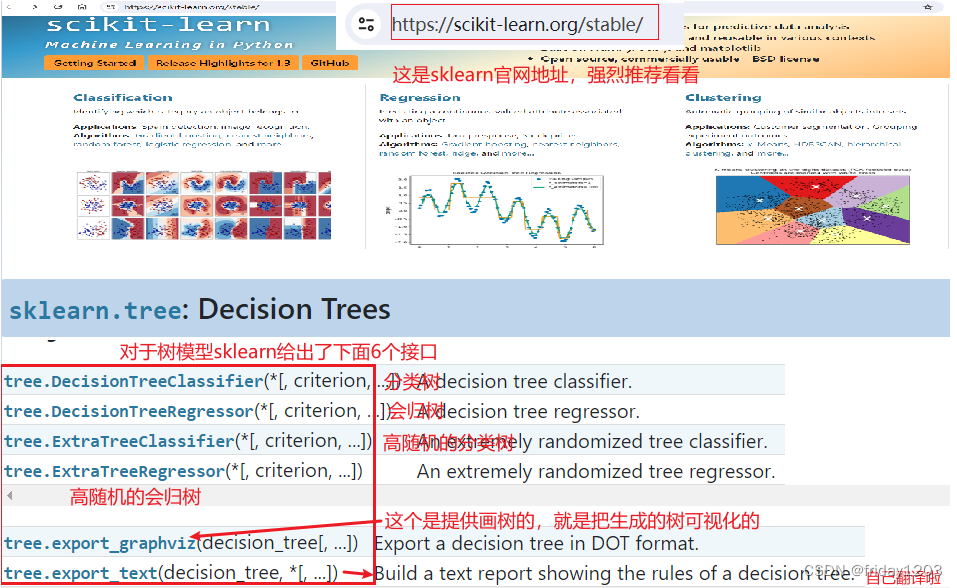
sklearn之于机器学习,就好比pytorch之于深度学习的关系。所以你要学机器学习离不开sklearn,强烈建议大家到sklearn的官网看看,官网的东西非常丰富,你直接可以看到源码。
从上面截图中可以看到sklearn给我们提供了6个接口,其中前4个接口是模型接口,第一个是基于CART算法的分类树,第二个是回归树,第三个就是前面强调过的随机树,当你特征成千上万个的时候,你试试随机树,当然随机树也分分类树和回归树两类。第5个接口是提供可视化的,就是我们生成的树它就是一个数据的存储对象,你可以用一个字典不停的嵌套,也是一颗树,但可视化后我们人类更直观嘛,所以我们都用这个接口可视化。第6个接口是输出决策树的规则。
下面我就用tree.DecisionTreeClassifier()给大家示例。
2、tree.DecisionTreeClassifier()
接口参数:
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)
criterion:{“gini”, “entropy”, “log_loss”},就是计算不纯度的方式,这里有3种选择,我前面讲的是前两个。
splitter:{“best”, “random”},best就是按照计算结果选中哪个特征就按哪个特征分支,random表示不用计算了,我随机选。当特征非常多时,这个参数设置成random会快一些。
max_depth:是树的最大深度,这个参数就是暴力剪枝的一个参数。比如我设置max_depth=5,就表示这棵树分支5层就强制结束生长了。就是后面的节点都暴力删除,然后按照voting打标签。
min_samples_split:这个参数也是剪枝的参数,也是限制树的生长的参数。比如min_samples_split=2就表示当一个中间节点只有2个样本了,但是这2个样本的标签还不一样啊,按道理就得继续分支,直到这2个样本都成一个叶子节点为止,但你设置了这个参数,那就不用分支了。就是如果一个节点上只有2个样本了,即使样本的标签不一样,也不用分支了。
min_samples_leaf:表示一个叶子节点至少要有多少个样本。是从另外一个角度限制树的生长。
min_weight_fraction_leaf:默认值是0就是不考虑权重问题,就是各样本同权。
class_weight:上面的参数一般和这个参数搭配使用,就是min_weight_fraction_leaf设置不为0时,参数class_weight就得设置你想要的权重了。这两个参数一般是针对样本极不均衡的数据才进行设置的。
max_features:The number of features to consider when looking for the best split。实在懒得敲了。
random_state:随机模式。从前面的一大堆讲解可以看到,一份相同的数据,是可以生成多棵不同的树的,中间有很多地方是需要随机的,所以我们要设置一个随机模式,也就是一个随机种子,设置了随机模式后,你不管运行多少次,它都按这个随机模式生成树,这样我们就能每次运行都生成相同的树了。不然,假如你这次瞎撞,跑出了一个高分的模型,你给老板展示的时候,啊,不能复现了,这得多尴尬啊。设置了这个参数,就不会出现这个问题了。
max_leaf_nodes:设置最大叶子节点个数。这个参数也是剪枝的参数,但这个参数一般在对数据不是特别特别了解的情况下,你是不知道该怎么设置的。所以一般我们不动这个参数。
min_impurity_decrease:不纯度的最小减少值。同理max_leaf_nodes参数,数据不熟悉,一般不动这个参数。
当你对决策树的原理和生成过程剪枝过程都非常了解的话,上面的参数就非常容易理解了。如果你还不理解,看官网,写得非常详细。
3、用分类树跑跑鸢尾花数据



如果你觉得上面的建模过程和预测过程都太简单,或者你还想知道这个模型的泛化能力怎么样?就是这个模型除了在上述的45个测试样本上有97.777%的准确率外,那它在其他新数据上的预测能力如何呢?你此时可以用交叉验证试试。
考察模型泛化能力有很多种方法,其中交叉验证只是方法之一。所谓交叉验证就是将数据集(具体这里就是iris)随机的、平均的分成几份(这里我设置的cv=10,就是10份),然后取其中的1份作为测试集,其他份就都是训练集。假如cv=10,那我们现在是不是就生成了10个数据集,每个数据集都是10%的测试集,90%的训练集。然后把这10个数据集分别去训练模型(具体我这里的模型就是clf),那不同的训练集是不是就生成了不同的10棵树,同时生成10个测试集的准确率。我们一般看这10个数的均值,就是我们这个模型的泛化水平。如下图所以,我们建立的clf模型的泛化准确率就是96%。
如果你还是觉得虚无缥缈,那就把你建的树画出来看看吧 
从可视化图可以看到,我们的建的这棵树所有的叶子节点都是标签纯纯的,也就是我们这棵树对我们的训练集是100%拟合的。也所以上图右下角的score是1.0,就是100%对,就是对训练集的105个样本来说都是分对的。但是对测试集就不是,测试集只有97.77778%。而从10折交叉验证看这个模型泛化能力,那它的准确率只有96%了。
(六)模型调优
1、画学习曲线
现在我们的模型就是: clf = DecisionTreeClassifier(random_state=0) ,其他参数都是默认值。这也太简单了!强行加戏,调个优,听说max_depth是最常调的参数,那我就用这个参数来画个学习曲线来分析分析:
这个数据集太太简单了,以至于max_depth这个参数取3或者4或者5或者6,在测试集上的准去率都是97.77778%,这是我始料不及的,有点小尴尬。anyway,这就是一个朴素的调优方法。对于机器学习模型,调优就是调最好的一组参数,在这组最优参数下,模型对你的测试集的预测达到最高,就说明你的模型是最优的,我们要选的参数就是这组参数。
如果上图的曲线是有大有小有高有低,我们就选择最高的那个点对应的那组参数,就是最优的模型。
上图画的就是参数max_depth的学习曲线,当然你也可以画其他参数的学习曲线。总之画学习曲线是机器学习模型调优的常用手段之一。
最后再补充几个属性的接口:
2、网格搜索
上面的学习曲线画得有点尴尬,那就再用一个别的数据集给大家演示一下网格搜索吧。
上述过程就是一个完整的网格搜索全过程。机器学习中的模型调优基本都要用到。上面的学习曲线只能一个参数画一个学习曲线,看不到所有参数联动的效果,所以如果参数很多都要调,你就用网格搜索。当然网格搜索的最大缺点就是慢。
说白了,网格搜索就是把所有的参数划定一个取值范围,然后在这些范围中,穷尽所有的参数组合,来找到一组最优的超参组合。所以网格搜索的效率是很低的,也所以后来又有了RandomizedSearchCV,这个搜索器是在你给的参数组合范围内,再随机划分一个子组合,子组合自然是比你划分的范围小了,然后它在这个子组合范围内搜索最优组合。这样就提高了效率。有利有弊,效率高了精度肯定下降啊,只要你可以接受就好。
而现在更高效搜索器是HalvingGridSearchCV,这个搜索器在sklearn的0.24版本才有,也是这个版本的最大改动之一。这个搜索器也是先穷算出你给的参数空间中的所有参数组合,然后两两对比,pass一半,然后继续把剩下的参数组合继续两两对比,再pass一半,如此往复,直到找到最优的参数组合。这种搜索策略在多线程下是非常高效的,可以加快计算速度,因为它可以并行计算啊。
如果你想兼顾效率和精度,建议你先用RandomizedSearchCV确定一个大致范围,然后用GridSearchCV高精度搜索具体的参数组合。
这里我只是示例了一个分类树,其实回归树和分类树还是有很多不一样的地方的,调包的参数都不一样。anyway,这个只是领入门,有了这些铺垫后,你就可以自己继续深入探索了。
最后补充:决策树的方法和属性:
-------------预测与评估---------------------
clf.predict(X) :预测X的类别
clf.predict_proba(X) :预测X属于各类的概率
clf.predict_log_proba(X) :相当于 np.log(clf.predict_proba())
clf.apply(X) :返回样本预测节点的索引
clf.score(X,y) :返回准确率,即模型预测值与y不同的个数占比(支持样本权重:clf.score(X,y,sample_weight=sample_weight))
clf.decision_path(np.array([0 ,1 ,2 ,1 ]).reshape(1, -1)).todense() : 返回决策路径:格式[ 1 1 0 0 0] ,它代表通过了第0,第1个节点。
-----------------剪枝-------------------------
clf.cost_complexity_pruning_path(X, y) :返回 CCP(Cost Complexity Pruning代价复杂度剪枝)法的剪枝路径。
备注: CCP的计算方法请参考文章:《决策树后剪枝:CCP剪枝法》
--------------树信息--------------------------
clf.get_depth() :返回树的深度
clf.get_n_leaves() :叶子节点个数
clf.tree_.node_count :总节点个数
--------------树明细数据--------------------------
左节点编号 : clf.tree_.children_left
右节点编号 : clf.tree_.children_right
分割的变量 : clf.tree_.feature
分割的阈值 : clf.tree_.threshold
不纯度(gini) : clf.tree_.impurity
样本个数 : clf.tree_.n_node_samples
样本分布 : clf.tree_.value
备注:详细解说请参考文章:《决策树训练后的模型数据》
--------------其它--------------------------
clf.feature_importances_ :各个特征的权重。
clf.get_params() :查看模型的入参设置
如果想获取节点上样本的数据,sklearn不直接提供,但可以借用 clf.apply(X) ,把原数据作为输入,间接获得。
备注:特征权重的计算方法:《决策特征权重feature_importances计算方法》