一、算法简介
决策树一般都是自上而下来生成的,每个决策后事件(即自然状态)都可能引出两个或多个事件,导致结果的不同,把这种结构分支画成形状很像一棵树的枝干,故称为决策树。
决策树能够读取数据集合,并且决策树很多任务都是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取一系列规则,机器学习算法最终将使用这些机器从数据集中创造的规则。
决策树就是将决策过程各个阶段之间的结构绘制成一张箭线图,我们可以用下图来表示:
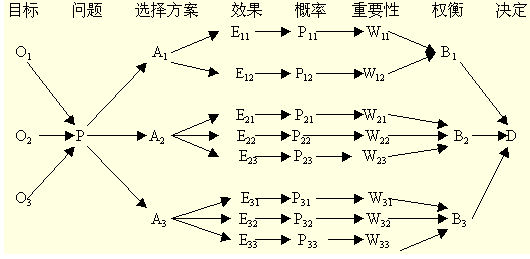
二、构成要素
决策树由节点和有向边组成,节点的类型有两种,分别为内部节点和叶子节点,其中,内部节点表示一个特征或属性的测试条件(用于分开具有不同特性的记录),叶子节点表示一个分类。
三、算法思想
(1)树以代表训练的样本的单个节点开始
(2)如果样本都在同一个类,则该节点成为树叶,并用该类标记
(3)否则,算法选择最有分类能力的属性作为决策树的当前节点
(4)根据当前节点属性取值的不同,将训练样本数据集分为若干子集,每个取值形成一个分支,有几个取值形成几个分支,一旦一个属性出现在一个节点上,就不必在该节点的任何衍生子集在考虑它。
(5)递归划分步骤仅当下列条件之一成立时停止:
- 给定节点的所有样本属于同一类
- 如果某一分支没有满足该分支中已有分类的样本,则以样本的多数类创建一个树叶
现在我们已经大致了解决策树可以完成哪些任务,接下来我们将学习如何从一堆原始数据中构造决策树。
四、信息论基础
(1)熵:熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
其中n代表X的n种不同的离散取值。而pi代表了X取值为i的概率,log为以2为底的对数。
举个例子,比如X有2个可能的取值,而这两个取值各为1/2时
(2)条件熵:它度量了我们的X在知道Y以后剩下的不确定性,表达式如下:
(3)特征增益:信息增益特征选择中的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要,表达式如下:
H(X) - H(X|Y)
五、代码详情
from math import log
import operator
def createDataSet():
dataSet =[[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing','flippers']
return dataSet,labels
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
lableCounts = {}
for featVec in dataSet:
currentLable = featVec[-1]
if currentLable not in lableCounts.keys():
lableCounts[currentLable] = 0
lableCounts[currentLable] += 1
shannonEnt = 0
for key in lableCounts:
prob = float(lableCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1#因为数据集的最后一项是标签
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy -newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
#因为我们递归构建决策树是根据属性的消耗进行计算的,所以可能会存在最后属性用完了,但是分类
#还是没有算完,这时候就会采用多数表决的方式计算节点分类
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
return max(classCount)
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) ==len(classList):#类别相同则停止划分
return classList[0]
if len(dataSet[0]) == 1:#所有特征已经用完
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]#为了不改变原始列表的内容复制了一下
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,
bestFeat, value),subLabels)
return myTree
def main():
data,label = createDataSet()
myTree = createTree(data,label)
print myTree
if __name__=='__main__':
main()
六、输出结果
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
七、算法小结
决策树分类器就像带有终止块的流程图,终止块表示分类结果。开始处理数据时,我们首先需要测量集合中数据的不一致性,也就是熵,然后寻找最优方案划分数据集,直到数据集中的所有数据属于同一分类。ID3算法可以用于划分标称型数据集。构建决策树时,我们通常采用递归的方法将数据集转化为决策树。
有很多构建决策树的方法,包括ID3、C4.5、CART等,这里我用的是ID3算法。