引言
决策树(Decision Tree)是机器学习中一种经典的分类与回归算法。在本篇中我们讨论用于分类的决策树的原理知识。决策树模型呈树形结构,在分类问题中,一颗决策树可以视作 if-then 规则的集合。模型具有可读性,分类速度快的特点,在各种实际业务建模过程中广泛使用。
1.信息熵
决策树的核心是基于信息熵的数据来生成对应的树分支
假定当前数据集 公式 中有 公式 类,其中第 公式 类样本占比为 公式,则信息熵的计算公式如下: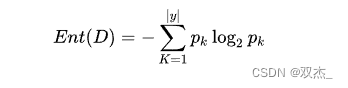
数学公式对应的数学曲线如下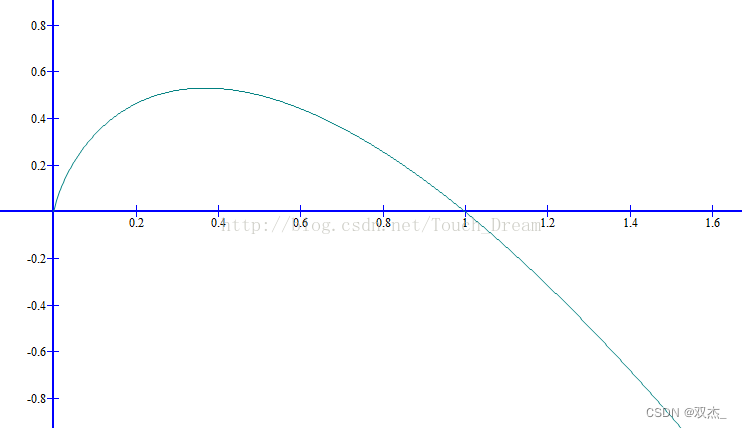
由公式可以看出,信息熵的计算采用的是概率乘以以二为底的对数得出,大概是这种曲线和熵的变化率比较接近。
对应曲线图形可以看出,当概率在0和1之间的时候熵的值接近0,也就是说当我们的分类在极端属性上的时候信息熵的变化较小,数据较正确
2.决策树生成策略
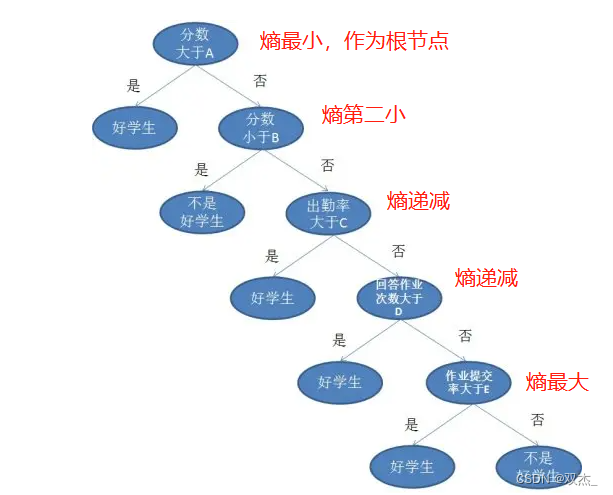
由下图可以看出决策树的概念和生成策略
当熵越小,说明分类的数据越精确,由此作为上级的根节点
3.信息增益和信息增益率
下图为信息增益的计算公式
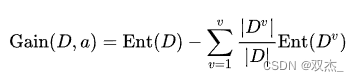
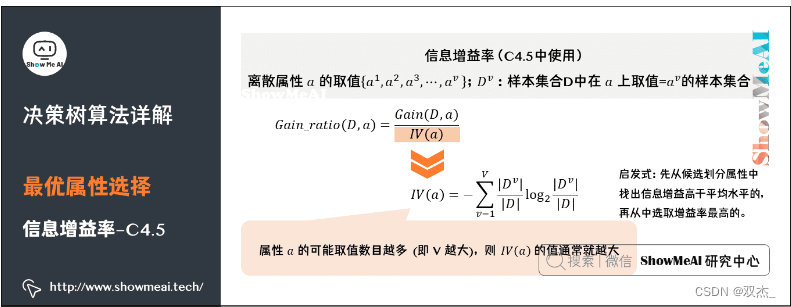
下图为信息增益率的计算公式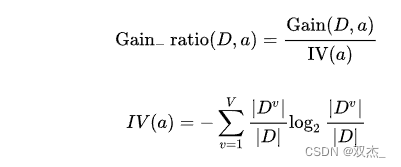
由于单纯根据熵来计算有一个问题,它偏向取值较多的特征。原因是,当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低。
由此我们得出了信息增益和信息增益率的概念
4.预剪枝与后剪枝
如果我们让决策树一直生长,最后得到的决策树可能很庞大,而且因为对原始数据学习得过于充分会有过拟合的问题。缓解决策树过拟合可以通过剪枝操作完成。而剪枝方式又可以分为:预剪枝和后剪枝。
预剪枝(pre-pruning):在决策树生长过程中,对每个结点在划分前进行估计,若当前结点的划分不能带来决策树泛化性能的提升,则停止划分并将当前结点标记为叶结点。
后剪枝(post-pruning):先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能的提升,则将该子树替换为叶结点。
简单来说,预剪枝是自上而下的判断是否需要剪枝,后剪枝是自下而上的判断是否需要剪枝
预剪枝与后剪枝的特点
时间开销:
预剪枝:训练时间开销降低,测试时间开销降低。
后剪枝:训练时间开销增加,测试时间开销降低。
过/欠拟合风险:
预剪枝:过拟合风险降低,欠拟合风险增加。
后剪枝:过拟合风险降低,欠拟合风险基本不变。
泛化性能:后剪枝通常优于预剪枝。
5.连续值与缺失值的处理
因为连续属性的可取值数目不再有限,因此需要连续属性离散化处理,常用的离散化策略是二分法
缺失值处理的基本思路是:样本赋权,权重划分。我们来通过下图这份有缺失值的西瓜数据集,看看具体处理方式。