VGGNet在2014年的ILSVRC竞赛上,获得了top-1 error的冠军和top-5 error的第二名,错误率分别为24.7%和7.3%,top-5 error的第一名是GoogLeNet 6.7%。在图片定位任务中,也获得了冠军。网络层数由之前的AlexNet 的8层提高到了最高19层(网络E)。其突出贡献在于,证明使用很小的卷积(3*3),增加网络深度,可以有效提升模型的效果。并且VGGNet对其他数据集具有很好的泛化能力。
VGGNet的一部分卷积层后面跟着池化层。总的结构是,在一系列卷积层(中间有池化层)后,是三个全连接层,前两个全连接层均有4096个通道,第三个由1000个通道,用来分类。所有网络全连接层配置相同。所有隐藏层都使用了ReLU,但不使用LRN。
具体网络配置:
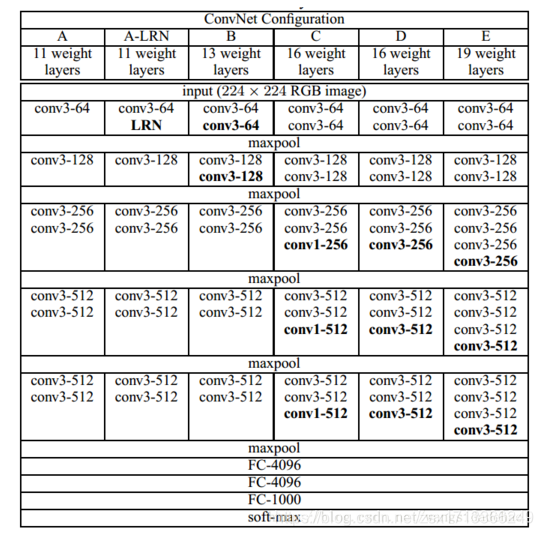
A网络是8个卷积层,3个全连接层,共11层。到E网络时是16个卷积层,3个全连接层。卷积层宽度(通道数)从64到512,每经过一次池化操作扩大一倍。
训练:
1,通过使用带有动量的小批量梯度下降法(batch size=256)来优化目标函数
2, 通过权重衰减(L2正则化)和对前两个全连接进行droupout来实现正则化
3,使用尺寸抖动(scale jittering)方法:对原始图片的裁剪尺寸,随机从[256,512]的确定范围内进行抽样,这样原始图片尺寸不一,有利于训练,比采用单一尺寸裁剪图像效果要好。增强了训练集(另外也使用了图像翻转来增强训练集)。
作者在最后还将多个卷积网络进行融合,性能也有所提高。
最后,文中还介绍了VGGNet在定位任务中网络的训练和测试过程,对之前的分类任务的网络模型做了一些修改就取得了第一名。之后将VGG网络应用于其他的数据集中,也取得了很不错的成绩。说明VGGNet 具有很好的泛化能力。
小结:
- 使用比较小的卷积核(3*3)比使用较大的卷积核(5*5、7*7、11*11等)的效果要好很多,不仅降低了错误率,而且还减少了需要训练的参数。(用3x3的卷积核是因为这是能捕捉到各个方向的最小尺寸了。由于第一层中往往有大量的高频和低频信息,却没有覆盖到中间的频率信息,且步长过大,容易引起大量的混叠,因此卷积核尺寸和步长要尽量小)
- AlexNet中使用过的LRN(局部响应归一化)方法并不能降低错误率,相反还造成了内存损耗,增加了计算量
- 可以使用1*1的卷积核,能在不影响卷积层接受域的情况下增加决策函数的非线性,提升网络的表达能力,只增加很小的计算量。
(另外,1*1卷积核还有降维的作用,此处作者没有提到)