这是一篇讲解图像类比(Image Analogy)的文章。
给定一组图片:A和B'。A提供语义Semantic(“是什么”)和内容Content(如图片的哪个位置会有这个object的什么,其形状和大小是怎样的)两大主要信息,B'则主要提供外观性Appearance(如颜色、光照、风格)和细节(主要是纹理)两个大信息。

接下来,我们要做的就是把两张图片都划分为固定大小的patch,然后把色块从B'映射到A中与这个色块最相近(衡量两个色块相近程度的方式在后面说)的色块的位置,取代它。换句话说,我们把A里的每一个色块用B'中与之最相近的同样大小的块来代替。那么,当每一个色块patch足够小的时候,并且我们在全部替代完成后做smooth等操作,那么就相当于我们用B’的风格来表现A,在这个例子中就相当于完成了风格迁移!结果如 所示!


反过来,我们也可以用 的语义和内容,加上
的细节与外观生成
主导但是属于
风格的
。于是我们在给定两张图片的情况下,就有了下面的图片公式——

这就是图像类比: 到
的映射应该和
到
的映射方式是一样的!这就相当于我们初中学的等比例公式:
.
基本思想与任务是这样子的。下面进入正题。
(一)与PatchMatch的比较
本文的基本思想与PatchMatch是一样的 ;不同在于我们对patch之间衡量相似度时,度量的量不同。如果我们仅仅是对于图片的像素值(Lowest feature)进行计算——如对于每一个pixel的RGB三个值组成的列向量作差后求模,作为两个patches之间的差距,那就是PatchMatch的工作;但如果我们计算的对象是经过深度卷积网络提取的到的特征(
),在HW平面对每一个位置跨过所有的
个channels组成的
列向量作差后求模,就是这篇文章的做法了。
我们知道,CNN能够有效的提取图片的高纬度复杂的特征,这正是机器学习所需要的!这些特征有利于我们在高维空间上对问题进行简化。
(二) 基本思路
先预训练好一个VGG19网络,我们取前面的卷积部分,让它返回每一个Conv block后面的激活处理后的输出(共5个,
).
其次,我们应该理解:VGG从第一层到第五层,精度降低,图片细节丢失,在最高层主要包含的是“语义信息”即“这张图里有什么”。那么,我们完全有理由认为:在最高层的时候, 与
是等同的,
到
也是等同的,即——
,
接下来的工作既没有涉及到深度学习的了,而是对每一次pair的输入做一次推导,最后得到我们要生成的图片 和
。
1. 核心模块——基于预训练VGG19的输出特征作“特征对齐”
特征对齐的主要算法是NNF(Nearest Neighbor Field: 最近邻算法),实现算法是依靠暴力的遍历穷举所有配对方式,找到使得定义的度量方式最小的那一个。毫无疑问,对于图像,我们需要嵌套4个循环,这导致我们假设图片大小为 的话,计算复杂度为:
。具体的实现细节可以参考论文的代码:
这里我们强调的是patch之间相似度的度量方式,如下面公式——
这里需要注意:如第三组图所示,我们结合 与
生成
,也可以生成
。其不同在于前者是
作为“容器”,
作为填充;后者是
作为“容器”,
作为填充。之所以要这么做,是为了“双向验证”,同时有数据增强的作用。
此外,上式中的配对方式,为什么不是 与
配对,而
与
配对?
这样的匹配方式是为了更方便的学习,因为 和
仅是在location/content structure上的不同,
和
也仅是在location/content structure的不同;而反观
和
则不仅存在ocation/content structure上的不同,还存在appearance/detail 的不同。而依靠像素值及其特征的作差是很难同时消除颜色等的不同带来的干扰的,甚至可能会误导网络错误将不同的appearance属性混在一起;所以这里来使用
和
配对。
2. 核心模块——基于层次结构的从粗到精的图像对齐与生成
在步入正题之前,我们需要先理解一下本文的基本思想,如下图所示: 从最高层的抽象特征反过来推导到最开始一层,那么最开始的层就是应该是形象的目标图像!
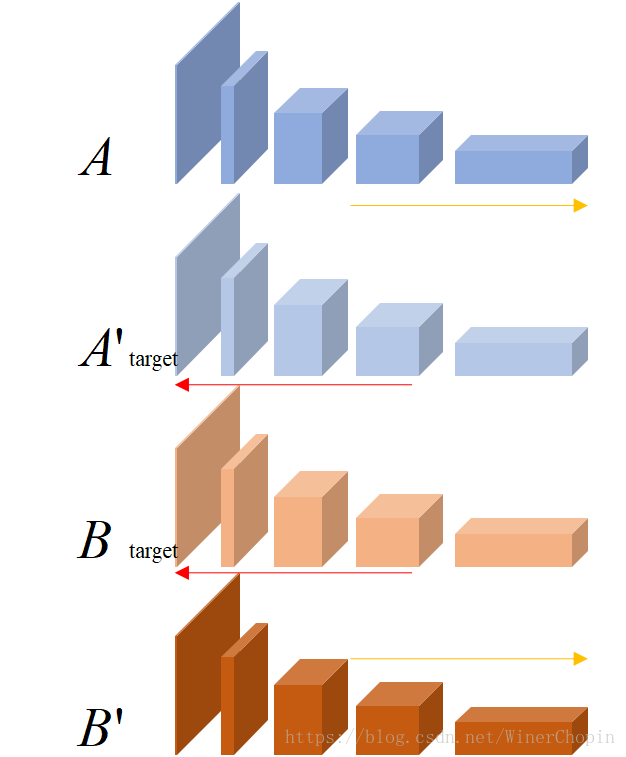
假设现在在VGG的最后一层输出, 和
对应的特征记为:
和
。基于上面的假设,我们有理由认为
,
由于度量方式的要求我们需要在每一层先知道这一层的四个变量,那么,在层我们很容易得到这四个量,进而我们可以求解在这一层图像类比的映射关系:
1),其作用是,对于
中的每个patch
,在
上找到一个距离与之最小的patch
2),其作用是,
对于
中的每个patch ,在
上找到一个距离与之最小的patch
下面我们希望找到 层的映射关系,如下图所示:我们以基于
利用
生成
为例,
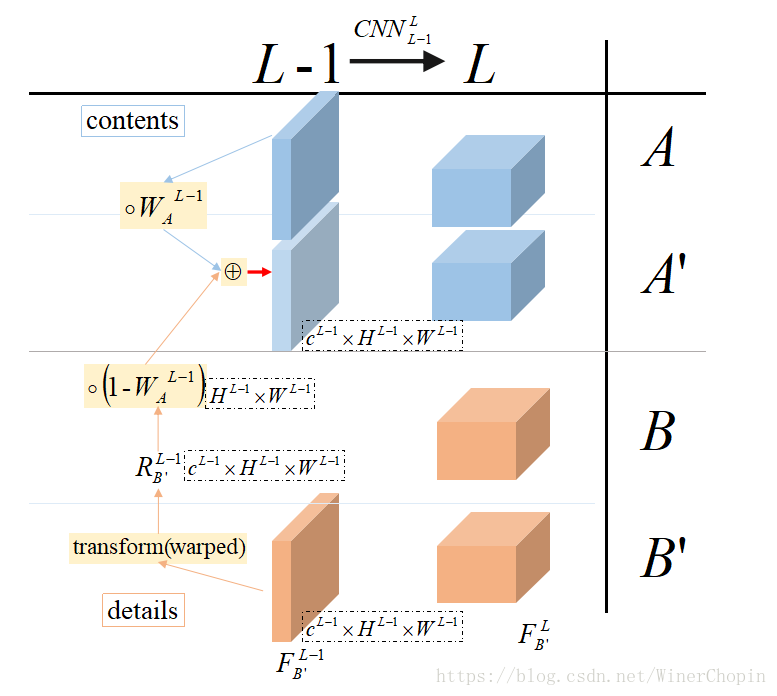
其中,是
为了在内容结构上与
相似而做了一次patch的重构得到的特征;
是一个二维矩阵,每个元素的值介于0~1之间,只为了权衡在这个位置结构和细节的占比。
即:是基于
和
在
层特征杂糅起来的。
下面我们讲解和
的求解——
内容结构重构的直观理解如下组图:我们把中间的图结构上重构了一下,就有了左边第一张图的大概样子,联系到我们的工作,这样一来我们就只要进行提供细节的填充到提供结构的
上去就好了。



对,这就是我们要求的,即
,在理想情况下
但是遗憾的是是我们不知道的,所以我们才需要基于
去求解。但是我们知道了
,这让我们可以反过来求解。我们构造一个回归问题:
其中,表示的是与VGG19相同结构的、从
层映射的参数(结构相同,但参数不是预训练的的参数),我们要重新优化,在单独这一层达到收敛。至于
,括号内是位置信息,是将
映射到
后的位置,那么整一个就是对应位置信息在
对应位置的值,恰好就是
。至于为什么不用
,是有原因的,基于这篇文章的任务决定的,因为我们希望
和
尽可能交叉,这样才能实现“融合”的目的,
是基于四个量求得的,而
则是单独的,明显不怎么好。
至于,就比较简单了。如下图所示:

1)拿到,在HW平面对每一个位置跨过所有channels做归一化
2)求均值,然后我们得到,这个2-dim矩阵衡量的是:特征
在各个位置的响应程度
3)对每个元素乘以一个超参数
同理我们可以求出。
这样我们就知道了层的四个量:
,
,
,
,于是我们可以求解这一层的图像类比映射关系了。
不过,我们会先把层的映射关系上采样来初始化
层的映射关系,在这个基础上,用这一层的四个量进行fine-tune.
等我们反推导到第一层的时候,我们得到和
,那就是我们希望获得的图片了。
(三)算法伪代码

图中小编已经将基本结构做了标注,应该更便于阅读理解。关于论文PDF上更多注释请参考:
(四)效果展示
1. 照片风格迁移

2. 风格交换

3.图画转相片

4.照片与照片风格交换

(五)模型失效

- 失败1:对于一张图上有的object另一张图上找不到的(左上)
- 失败2,对于那些语义上相同但appearance上有很大不同的(右上)
- 失败3,对于那些自然中不大可能出现的动作、表情,毕竟这是基于大数据统计学习得到的(左下)
- 失败4,对于几何位置的迁移(右下)