版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/shankezh/article/details/78490678
简单介绍:
决策树算法主要还是依据数据的 信息熵 进行计算,划分树之前,主要先计算数据的 信息熵S,然后根据分支类别,计算各种子节点划分的信息熵E, 使用划分树前的信息熵减去子节点的信息熵 G(S,E) = S-E,增益最大(就是两者的差)最大的为选择的划分方法。
例如具有三种类型的数据(A,B,C),包含子项可以是{ (Ax1,Bx1,Cx1),(Ax2,Bx2,Cx2) , (Ax3,Bx3,Cx3) } 子节点的划分选择可以以A类型划分,也可以以B类型划分,也可以以C类型划分,分别计算出以各种类型划分组合的信息熵,然后找出其中增益最大的即可作为决策树划分方法,这种方法成为ID3方法。
常用的几种决策树算法有ID3、C4.5、CART:
ID3:选择信息熵增益最大的feature作为node,实现对数据的归纳分类。
C4.5:是ID3的一个改进,比ID3准确率高且快,可以处理连续值和有缺失值的feature。
CART:使用基尼指数的划分准则,通过在每个步骤最大限度降低不纯洁度,CART能够处理孤立点以及能够对空缺值进行处理。
使用id3来建立决策树:
假设结果的信息熵如下:
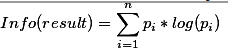
使用它的特性A进行分类划分,那么A的信息熵如下:
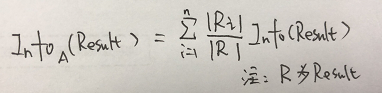
对应的特性A的信息增益则为:Info(result) - Info_A(Result)
信息熵公式如下:
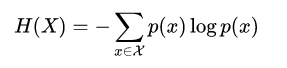 ,这里的log以2为底
,这里的log以2为底
举例:
我们用以下数据集为例子来共同学习:
主要是通过天气,气温,湿度,风力这些属性特征,来决定是否可以活动
| 序号 | 天气a | 气温b | 湿度c | 风力d | 是否活动e |
| 1 | 晴 | 炎热 | 高 | 弱 | 否 |
| 2 | 晴 | 炎热 | 高 | 强 | 否 |
| 3 | 阴 | 炎热 | 高 | 弱 | 是 |
| 4 | 雨 | 适中 | 高 | 弱 | 是 |
| 5 | 雨 | 寒冷 | 正常 | 弱 | 是 |
| 6 | 雨 | 寒冷 | 正常 | 强 | 否 |
| 7 | 阴 | 寒冷 | 正常 | 强 | 是 |
| 8 | 晴 | 适中 | 高 | 弱 | 否 |
| 9 | 晴 | 寒冷 | 正常 | 弱 | 是 |
| 10 | 雨 | 适中 | 正常 | 弱 | 是 |
| 11 | 晴 | 适中 | 正常 | 强 | 是 |
| 12 | 阴 | 适中 | 高 | 强 | 是 |
| 13 | 阴 | 炎热 | 正常 | 弱 | 是 |
| 14 | 雨 | 适中 | 高 | 强 | 否 |
从图表中数据可以看出,活动为5个否,9个是,那么计算信息熵(log以2为底)为:
h(e) = -(9/14) * log (9/14) - (5/14) * log (5/14 ) = 0.41 + 0.53 = 0.94
特征天气的信息熵为(5个晴,4个阴,5个雨):
h(e|a) = 5/14 * ( -2/5 * log( 2/5 ) - 3/5 * log(3/5) ) + 4/14 * ( -4/4 * log(4/4) ) + 5/14 * ( -3/5 * log(3/5) - 2/5 * log(2/5) ) = 5/14 * 0.971 + 4/14 * 0 + 5/14 * 0.971 = 0.693
特征气温的信息熵为(4个炎热,6个适中,4个寒冷):
h(e|b) = 4/14 * ( -2/4 * log(2/4) - 2/4 * log(2/4) ) + 6/14 * ( -4/6 * log(4/6) - 2/6 * log(2/6) ) + 4/14 * ( -3/4 * log(3/4) - 1/4 * log(1/4) ) = 4/14 * 1 + 6/14 * 0.918 + 4/14 * 0.811 = 0.911
特征湿度的信息熵为(7个高,7个正常):
h(e|c) = 7/14 * ( -3/7 * log(3/7) - 4/7 * log(4/7) ) + 7/14 * ( -6/7 * log(6/7) - 1/7 * log(1/7) ) = 7/14 * 0.985 + 7/14 * 0.592 =0.7885
特征风力的信息熵为(8个弱,6个强):
h(e|d) = 8/14 * ( -6/8 * log( 6/8 ) - 2/8 * log( 2/8 ) ) + 6/14 * ( -3/6 * log(3/6) - 3/6 * log(3/6) ) = 8/14 * 0.5 + 6/14 * 1 = 0.714
其中,h(e) - h(e|a) = 0.247 为信息增益最大
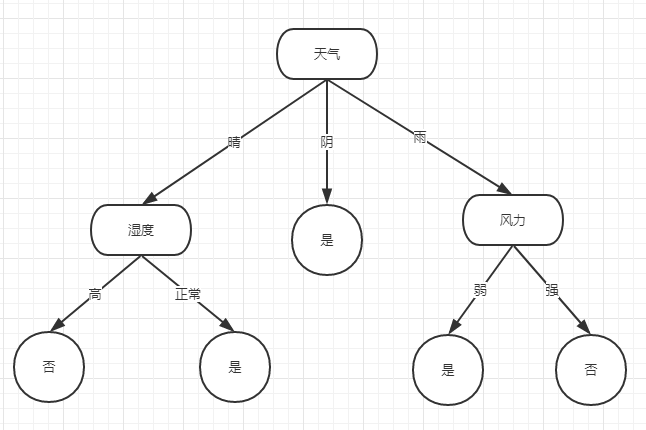
那么对应第一个分裂点为 天气
对应的树结构:
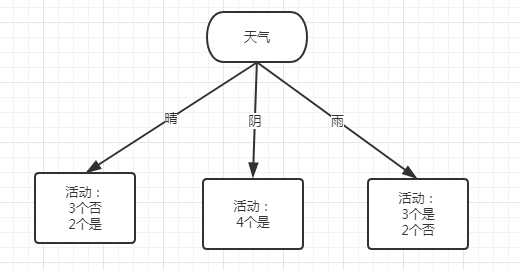
接下来再分别计算各个子节点的分裂属性:
天气特征晴的分支树表:
| 序号 | 气温b | 湿度c | 风力d | 是否活动e |
| 1 | 炎热 | 高 | 弱 | 否 |
| 2 | 炎热 | 高 | 强 | 否 |
| 8 | 适中 | 高 | 弱 | 否 |
| 9 | 寒冷 | 正常 | 弱 | 是 |
| 11 | 适中 | 正常 | 强 | 是 |
特征晴的信息熵为:
h(a) = -2/5*log(2/5) - 3/5*log(3/5) = 0.97
特征气温的信息熵为(2个炎热,2个适中,1个寒冷):
h(a|b) = 2/5 * ( -2/2*log(2/2) ) + 2/5 * ( -1/2 * log(1/2) - 1/2*log(1/2) )+ 1/5( -1/1 * log(1/1) ) = 0.4
特征湿度的信息熵为(3个高,2个正常):
h(a|c) = 3/5 * ( -3/3 * log(3/3) ) + 2/5 * ( -2/2*log(2/2) ) = 0
特征风力的信息熵为(2个强,3个弱):
h(a|d) = 2/5 * ( -1/2 * log(1/2) - 1/2 * log(1/2) ) + 3/5 * ( -1/3 * log(1/3) -2/3*log(2/3) ) = 0.95
增益最大为h(a) - h(a|c)
那么对应分裂特征为 湿度,且此时湿度拥有的信息熵为0,那么已经得出最大增益成立,此时这里也是一个停止分裂点
天气特征阴的分支树表为:
| 序号 | 气温b | 湿度c | 风力d | 是否活动e |
| 3 | 炎热 | 高 | 弱 | 是 |
| 7 | 寒冷 | 正常 | 强 | 是 |
| 12 | 适中 | 高 | 强 | 是 |
| 13 | 炎热 | 正常 | 弱 | 是 |
特征阴的信息熵为:
h(a) = -4/4*log(4/4) = 0
由于本身的信息熵为0,所以特征阴本身不具备二次分裂条件,视为停止分裂点,终结点。
天气特征雨的分支树表为:
| 序号 | 气温b | 湿度c | 风力d | 是否活动e |
| 4 | 适中 | 高 | 弱 | 是 |
| 5 | 寒冷 | 正常 | 弱 | 是 |
| 6 | 寒冷 | 正常 | 强 | 否 |
| 10 | 适中 | 正常 | 弱 | 是 |
| 14 | 适中 | 高 | 强 | 否 |
特征雨的信息熵为:
h(a) = -3/5 * log(3/5) - 2/5 * log(2/5) = 0.97
特征气温的信息熵为(3个适中,2个寒冷):
h(a|b) = 3/5 * ( -2/3 *log(2/3) - 1/3 * log(1/3) ) + 2/5 * ( -1/2 * log(1/2) - 1/2*log(1/2) ) = 0.95
特征湿度的信息熵为(2个高,3个正常):
h(a|c) = 2/5*( -1/2 * log(1/2) - 1/2 * log(1/2) ) + 3/5 * (-2/3 * log(3/2) - 1/3 * log(1/3) ) = 0.95
特征风力的信息熵为(3个弱,2个强):
h(a|d) = 3/5 * ( -3/3 * log(3/3) ) + 2/5*( -2/2 * log(2/2) ) = 0
增益最大为 h(a) - h(a|d) = 0.97 获得信息最大增益,那么分裂特征为 风力,同由于风力信息熵为0,视为最大增益,终结点停止分裂.
依据当前计算,此时对应的决策树如下图所示:
使用C4.5来计算:
老铁,C4.5用的还是信息熵,只是从减法变成了除法,我这就不举例了。
CART算法来计算:
CART使用基尼不纯度来计算,不纯度越低,表示越适合分裂,这里要特殊说明的是,CART算法生成的决策树必须为二叉树,所以在处理多类型(多 指代大于2)离散性数据的时候,需要做分类,将其归为2类,这样的话,递归计算就会比较多,下面例子会有体现。
Gini不纯度计算公式如下:
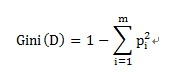
对应特征的Gini不纯度计算公式如下:
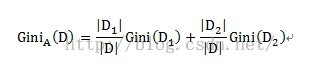
按照我们上面的数据,进行计算:
总Gini不纯度计算:
Gini(是,否) = 1 - (9/14)^2 - (5/14)^2 = 0.459
特征天气的gini不纯度计算:
Gini(晴,阴|雨) = 5/14 * ( 1 - (2/5)^2 - (3/5)^2) + 9/14 * ( 1 -(7/9)^2 - (2/9)^2 ) = 0.394
Gini(阴,晴|雨) = 4/14 * ( 1 - (2/4)^2 - (2/4)^2) + 10/14 * (1 -(6/10)^2 - (4/10)^2 ) = 0.486
Gini(雨,晴|阴) = 5/14 * ( 1 - (3/5)^2 - (2/5)^2) + 9/14 * ( 1 - (6/9)^2 - (3/9)^2 ) = 0.457
特征气温的Gini不纯度计算:
Gini(炎热,适中|寒冷) = 4/14 * ( 1 - (2/4)^2 - (2/4)^2 ) + 10/14 * ( 1 - (7/10)^2 - (3/10)^2 ) = 0.443
Gini(适中,炎热|寒冷) = 6/14 * ( 1 - (4/6)^2 - (2/6)^2) + 8/14 * ( 1 - (6/8)^2 - (2/8)^2 ) ) = 0.405
Gini(寒冷,炎热|适中) = 4/14 * ( 1 - (3/4)^2 - (1/4)^2) + 10/14 * ( 1 - (6/10)^2 - (4/10)^2 ) ) = 0.45
特征湿度的Gini不纯度计算:
Gini(高,正常) = 7/14 * ( 1 - ( 3/7 )^2 - (4/7)^2 ) + 7/14 * ( 1 - (6/7)^2 - (1/7)^2 ) = 0.367
特征风力的Gini不纯度计算:
Gini(弱,强) = 8/14 * ( 1 - (6/8)^2 - (2/8)^2 ) + 6/14 * ( 1 - (3/6)^2 - (3/6)^2 ) = 0.429
其中,根据湿度的Gini指数最小,最适合分裂。
对应Gini差值:Gini(D) - Gini_A(D) = Gini(是,否) - Gini(高,正常) = 0.092
那么第一个分裂点为湿度.
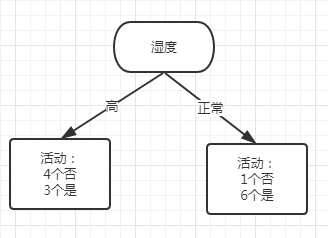
以湿度高分裂的子数据如下(左侧第一次分裂):
| 序号 | 天气a | 气温b | 湿度c | 风力d | 是否活动e |
| 1 | 晴 | 炎热 | 高 | 弱 | 否 |
| 2 | 晴 | 炎热 | 高 | 强 | 否 |
| 3 | 阴 | 炎热 | 高 | 弱 | 是 |
| 4 | 雨 | 适中 | 高 | 弱 | 是 |
| 8 | 晴 | 适中 | 高 | 弱 | 否 |
| 12 | 阴 | 适中 | 高 | 强 | 是 |
| 14 | 雨 | 适中 | 高 | 强 | 否 |
特征湿度的Gini指数:
Gini(是,否) = 1 - (3/7)^2 - (4/7)^2 = 0.49
特征天气计算Gini指数:
Gini(晴,阴|雨) = 0 + 4/7 * ( 1 - (3/4)^2 - (1/4)^2 ) = 0.214
Gini(阴,晴|雨) = 2/7*(1 - (2/2)^2 ) + 5/7*( 1 - ( 1/5 )^2 - ( 4/5)^2 ) = 0.229
Gini(雨,晴|阴) = 2/7*(1 - (1/2)^2 - (1/2)^2 ) + 5/7*(1 - (2/5)^2 - (3/5)^2 ) = 0.486
特征气温计算Gini指数:
Gini(炎热,适中) = 3/7 * ( 1 - (1/3)^2 - (2/3)^2 ) + 4/7 * ( 1 - (2/4)^2 - (2/4)^2 ) =0.476
特征风力计算Gini指数:
GIni(弱,强) = 4/7 * (1-(2/4)^2 - (2/4)^2) + 3/7 * ( 1-(1/3)^2 -(2/3)^2 ) = 0.476
根据计算所得其中天气Gini(晴,阴|雨)=0.214为最小,第二次在湿度高分裂子支的分裂特征为天气,且由于天气离散变量为3个,此次分裂归类为{晴,阴|雨}
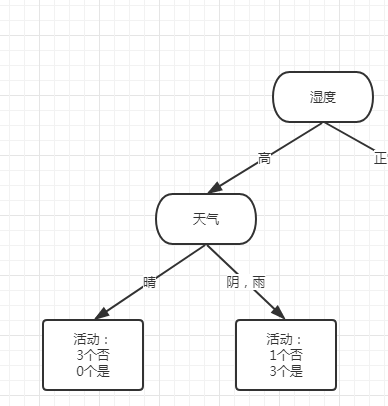
继续计算是否具有第三分裂点,其实直接就可以从数据看出来,左侧天气为晴的时候,只有否,那么其实计算Gini指数的时候,只会得出Gini(x) = 0,此时就会停止分裂,我这里就不继续算下去了。
对应阴雨的数据集为:
| 序号 | 天气a | 气温b | 风力d | 是否活动e |
| 3 | 阴 | 炎热 | 弱 | 是 |
| 4 | 雨 | 适中 | 弱 | 是 |
| 12 | 阴 | 适中 | 强 | 是 |
| 14 | 雨 | 适中 | 强 | 否 |
Gini(是,否) = 1 - (1/4)^2 - (3/4)^2 = 0.375
由于此时天气还具有可分类属性,那么继续计算天气的Gini值:
Gini(阴,雨) = 2/4 * ( 1 - (2/2)^2 ) + 2/4 * ( 1 - ( 1/2 )^2 - ( 1/2 )^2 ) = 0.25
特征气温的Gini指数:
Gini(炎热,适中) = 1/4 * (1 - (1/1)^2 ) + 3/4 * ( 1 - (2/3)^2 - (1/3)^2 ) =0.333
特征风力的Gini指数:
Gini(弱,强) = 2/4 * (1 - (2/2)^2 ) + 2/4*( 1 - (1/2)^2 - (1/2)^2) =0.25
虽然天气和风力Gini指数相同,但天气是在上一分裂属性下的,这里优先继承天气分裂.
此次分裂情况为:
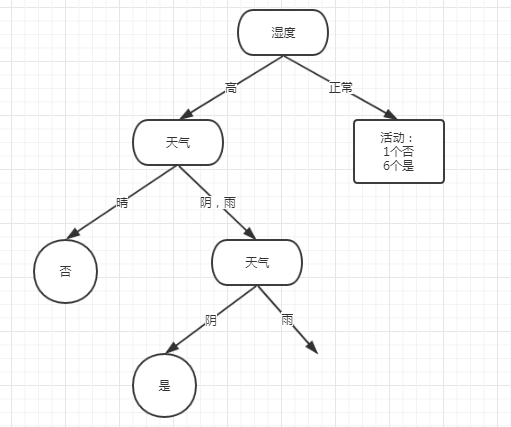
再往下我不一一列出来了,其实可以看出,也能轻易计算出来,阴天全部结果为是,Gini指数为0,达到分裂终点,雨天还要继续计算。
而雨天的数据集如下,太明显了:
| 序号 | 天气a | 气温b | 风力d | 是否活动e |
| 4 | 雨 | 适中 | 弱 | 是 |
| 12 | 雨 | 适中 | 强 | 否 |
Gini(是,否) = 1 - (1/2)^2 - (1/2)^2 = 0.5
Gini(适中) = 0.5
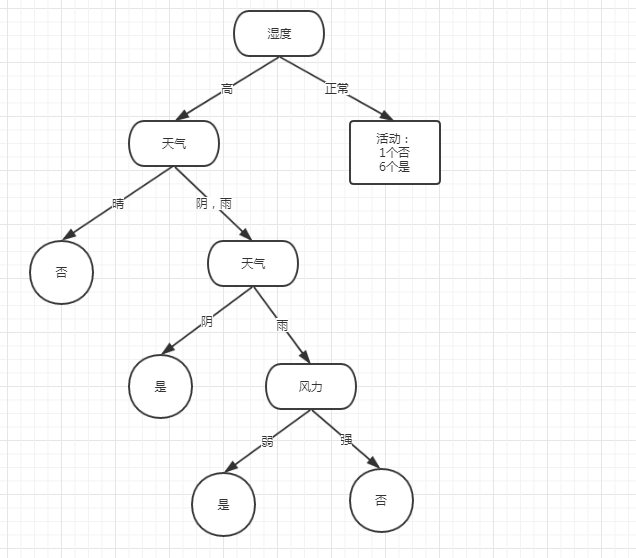
Gini(弱,强) = 0
如数据表示,使用风力来分裂,完美,而且都到达了分裂终点。
如下:
以湿度正常分裂的子数据如下(右边第一次分裂):
| 序号 | 天气a | 气温b | 湿度c | 风力d | 是否活动e |
| 5 | 雨 | 寒冷 | 正常 | 弱 | 是 |
| 6 | 雨 | 寒冷 | 正常 | 强 | 否 |
| 7 | 阴 | 寒冷 | 正常 | 强 | 是 |
| 9 | 晴 | 寒冷 | 正常 | 弱 | 是 |
| 10 | 雨 | 适中 | 正常 | 弱 | 是 |
| 11 | 晴 | 适中 | 正常 | 强 | 是 |
| 13 | 阴 | 炎热 | 正常 | 弱 | 是 |
我这里就不再像左边那样,每一次分裂数据集都表示了,直接给出计算结果:
Gini(是,否) = 1 - ( 1/7 )^2 - (6/7)^2 = 0.245
Gini(晴,阴|雨)= 5/7 * ( 1 - ( 1/5 )^2 - (4/5)^2 ) = 0.229
Gini(阴,晴|雨)= 5/7 * ( 1 - ( 1/5 )^2 - (4/5)^2 ) = 0.229
Gini(雨,晴|阴)= 3/7 * ( 1 - ( 1/3 )^2 - (2/3)^2 ) = 0.190
Gini(寒冷,适中|炎热)= 4/7 * ( 1 - (1/4)^2 - (3/4)^2 ) = 0.214
Gini(适中,寒冷|炎热)= 5/7 * ( 1 - (1/5)^2 - (4/5)^2 ) = 0.229
Gini(炎热,寒冷|适中)= 6/7 * ( 1 - (1/6)^2 - (5/6)^2 ) = 0.238
Gini(弱,强)= 3/7 * ( 1 - (1/3)^2 - (2/3)^2 ) = 0.190
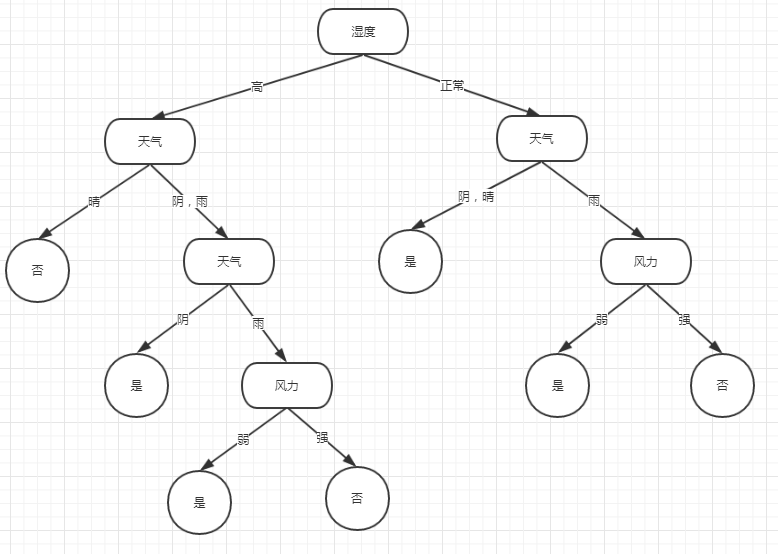
风力和天气(雨,阴|晴)具有相同的基尼指数,但通过计算就会发现,如果选用天气(雨,阴|晴)做分裂点,那么 阴|晴 直接会出现为终结点(Gini=0),再用雨天的数据,做一次分裂,就可以完成决策树,等于从此时开始,2次分裂完成任务,而如果使用风力作为分裂点,虽然第一层也会出现一个终结点,但另一边就会出现特征计算繁琐,必定要做3次分裂(因为天气有3个值,且雨天必做分裂,气温寒冷时还需要再做分裂),所以此时第二次分裂点(右边)选择为天气(雨,阴|晴)。
Gini(阴|晴)=0,为分裂终点。
雨天的数据集如下:
| 序号 | 天气a | 气温b | 风力d | 是否活动e |
| 5 | 雨 | 寒冷 | 弱 | 是 |
| 6 | 雨 | 寒冷 | 强 | 否 |
| 10 | 雨 | 适中 | 弱 | 是 |
Gini(是,否) = 1 - (1/3)^2 - (2/3)^2 = 0.444
Gini(寒冷,适中) = 2/3 * ( 1 - (1/2)^2 - (1/2)^2 ) = 0.333
Gini(弱,强) = 0
选择风力分裂Gini(弱,强)=0,终结点出现了,完美。
那么此次决策树总体为:
接下来使用sklearn的库来代码实现,有库的好处就体现在这,明白了原理,知道人家方法和你一样,就省下了造轮子的时间:
使用到的库为:
import pydotplus
from sklearn import tree定义离散数据对应值:
def getDataVar(i):
data = {
"晴": 0, "阴": 1, "雨": 2,
"炎热": 0, "适中": 1, "寒冷": 2,
"高": 0, "正常": 1,
"强": 0, "弱": 1,
"否": 0, "是": 1
}
return data[i]
训练模型:
def run():
x = \
[
[getDataVar("晴"), getDataVar("炎热"), getDataVar("高"),getDataVar("弱")],
[getDataVar("晴"), getDataVar("炎热"), getDataVar("高"), getDataVar("强")],
[getDataVar("阴"), getDataVar("炎热"), getDataVar("高"), getDataVar("弱")],
[getDataVar("雨"), getDataVar("适中"), getDataVar("高"), getDataVar("弱")],
[getDataVar("雨"), getDataVar("寒冷"), getDataVar("正常"), getDataVar("弱")],
[getDataVar("雨"), getDataVar("寒冷"), getDataVar("正常"), getDataVar("强")],
[getDataVar("阴"), getDataVar("寒冷"), getDataVar("正常"), getDataVar("强")],
[getDataVar("晴"), getDataVar("适中"), getDataVar("高"), getDataVar("弱")],
[getDataVar("晴"), getDataVar("寒冷"), getDataVar("正常"), getDataVar("弱")],
[getDataVar("雨"), getDataVar("适中"), getDataVar("正常"), getDataVar("弱")],
[getDataVar("晴"), getDataVar("适中"), getDataVar("正常"), getDataVar("强")],
[getDataVar("阴"), getDataVar("适中"), getDataVar("高"), getDataVar("强")],
[getDataVar("阴"), getDataVar("炎热"), getDataVar("正常"), getDataVar("弱")],
[getDataVar("雨"), getDataVar("适中"), getDataVar("高"), getDataVar("强")]
]
y = [getDataVar("否"),getDataVar("否"),getDataVar("是"),getDataVar("是"),getDataVar("是"),
getDataVar("否"),getDataVar("是"),getDataVar("否"),getDataVar("是"),getDataVar("是"),
getDataVar("是"),getDataVar("是"),getDataVar("是"),getDataVar("否")]
feature_list = ["weather","temperature","humidity","wind"]
target_list = ["yes","no"]
print(x,y)
#训练模型 criterion= "entropy" id3算法,无则是gini算法
# clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = tree.DecisionTreeClassifier()
# print(clf.create_tree(x, y, feature_list))
clf = clf.fit(x,y)
with open("iris.dot",'w') as f:
f = tree.export_graphviz(clf,out_file=f,feature_names=feature_list,class_names=target_list)
print(clf.predict([[getDataVar("阴"), getDataVar("炎热"), getDataVar("正常"), getDataVar("弱")]]))
# dot = StringIO()
# tree.export_graphviz(clf,out_file=dot)
# graph = pydotplus.graph_from_dot_data(dot.getvalue())
graph = pydotplus.graph_from_dot_file("iris.dot")
graph.write_png("iris.png")
值得注意的是,sklearn中,使用的是cart算法来实现的决策树,虽然可以使用参数(criterion="entropy")来计算信息熵,但还是只能分裂成为2叉树,但计算方法同id3一样,只不过分类方法借鉴了cart。
以下是代码生成的决策树的图:
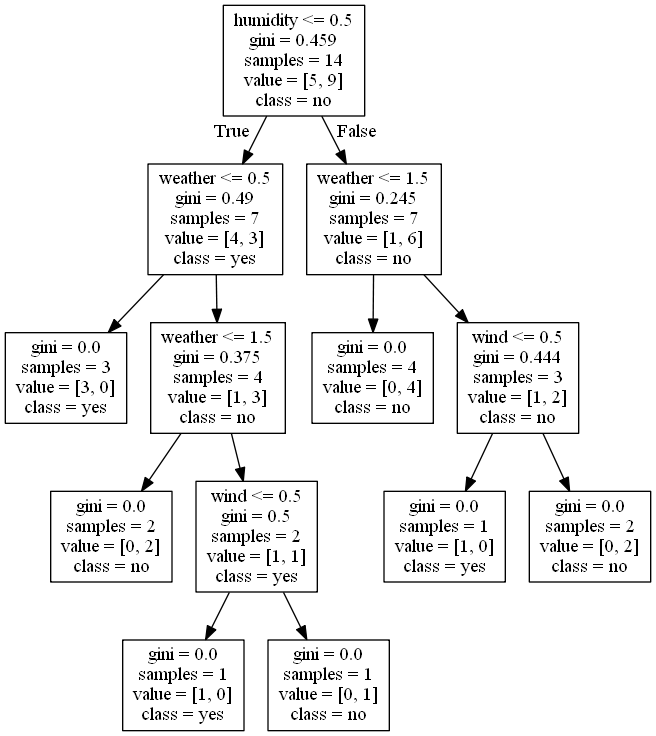
图中每一个框中gini指数对应样本结果的指数,也就是对应我手算的各个节点的Gini(是,否)指数。
可以看出,使用sklearn分裂的结果和我手算推出的结果一毛一样。