1. 论文思想
文章指出在识别和分类问题中将深度学习网络加深可以显著提升网络的精度,这也是最能够直观理解的,因为网络越深,后面对原始信息的表达更抽象和涵盖,因而更容易区分。但是依据会出现如下的问题:
(1)随着网络层数的增加,随之而来的风险便是梯度消失或是爆炸问题。对于这个问题,目前使用白化输入以及BN+Scale能够解决大部分的问题。但是网络越深,梯度回传也就越弱。
(2)网络退化(degradation problem):随着网络层数的增加,网络的精度会逐渐达到饱和,并开始快速下降。这并不是由过拟合造成的,在适当深度的网络结构上添加层数,会使得训练错误率上升。
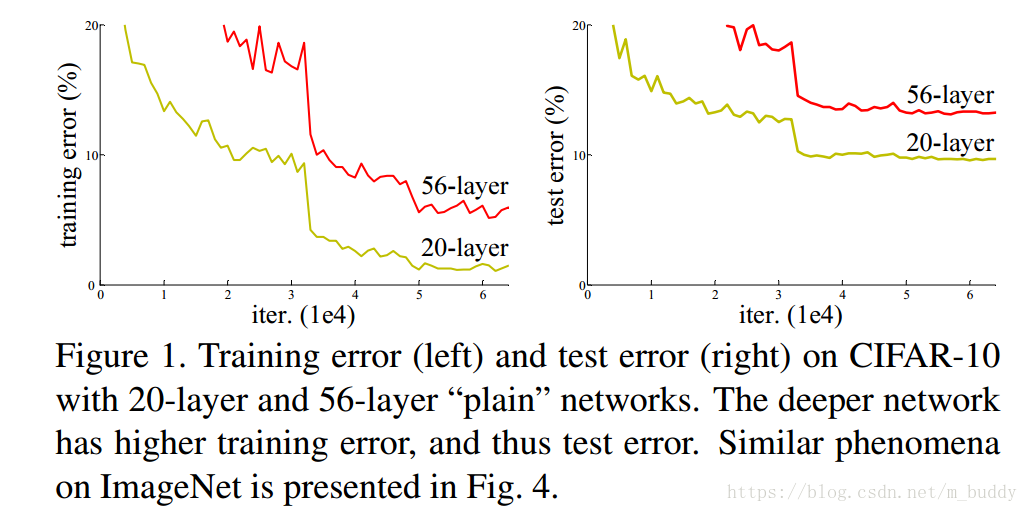
从上图中可以看到采用传统结构的深度网络,增加网络中的层数并不会使得网络精度上升、错误下降,其结果是相反的。因而在该篇文章中使用了如下的网络结构来解决上述提到的问题。
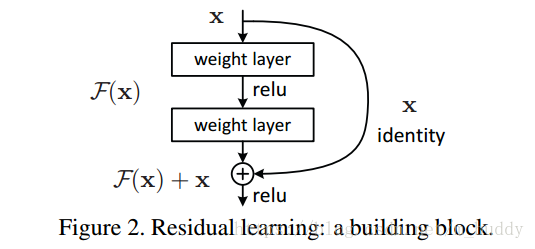
从上图中可以看到在残差网络中相比传统网络直观的不同点便是增加了恒等映射(identity mapping),恒等映射通常是跳过一层网络或是更多网络层,需要注意的是恒等映射的两端的维度要求是一致的。恒等映射添加的位置位,上一输出层relu之后以及残差模块relu之前,具体如上图所示。
这里定义残差网络的输出为
,中间两层卷积的输出是
,因而可以得到:
从而可以得到:
这样使得网络不再去拟合最后的结果 ,而是去拟合残差 。这便能够实现网络的正向反馈。添加了如上结构的网络存在如下的优点:
(1)网络变得更加容易优化,而传统方案设计的深层网络会出现训练误差增加的问题
(2)残差网络可以通过增加网络的深度增加网络的精度,产生的结果也是好于之前的网络的。
(3)恒等映射的加入并不会带来任何参数或是计算复杂度的增加。
那么为什么残差模块中的网络层是2或是更多而不是1呢?在论文中给出了解答,说是目前对于该结构并没有观察到任何的优势。
2. 残差网络
2.1 残差网络结构
![[残差网络结构图]](https://img-blog.csdn.net/2018082722440582?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21fYnVkZHk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
从上图中可以看出论文提出的残差网络在很多地方通过支路的形式连接到后面的网络中,这是与传统网络结构很大的不同,这使得后面的网络可以直接学习残差。传统的网络在顺序卷积操作的过程中,难免会丢失部分信息。ResNet通过使用支路连接的形式,将信息直接传递到ResNet的输出端,某种程度上保护了信息的完整性,整个网络只需要学习输入与输出之间的残差,这极大简化了学习目标和难度。
模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。