这篇文章是阿里18年发的,非常经典的一个模型。paper链接
摘要
点击率预测是在线广告等工业应用中的一项基本任务。 最近,已经提出了基于深度学习的模型,该模型遵循类似的Embedding&MLP范例。在这些方法中,首先将大规模稀疏输入特征映射到低维嵌入向量,然后以逐组方式转换为固定长度向量,最后将它们连接在一起以馈入多层感知器(MLP)以学习非线性功能之间的关系。这样,无论候选广告是什么,用户特征都被压缩为固定长度的表示向量。固定长度向量的使用将成为瓶颈,这将使Embedding&MLP方法难以从丰富的历史行为中有效捕获用户的各种兴趣。在本文中,我们提出了一个新颖的模型:深度兴趣网络(DIN),它通过设计一个本地激活单元来适应性地学习用户兴趣的表示,从历史行为到某个广告,来解决这一挑战。该表示向量在不同广告上有所不同,极大地提高了模型的表达能力。此外,我们开发了两种技术:知道小批量的规则化和数据自适应激活功能,可以帮助训练具有数亿个参数的工业深度网络。在两个公开数据集以及一个拥有超过20亿个样本的阿里巴巴实际生产数据集上的实验证明了所提出方法的有效性,与最先进的方法相比,它们具有更高的性能。现在,DIN已成功部署在阿里巴巴的在线展示广告系统中,为主要业务量服务。
中间引言和背景介绍略过,有兴趣的同学可以自己阅读看看
4、深度兴趣网络
与主动搜索不同,用户进入展示广告系统时没有明确表达其意图。 建立CTR预测模型时,需要有效的方法来从丰富的历史行为中提取用户兴趣。 描绘用户和广告的功能是广告系统点击率建模的基本元素。 合理利用这些功能并从中挖掘信息至关重要
4.1 特征表示
在工业级CTR预估任务中,数据通常是多组类目形式的,例如 [ weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book ] ,通常会转为高维稀疏的0-1二值特征。数学上,编码第 个特征组为向量 , 代表这个特征向量的维度,也表示这个特征群组里有 个唯一的 id。 表示 的第 个元素, , ,如果 =1,则 是one-hot,否则是multi-hot,于是每个样本就可以表示为 , 表示特征组数, , 是整个向量空间的维度,因此,以四个特征组的样本为例,
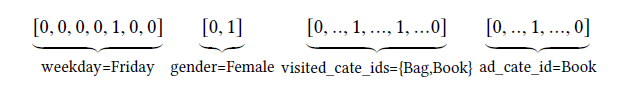
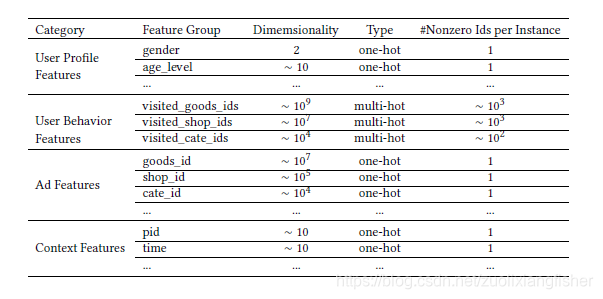
上图是本文所用的全部类型特征。
4.2 base 模型(Embedding & MLP)
当前比较流行的深度模型[1, 2, 3] 都会分享一个类似的 Embedding&MLP 的例子,就像我们本文用到的 base 模型,如下图所示,主要包含几个部分。
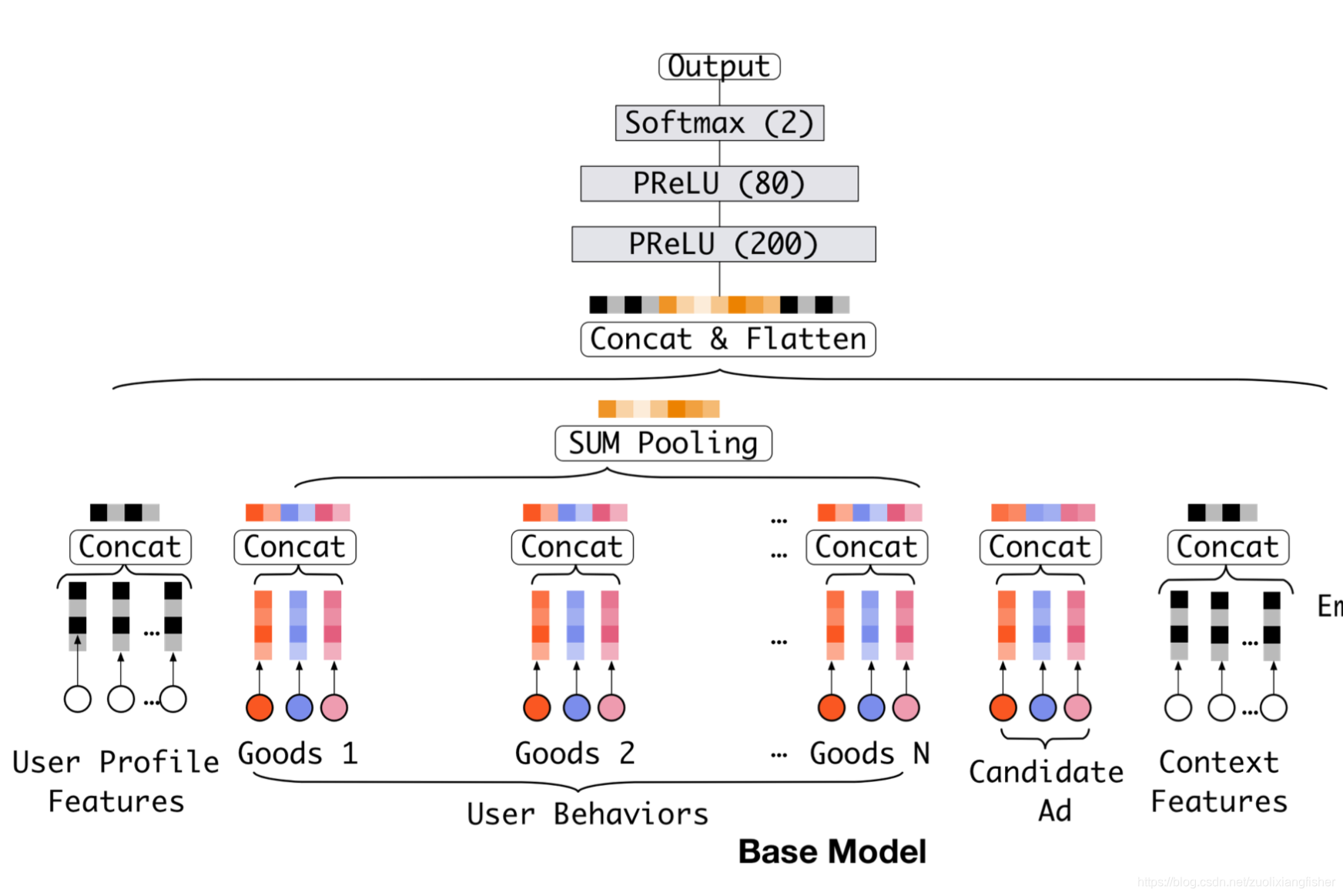
Embedding Layer
输入是高维的二值向量,通过embedding 层转为低维的稠密向量,对于
的第
个特征组,令
表示第
个表征字典,其中
是一个D维的表征向量,表征操作遵循查表机制。
- 如果 是 one-hot 向量且第 个元素 ,那么 的表征是单表征向量
- 如果 是 multi-hot 向量,其中 对于 ,则 的表征是一系列表征向量
Pooling layer and Concat layer
注意点不用的用户会有不同数量的行为,因此,multi-hot 行为特征向量
的非零值的数量会因实例而异,从而导致相应的嵌入向量列表的长度可变,而全连接网络只能接受固定长度的向量,因此,需要添加一个池化层来获取固定长度向量:
这里最常用的两个pooling 是max pooling 和average pooling。embedding层和池化层均以逐组方式进行操作,将原始的稀疏特征映射到多个固定长度的表示向量中。 然后将所有向量连接在一起以获得该实例的整体表示向量。
MLP
给定拼接后的稠密向量,全连接层将自动学习这些组合特征,近期[3,4] 为了更好地抽取特征,重点设计了MLP的结构。
Loss
base 模型里的目标函数是负对数似然函数:
其中
是大小为
的训练集,
是输入,
是标签,
是经过 softmax 层之后整个网络的输出,代表被点击的概率。

4.3 深度兴趣网络结构
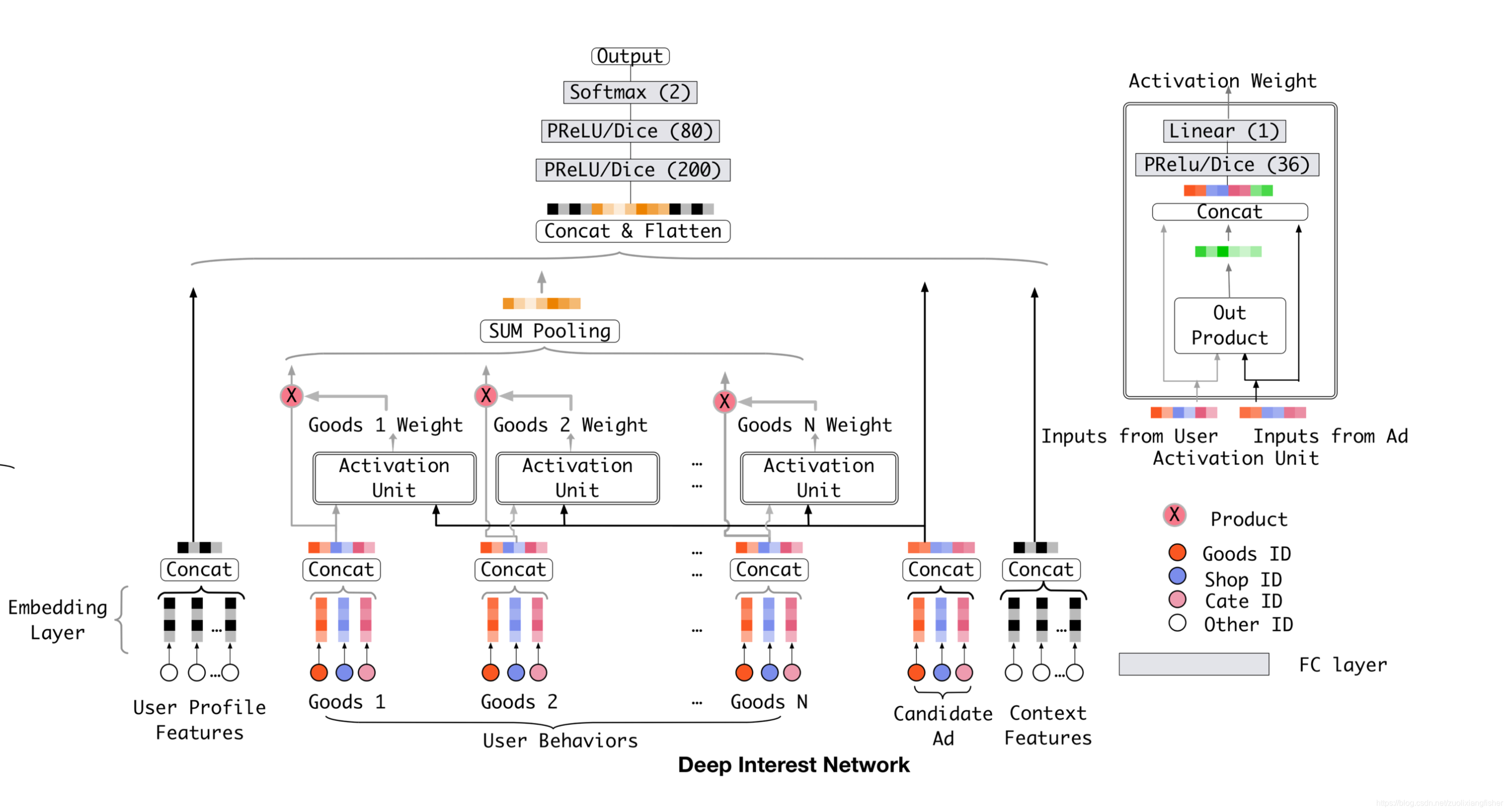
在表1的所有特征里,用户行为特征是非常重要的,在电子商务场景的建模中发挥了核心的作用。
base模型通过对用户行为特征组里的特征的表征向量做池化,得到了固定长度的用户兴趣表征向量,对于给定的一个用户,不管广告位展示什么,表征向量都是固定不变的,这样的话,有限维度的表征将会成为表达用户兴趣多样性的一个瓶颈,为了有更好的包容性,就得增加向量维度,但是这样导致参数成倍增加,对于有限的训练数据集来说会导致过拟合,并且增加额外的存储和计算消耗,对于一个工业级的线上系统是无法容忍的。
在有限维度表征下是否有更好的表达用户兴趣多样性的方法?用户兴趣的局部激活特性给我们带来启发,设计了一个新的模型称为深度兴趣网络。想象一下,当上面第3节中提到的年轻母亲访问电子商务站点时,她发现显示的新手袋很可爱,然后单击它。 让我们来分析一下点击动作的驱动力。 展示的广告通过软搜索她的历史行为并发现她最近浏览过类似的手提袋和皮革手提袋商品,从而引起了这位年轻母亲的相关兴趣。换句话说,与展示广告相关的行为极大地影响了点击操作。 DIN通过关注局部激活兴趣的表征来模拟此过程。关于给定的广告, DIN不会通过使用相同的向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表征向量。 对于候选广告,此表征向量随不同广告而变化。
DIN引入了一个新的局部激活单元,同时保留了其余和base model相同的结构。特别地,激活单元应用在用户的行为特征上,在给定候选广告 A 的前提下通过加权求和池化来自适应地计算用户的表征
。
其中
是用户
的长度为
的行为表征向量,
随着广告位不同而变化,
是传入前向网络,输出激活权重。
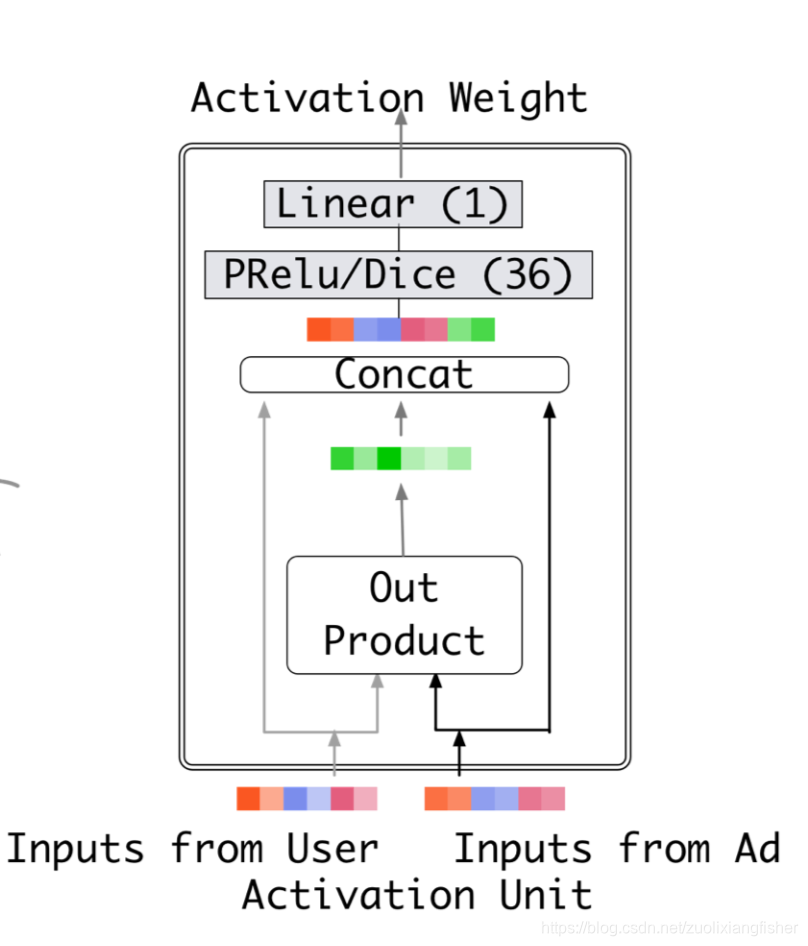
如上图所示,输入 user embedding 和 ad embedding,两个向量做外积后得到新的向量,再和各自的embedding 拼接成一个大向量经过 mlp + PReLU/Dice 激活层后得到一个32维的向量,再经过一个线性变换得到输出的激活权重。
局部激活单元和参考资料[1] 中发展的attention 方法类似,但对约束 放宽了,旨在保留用户兴趣的强度,也就是说,放弃了在 输出上使用 softmax 进行归一化,相反, 被认为是某种程度上对用户兴趣强度的近似。例如,某个用户历史行为里有90%是关于衣服的,10%是关于电子产品的,给定手机和T恤的两个备选广告,T恤激活了绝大部分属于衣服的历史行为,并且能比手机获得更大的 值,传统的注意力方法是通过归一化 的输出而失去 数值尺度上的分辨率。
我们尝试了LSTM以顺序方式对用户历史行为数据进行建模。 但这并没有改善。 与NLP任务中受语法约束的文本不同,用户历史行为的序列可能包含多个并发兴趣。 这些兴趣的快速跳跃和突然结束导致用户行为的顺序数据似乎很嘈杂。 一个可能的方向是设计特殊的结构,以便按顺序对这些数据进行建模。 我们将其留待将来研究。
5、训练技巧
在阿里巴巴的广告系统中,商品和用户数量达到了数亿。 实际上,训练具有大规模稀疏输入特征的工业深度网络是巨大的挑战。 在本节中,我们介绍了两种重要的技术,它们在实践中被证明是有帮助的。
5.1 小批量感知正则化
过拟合问题是训练工业级网络的巨大挑战,例如,添加细粒度特征,像具有6亿维的商品ID的特征,模型没有进行正则化在训练的第一个epoch之后,性能迅速下降,如图4所示的深绿色线
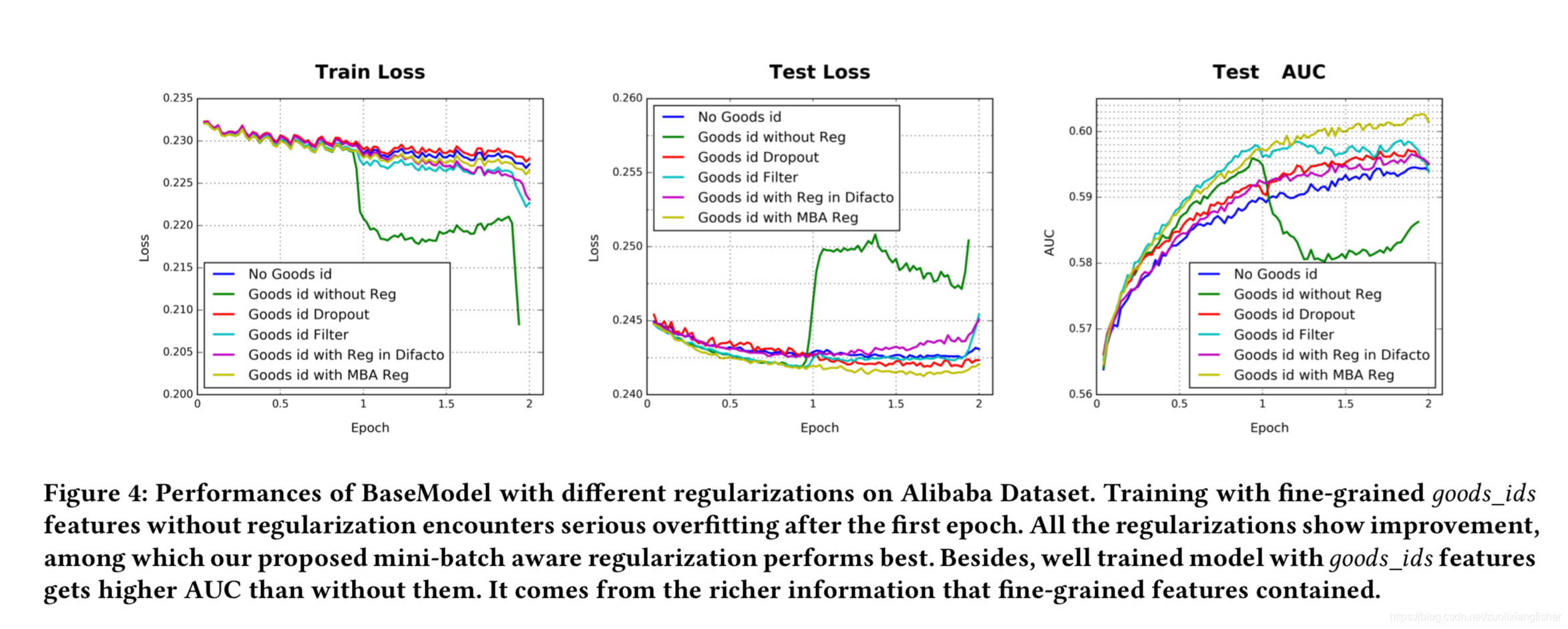
在训练极其稀疏的输入和拥有亿级参数的网络时,直接使用L1或者L2正则是不合理的,以l2正则化为例。 在基于SGD的优化方法的情况下,仅需要更新每个小批处理中出现的非零稀疏特征的参数,而无需进行正则化。但是,当添加了L2正则化后,对于每个小批量数据,需要计算全部参数的L2范数,这需要极大的计算量,当参数规模到亿级别之后是不可行的。
在本文中,我们介绍了一种有效的 mini-batch 感知正则化器,它仅针对每个 mini-batch 处理中出现的稀疏特征的参数计算L2范数,从而使计算成为可能,实际上,正是表征字典为CTR网络贡献了大部分参数,并且增加了繁重的计算难度。令
表示表征字典的参数,
是表征向量空间维度,
是特征向量维度,对于所有样本,作用于
的
范数:
其中
是第
个表征向量,
表示样本
有第
个特征 id,
表示特征
在所有样本中出现的次数。预算公式(4) 在mini-batch 模式下可以转为公式 (5)
其中
代表mini-batch的数量,
代表第
个mini-batch,令
表示在 mini-batch
里,至少有一个样本有特征
,那么(5) 式可以近似为
通过这种方式,我们得到了
正则的mini-batch 近似版本,对第
个mini-batch,特征
的表征权重的梯度满足
只有在 mini-batch 里出现的特征的参数才会参与计算正则化。
5.2 数据自适应激活函数
PReLU是一个非常常见的激活函数
其中
是输入的激活函数
的一个维度。
是示性函数,
是学习参数。
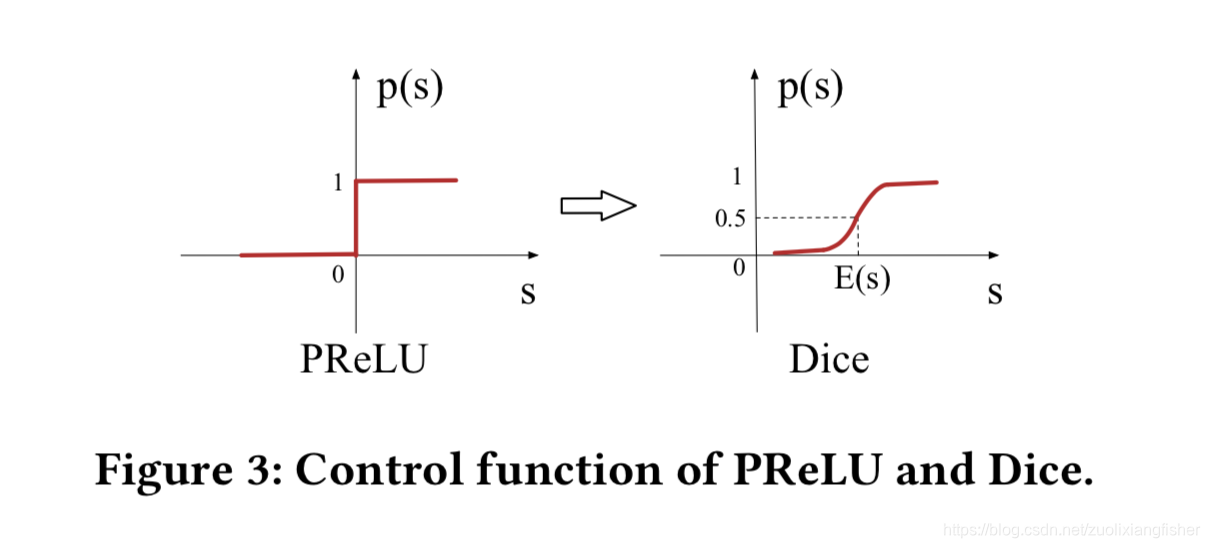
可以看到PReLU激活函数在0点有一个跳跃,是不连续的,当每一层的输入是属于不同分布的时候这种情况就不太合理,因此我们设计了一个新的激活函数 Dice
在训练阶段,
是每个输入mini-batch 的均值和方差,在测试阶段,
通过计算数据的移动平均
得到。
是一个小的常量,通常设置为 1e-8
Dice 可以看做是PReLU的泛化版。 Dice的关键思想是根据输入数据的分布来自适应地调整纠正点,其值设置为输入的平均值。 此外,Dice控制流畅,可在两个通道之间切换。 当
= 0且
= 0时,Dice 退化为PReLU
参考文献:
1、Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 191–198.
2、Cheng H. et al. 2016. Wide & deep learning for recommender systems. In Pro- ceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM.
3、Ying Shan, T Ryan Hoens, Jian Jiao, Haijing Wang, Dong Yu, and JC Mao. Deep
Crossing: Web-scale modeling without manually crafted combinatorial features.
4、Qu Y. et al. 2016. Product-Based Neural Networks for User Response Prediction. In Proceedings of the 16th International Conference on Data Mining.
