决策树的构成:一个根结点和若干个内部结点以及叶子结点构成,每一个叶子结点对应着一个分类类别,其他结点
对应的一次决策(如下图黄色结点为分类的最后结果,绿色结点为决策结点);
适用范围:比较适合分析离散的数据(若是连续的数据可将其离散化进行处理),如下图就是一颗决策树;

信息熵:某条信息的信息量的大小与它的不确定性有直接关系,为了弄明白一个(不确定)事情,需要有大量的数据
熵就是来度量事件的不确定性的大小(熵越大,事件的不确定性越大,反之越小)
信息熵公式: (p为事件发生的概率,该式子是所有事假的和)
(p为事件发生的概率,该式子是所有事假的和)
例子:计算普通掷骰子的信息熵(每一个点数出现的概率都相同为1/6)
套用上述公式很简单可以得出此骰子的信息熵为log2(6),试想若骰子的每一个点数都为6,则信息熵为0(确定事件)
信息增益公式: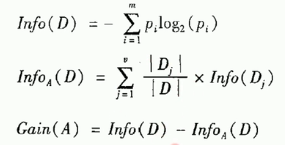 ,这里的第一个式子就是所有结果的信息熵(该事件的)
,这里的第一个式子就是所有结果的信息熵(该事件的)
假设离散属性A有 j 种取值,利用属性A对事件进行决策会产生 j 个分支结点(如上图决策树中收入属性有三种取值
高中低,产生三个分支结点),Dj 为第 j 个分支结点中的属性A取值为a[j]的所有样本 |Dj|/|D|表示分支权重;
举个栗子:(如下图所示计算age的信息增益)

首先计算信息熵有两种结果yes和no,no有5个,yes有9个,总数据为14个,由此我们可计算出信息熵为:
![]()
下面我们来计算age属性字段的信息增益:(一共有3个取值年轻youth、middle、semior)
youth一共有5个,middle有4个,senior有5个,则这几个分支的权重依次为5/14、4/14、5/14,下面我们就要计算在每个
属性取值的内部的信息熵之后乘以其对应的权重求和即可。
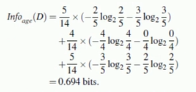
最后做差值即可得到age属性字段的信息增益:![]()
信息增益越大,说明用此属性进行决策划分的确定性越高,可采用信息增益来对决策树进行划分(如ID3算法)
基尼数(用于决策树的划分)公式: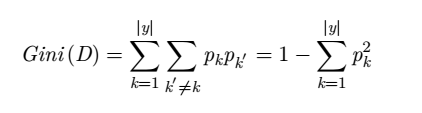 ;
;
(注:基尼指数值越小,说明此事件的确定性越高(同信息熵类似))
CART算法采用基尼指数划分对属性进行划分
属性a的基尼指数公式: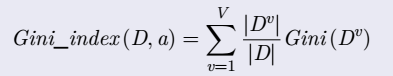 ;
;
决策树实战(Fight)西瓜书好坏瓜的区分
#导入模块
import numpy as np
from sklearn import tree
import pydotplus
import graphviz
x_data=[]#数据集
y_data=[]#特征集
text=[]#标题栏
index=0数据集合获取(数据处理)
#数据集合获取
with open('DT.txt') as f:
for line in f:
line = line.strip('\n').split(',')
if index==0:
text.append(line)
index=1
else:
x_data.append([line[0],line[1],line[2],line[3],line[4],line[5]])
y_data.append([line[6]])模型生成(借助sklearn实现)
#决策树模型
model=tree.DecisionTreeClassifier(criterion='entropy')
model.fit(x_data,y_data)决策树绘制(pydotplus与graphviz的应用)
#绘制决策树
dot=tree.export_graphviz(model,out_file=None,feature_names=['color', 'root', 'voice', 'outlook', 'navel', 'touch'],class_names=['true','false'])
graphtree=graphviz.Source(dot)
graphtree.render('DTree')
测试数据集合(用0,1,2代指各个属性的所表示的含义)
第一列:0代表青绿、1代表乌黑、2代表浅白;第二列:0代表蜷缩、1代表稍蜷、2代表硬挺;
第三列:0代表浊响、1代表沉闷、2代表清脆;第四列:0代表清晰、1代表稍糊、2代表模糊;
第五列:0代表凹陷、1代表稍凹、2代表平坦;第六列:0代表硬滑、1代表软粘;第七列:1代表好瓜,0代表坏瓜;
1-6列属性名分别为:color,root,voice,outlook,navel,touch
color,root,voice,outlook,navel,touch,result
0,0,0,0,0,0,1 #
1,0,1,0,0,0,1 #
1,0,0,0,0,0,1 #
0,0,1,0,0,0,1 #
2,0,0,0,0,0,1 #
0,1,0,0,1,1,1
1,1,0,1,1,1,1
1,1,0,0,1,0,1 #
1,1,1,1,1,0,0 *
0,2,2,0,2,1,0
2,2,2,2,2,0,0 *
2,0,0,2,2,1,0
0,1,0,1,0,0,0 *
2,1,1,1,0,0,0 *
1,1,0,0,1,1,0
2,0,0,2,2,0,0 *
0,0,1,1,1,0,0 *
下面结合数据集分别对图中的字段(结点做出解释):外观清晰&触感硬滑的瓜都是好瓜(已在数据集中用"#"标识),外观不清晰&表面硬滑的瓜都是坏瓜(已在数据集中用"*"标识);第一个参数是对其进行决策的参数,通过取值的不同进入不同的分支结点重新进行决策。sample表示满足此条件的数据个数,value用于记录正反决策的个数,class表示所属类别;entropy为信息熵(当为0时表示确定的事件,越大事件的不确定性越大)
