本文为作者学习K近邻算法后的整理笔记,仅供学习使用!
决策树
1、概述
决策树(Decision Tree)实在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于0的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
2、基本原理
(1)工作原理:
a、获取原始数据集
b、基于最好的属性值划分数据集
c、数据将向下传递到树分支的下一个节点,再这个节点上,可以再次对数据进行划分
(2)递归结束的条件:
a、程序遍历完所有划分数据集的属性
b、每个分支下的所有实力都具有相同的分类
3、优缺点
(1)优点
计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据
(2)缺点
可能会产生过度匹配问题(过拟合)
适用数据类型:数值型和标称型
4、一般流程
(1)收集数据:可以使用任何方法
(2)准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化(数据预处理)
(3)分析数据:可以使用任何方法,构造树完成之后,检查图形是否符合预期
(4)训练算法:构造树的数据结构
(5)测试算法:使用经验树计算错误率
(6)使用算法:此步骤可以使用于任何监督学习算法
5、构建决策树:ID3是算法
(1)简介
a、对于实例,计算各个实例的信息增益
b、将信息增益最大的属性作为根节点,根节点的各个取值作为子集进行分类
c、对于子集下, 若只含有正例或反例,直接得到判决;否则递归调用算法,再次寻找子节点
(2)公式以及名词解释
a、公式
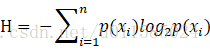
b、名词解释
香农熵:表示数据集的不确定性
条件熵:在某个条件下,数据集的不确定性
信息增益:香浓熵 - 条件熵,在某一条件下,信息不确定性减少的程度
(3)缺点:
ID3采用的信息增益度量存在一个缺点:它一般会选择属性值较多的Feature。信息增益反映的是给定一个条件以后不确定减少的程度,必然是分得越细的数据集的确定性越高,也就是条件熵越小,信息增益越大。
当数据集中存在自增列(ID)时,采用ID3算法会将ID列作为根节点。
(4)代码示例
a、创建数据集
# 创建数据集
def create_dataset():
dataset = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,0,'no']]
label = ['no surfacing', 'flippers']
return dataset, labelb、计算香浓熵
# 获取香农熵
def calc_shannon_ent(dataset):
label_count = len(dataset)
entries_count = {}
for entry in dataset:
current_label = entry[-1]
if current_label not in entries_count:
entries_count[current_label] = 0
entries_count[current_label] += 1
shannon_ent = 0.0
for key in entries_count:
probability = float(entries_count[key]) / label_count # 求概率
shannon_ent -= probability * log(probability, 2)
return shannon_entc、选择最优的特征进行拆分数据集
# 拆分数据集
def split_dataset(dataset, axis, value):
new_dataset = []
for data in dataset:
if data[axis] == value:
reduced_data = data[:axis]
reduced_data.extend(data[axis+1 : ])
new_dataset.append(reduced_data)
return new_dataset
# 选择最优的特征进行拆分数据集
def choose_best_feature_to_split(dataset):
num_features = len(dataset[0]) - 1 # 特征数
base_entropy = calc_shannon_ent(dataset) # 计算香农熵
best_info_gain = 0.0
best_feature = -1 # 最优特征
for i in range(num_features):
feature_list = [example[i] for example in dataset]
unique_vals = set(feature_list)
new_entropy = 0.0
for value in unique_vals:
sub_dataset = split_dataset(dataset, i, value)
prob = len(sub_dataset) / float(len(dataset)) # 概率
new_entropy += prob * calc_shannon_ent(sub_dataset) # 拆分后香农熵
info_gain = base_entropy - new_entropy
if(info_gain > best_info_gain):
best_info_gain = info_gain
best_feature = i
return best_featured、构建决策树
def majority_cnt(class_list):
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0
class_count[vote] += 1
sorted_class_count = sorted( class_count.iteritem(), key=operator.itemgetter(1), reversed = True)
return sorted_class_count[0][0]
def create_tree(dataset, labels):
class_list = [example[-1] for example in dataset]
if(class_list.count(class_list[0]) == len(class_list)):
return class_list[0]
if len(dataset[0]) == 1:
return majority_cnt(class_list)
best_feature = choose_best_feature_to_split(dataset)
best_feature_label = labels[best_feature]
my_tree = {best_feature_label:{}}
del(labels[best_feature])
feature_values = [example[best_feature] for example in dataset]
unique_values = set(feature_values)
for value in unique_values:
sub_labels = labels[:]
my_tree[best_feature_label][value] = create_tree(split_dataset(dataset, best_feature, value), sub_labels)
return my_treee、使用构建好的决策树
# 使用
def my_classify(input_tree, featLabels, textvec):
first_key = list(input_tree.keys())[0]
second_dict = input_tree[first_key]
feat_index = featLabels.index(first_key)
for key in second_dict.keys():
if textvec[feat_index] == key:
if type(second_dict[key]).__name__ == "dict":
classLabel = my_classify(second_dict[key], featLabels, textvec)
else:
classLabel = second_dict[key]
return classLabelf、储存
# 存储
def store_tree(input_tree, file_name):
import pickle
fw = open(file_name, 'wb')
pickle.dump(input_tree,fw)
fw.close()
def grab_tree(file_name):
import pickle
fr = open(file_name, 'rb')
return pickle.load(fr)g、调用
my_data, labels = create_dataset()
my_tree = create_tree(my_data, labels.copy())
store_tree(my_tree, "DecisionTree.txt")
my_load_tree = grab_tree("DecisionTree.txt")
predict_label1 = my_classify(my_load_tree, labels, [1,0])
predict_label2 = my_classify(my_load_tree, labels, [1,1])
print(predict_label1, predict_label2)6、构建决策树:C4.5
(1) C4.5是对ID3算法的改进,相对于ID3算法主要有以下几个方面的改进:
(a)用信息增益比来选择属性
(b)在决策树的构造过程中
(c)对非离散数据也能处理
(d)能够对不完整数据进行处理
(2)公式
7、构建决策树:CART
(1)CART算法是通过GINI系数选择最优特征,同时决定该特征的最优二值切分点
(2)公式
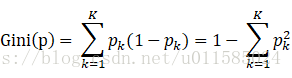
8、剪枝策略
(1)预剪枝
边建立决策树边进行剪枝的操作(更实用)。通过限制决策树深度、叶子节点个数、叶子节点样本树,信息增益量等进行预剪枝操作。
(2)后剪枝
当建立完决策树之后来进行剪枝操作。通过一定的衡量标准(叶子节点越多,损失越大):
