决策树概要
- 决策树的构造
- ID3算法介绍
- 信息熵与信息增益
- 决策树的优缺点
决策树的构造
依决策树是托决策而建立起来的一种树。决策树是一个预测模型,代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
选择属性,确定特征属性之间的拓扑关系。
- 关键:分裂属性
- 属性是离散值且不要求生成二叉决策树。此时使用属性的每一个划分作为一个分支。
- 属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
- 属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<split_point生成两个分支。
属性的选择-----自顶向下,贪婪递归
- 分裂准则
- 信息增益最大化
- 计算各属性的信息增益
- 选择具有最大信息增益的属性作为第一个分裂点
- 继续对中间数据集重复1.


ID3算法介绍
ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。因为信息增益越大,区分样本的能力就越强,越具有代表性,所以该算法采用自顶向下的贪婪搜索遍历可能的的决策空间。
ID3的缺陷与改进:
- 偏向性:倾向于选择多值属性。
- 解决方案:信息增益率(C4.5)
- 引入分裂信息:
- 增益
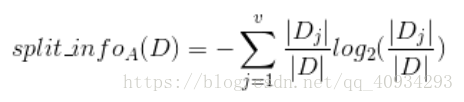
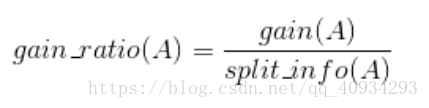
信息熵与信息增益
信息的定义:如果待分类的事务可能划分在多个分类之中,则符号xi的信息定义为:l(xi)=-log2p(xi);其中p(xi)是选择该分类的概率。
信息熵则是定义为信息的期望值。
假如一个随机变量
的取值为
,每一种取到的概率分别是
,那么
的熵定义为
意思是一个变量的变化情况可能越多,那么它携带的信息量就越大。
对于分类系统来说,类别
是变量,它的取值是
,而每一个类别出现的概率分别是
而这里的
就是类别的总数,此时分类系统的熵就可以表示为
信息增益是针对一个一个特征而言的,就是看一个特征
,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。
信息增益的计算公式如下
其中
为全部样本集合,
是属性
所有取值的集合,
是
的其中一个属性值,
是
中属性
的
值为
的样例集合,
为
中所含样例数。




决策树的优缺点
优点:可解释性强;无需数据预处理;能同时处理数值型和常规数据类型;对缺失值不敏感;可以处理不相关特征数据。
缺点:可能会产生过度匹配问题
适用数据类型:数值型和标称型
解决产生过度匹配问题:通过裁剪决策树,合并相邻的无法产生大量信息增益的叶节点