0 摘要
本文基于深度卷积神经网络学习的特征,提出了一种新的文档图像分类和检索的技术。 在物体分类和场景分析中,深度神经网络能够从像素级别的输入中学习到分层的抽象特征,并简洁地表达出来。目前在文档分析领域探索的一些工作表明,深度学习的特征表达策略优于传统流行的手工提取特征。实验还表明:
(i)从CNN中提取的特征对于压缩具有鲁棒性;
(ii)在非文档图像上训练的CNN可以很好地迁移到文档分析任务;
(iii)如果有足够的训练数据,不需要进行特定领域的特征学习。
本文还提供了一个带标签的IIT-CDIP的子集,其中包含16个类别的400,000个文档图像,可用于训练CNN以进行文档分析。
1 介绍
许多文档类型都有独特的视觉风格。 例如,书信文档通常以标准格式书写,即使在文本不可读的范围内也是可识别的。 受此现象的启发,本文基于文档图像的视觉结构和布局,解决了文档分类和检索问题。
基于文本内容的文档图像分析可以应用在许多场合。在数字化图书馆中,文档在被光学字符识别(OCR)系统处理之前经常以图像形式存储,这意味着基本的图像分析是唯一可用于索引和分类的工具。 在预处理阶段,文档图像分析可以通过提供每个文档的视觉布局的信息来促进和改进OCR。 此外,OCR中丢失的文档信息(如字体,图形和布局)只能使用图像或图像描述符进行存储和索引。 因此,在文档分析的几个阶段,图像分析与OCR是互补的。
不同的文件类型,文件布局存在着广泛的视觉可变性,这是文件图像分析的一个挑战。例如,在图1所示的通信文件中,没有两个文件有相同的(标题、日期、地址、正文、签名)空间布局, 一些文件甚至完全忽略了这些。 这种类内的可变性使得空间布局分析变得困难,并且不可能实现刚性模板匹配。另一个问题是不同类别的文件通常具有显着的视觉相似性。 例如,看起来像新闻文章的广告,以及看起来像表格的问卷等等。 从“视觉风格”的角度来看,在这种情况下的一些错误检索的存在可能是合理的,但是尽管存在类内可变性和类间相似性,文档图像分析的任务是有效分类和检索文档。

其他领域也出现类似的挑战,如对象识别和场景分类。在这些领域中,当前最先进的方法是训练深度卷积神经网络以学习任务的特征。受CNN在其他领域的成功启发,本文提出了使用CNN进行文件分类和检索。最终发现,深度CNN提取的特征超出了分类和检索中所有流行的替代提取特征的性能。我们介绍了迁移学习的实验,这些实验表明,在物体分类领域训练的CNN,其学习到的特征也可以有效地描述文档。此外,我们发现加上特定区域的特征没有改善深度网络,这表明,在整个图像上训练的CNN已经能够学习到局部区域的信息。
1.1 相关研究
在过去二十年的文件图像分析中,研究从基于局部区域的分析发展到整体图像分析,同时从手工提取的特征发展到机器学习提取特征。
基于区域的文档图像分析的能力已经在结构严密的文档(如表单和商业信函)中得到了清晰的展现。通常,这种方法假定许多文档类型具有独特的可视化识别组件和相同的配置。例如,正式的商业信函通常会有相同的空间配置:标题,日期和称呼。在一定程度上,完全刚性的文档(例如表单)的分类可以归结为模板匹配的问题,而不太刚性的文档类型(例如书信)可以类似地通过将文档的组件进行一些几何变换,从而和几个模板进行匹配。这种方法的缺点是它需要手动定义每种文档类型的模板以进行分类。此外,该方法仅限于可以进行模板定义的文档。对于结构更灵活的文档,如本文所考虑的,基于模板匹配的方法不适用。
另一种策略是整体处理文档图像,或者至少在非常大的区域中处理文档图像,并搜索可能出现在文档任何位置的有区分性标志性特征。这种策略有时被称为“视觉词袋”方法,因为它用直方图描述了无序词汇表中的特征。例如,区分书信和大多数其他文档的标志特征是称呼:在文档中找到称呼(可能通过OCR)是一个很好的线索,而不管该特征出现的确切空间位置如何。整体分析的优点是文档的结果表示对特征的几何变化是不变的。因此,在文档的检索和分类中,尽管这种方法在刚性模板文档领域的区分度较小,但比基于模板的方法应用更广泛,更成功。
与此同时,许多研究人员用机器学习替代了手工制作的特征和表达。这一领域的一个热门研究是学习文档结构。 通常训练决策树对文档进行结构分类。最近的研究表明,监督训练的文档图像分类,从特征构建到决策,都可以通过卷积神经网络实现。 在这项工作中,作者报告说,相比之前使用空间金字塔匹配的相同数据集的最佳分类准确度,分类准确率提高了22%。 然而,CNN方法尚未应用于文件检索。
计算机视觉的其他领域也正在向机器学习转变。 在目标识别文献中,CNN目前超过了其他方法的表现。CNN方法甚至被证明适用于传统上认为不适合的领域,例如属性检测和细粒度对象识别。CNNs在细粒度物体识别中的成功与文档图像分析特别相关,因为这两个领域存在一些相同的挑战,例如:(i)被区分的项目彼此非常相似;(ii)没有足够大的数据集来训练强大的CNN避免过拟合。 因此,可以从克服这些挑战的细粒度目标识别研究中汲取灵感。
从细粒度的分类研究中可以收集到有关CNN训练和使用的两大要点。 首先,在用感兴趣的数据对CNN进行训练之前,建议在一个更大的相关问题上对网络进行预训练。 这种正则化技术解决了过度拟合的问题。 其次,在空间信息很重要的问题中,将这些信息编码在多个关注特定区域的网络中比在整个图像上训练的单个网络更好。 更一般地说,第二点意味着完全依靠机器学习是不必要的,特别是人类知识可以很容易应用到系统时。 本文旨在研究这些见解是否与文档图像分析相关。
最后,其他领域的CNN最近已经扩展到图像检索任务。 在CNN经过分类训练后,其网络层可以被解释为一个分层的抽象链,其中最低层包含简单的特征,最高层包含低层特征的表示。 因此,从CNN顶部附近输出的结果可以作为一个特征向量,可以用于任何任务,包括检索。 目前的工作是第一个将这个想法应用于文档检索。
1.2 相关贡献
鉴于以前的工作,本文做出如下贡献:首先,本文测试了用深度CNN特征表示文档图像的能力。为此,本文进行了有关CNN设计,训练,特征处理和压缩的实验。结果表明,从CNN中提取的特征优于所有手工制作的特征,并且还可以压缩为非常短的编码,其性能损失可以忽略不计。其次,实验表明,用非文档图像进行训练的CNN可以很好地迁移到文档图像的任务。第三,本文探讨了一种将人类的文档结构知识嵌入到CNN体系结构中的策略,引导CNN学习特定区域的特征。有趣的是,结果表明,这种增强后的分类和检索结果几乎没有改善,这表明,基于整体图像训练的CNN会自动学习特定区域的特征(或者更好的特征)。最后,这项工作提供了一个带标签的IIT-CDIP的子集,其中包含16个类别的400,000个文档图像。
2 技术方法
在结构化文档中,文本和图形元素的布局通常反映了关于文档类型的重要信息。 因此,同一类别的文档通常在特定区域中会有相同的特征(比如书信都有称呼)。 本文通过训练两种CNN学习这些信息特征:基于整体处理文档图像的CNN和基于特定区域的CNN。 此外,本文探讨了两种不同的初始化策略:第一种是随机初始化CNN的权重,并完全依靠训练过程来查找特征; 第二个是使用另一个任务上训练网络的权重,并且仅依靠训练将特征微调到文档分析领域。
2.1 整体文档图像处理的CNN
用于计算机视觉中的神经网络,网络将图像像素的方形矩阵作为输入,通过堆叠卷积层的处理,然后使用两个或三个全连接层对卷积层的输出进行分类。 一个典型的网络AlexNet有大约6000万的训练参数。这种庞大的特征表征能力以及特征的层级组织,使得网络具备了特征构造和分类的能力。
卷积神经网络激活不是几何不变的。 在诸如物体检测的应用中,这是不方便的属性。许多工作来为CNN增加空间不变性,例如,对训练数据加入一些抖动,增加数据集中每个图像的几何变体(数据增强),或者通过改变CNN的结构来处理多尺度的输入和位置。 然而,对于文档分析,增加CNN激活的空间特异性可能是有益的。 例如,处理文档的页眉区域与页脚区域不同是有意义的。对整齐排列的文档图像数据集进行整体CNN训练应能够自动学习区域特定的特征。
通常,CNN被训练来执行分类任务,但是也可以将经过分类训练的CNN来执行检索任务。 目前已经发现,在CNN高层附近的激活产生了非常具有描述性的特征向量。 这些特征向量是高维(例如,4096维),但是它们的维度可以通过PCA降维(例如,降低到128维)显着减少维度而不显着影响它们的区分能力。检索包括计算待查询描述符与训练集的每个描述符之间的欧几里德距离。然后对距离进行排序,用这个序列对训练数据的图像进行排序,并返回排序后的文档列表。
2.2 特定区域处理的CNN
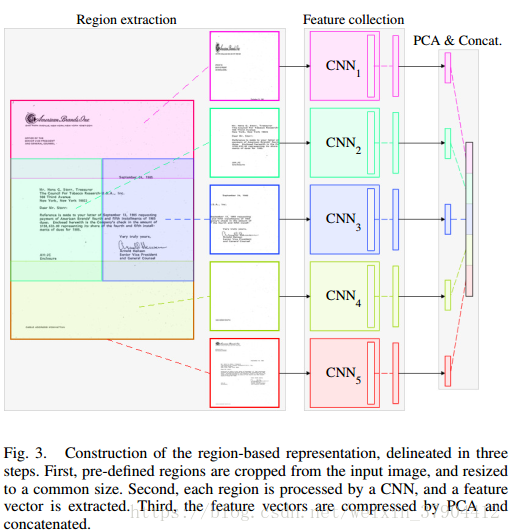
考虑到整体图像处理的CNN可能存在无法利用区域特定信息的可能性,我们人为指导CNN学习基于特定区域的特征。各文档类别在一些微小区域中存在特定的外观差异来辅助细粒度分类。考虑区分书信和备忘录的例子,如图2所示。这两个类别在“地址”部分有一定的区别。备忘录有一个简短的“To”和“From”,但是书信保留有完整的地址。整体图像处理的CNN可能会自动学习这一点,但是如果只使用这一部分区域训练CNN,会增加这部分区域(的差异)被网络学习到的可能性。这种方法的想法是将一个CNN用于每个感兴趣的区域,并因此迫使多个CNN学习区域依赖的表示,从中可以提取和组合特征。

可以使用任意数量的区域特定的CNN。 我们总共使用了五个CNN。 其中四个是用于区域调整的,位于文档图像的标题,左侧正文,右侧正文和页脚。 第五个是整体的CNN,训练整个图像。 最终,基于特定区域的文档图像表示的建立是组合、压缩从四个区域调整的CNN中提取的特征。将五个CNN提取到的特征组合起来,作为文档图像最终的特征描述符:
。其中
表示从整体文档图像的CNN中提取的特征向量,
表示从特定区域
的CNN中提取的特征向量。如图3所示。对于检索任务,我们直接使用这个新的向量。 对于分类任务,用一个新的全连接的层对这个向量进行分类。
2.3 迁移学习
迁移学习的目标是通过共享相关问题的网络结构,利用很少的训练数据进行学习。在卷积神经网络中,通过权重初始化实现迁移学习。 CNN的典型初始化的策略是将所有权重初始化为很小的随机数,并将所有偏差初始化为1或0。另一种策略是在其互补的任务上预训练网络,在目标任务上微调(互补的任务比目标任务有更多的训练数据)。这是一种很好的解决方案,防止网络在目标任务上在训练早期下降到局部最小值。在ImageNet上预训练网络是一种比较流行的做法,因为它包含超过一百万个自然图像,分为1000个对象类别。从ImageNet预训练的网络中提取的特征已被证明是有效的通用特征,即使没有对目标任务进行微调,也可以用到其他视觉领域中。
本文研究了迁移学习应用于文档分析的三个问题。 首先,本文调查ImageNet上提取的特征是否足以应用于文档分析。 也就是说,没有对使用文档数据对其进行微调,通用物体分类特征能否适用于文档分析任务? 其次,使用ImageNet预训练模型的权重进行初始化是否比随机初始化有更好的效果。 第三,研究迁移学习的有用性。如果CNN使用少量的文档数据进行训练,那么在该过程中学习的特征是否可以区分训练时不可见的文档类别? 这些问题将在随后的检索任务中得到解答。
3 实验评估
3.1 数据集
使用IIT CDIP数据集(有两个版本)评估所提出方法的性能。该数据集包含了扫描文档的高分辨率图像,这些图像是针对美国烟草公司的诉讼公开记录中收集而来的。 该数据库总共有超过七百万个文件,手写标签。 通常,文档图像的第一个标签指明文档的类别,但是数据集中的许多文档都有缺失或错误的标签。
数据集的第一个版本为SmallTobacco,包含3482个图像的样本。 这个版本的数据集被用于许多相关论文中。 每张图片都有1个标签(总共10个标签)。 每个类别的图像数量不均匀,“书信”类别的图像比例最大。每个类别数量的分布代表了其在整个数据集中的分布。
数据集的第二个版本为BigTobacco,包含16个类别的25000个图像样本,共有400000个标记图像。这个样本是专门为本文收集的。这16个类别是“信件”,“备忘录”,“电子邮件”,“文件夹”,“表格”,“手写”,“发票”,“广告”,“预算”,“新闻文章”,“科学出版物“,”问卷调查“,”简历“,”科学报告“和”规范“。早期关于文件分类的工作以及SmallTobacco中存在的类别共同指导了本文关于类别的选择。在这个版本的数据集中,每个图像都只标有一个类别。
每个数据集被分成三个子集。 SmallTobacco数据集,800幅图像用于训练,200幅用于验证,其余用于测试。BigTobacco数据集按照与ImageNet相似的比例进行分割:320000图像用于训练,40000图像用于验证,40000图像用于测试。
3.2 实现细节
CNN在Caffe中实现。所有网络都在最后一个全连接层进行softmax分类,N是类别的数量。 CNN的结构是基于AlexNet。该网络具有五个卷积层和三个全连接的层。 网络拍摄尺寸为227×227的图像。完整的结构可以写成227×227 - 11×11×96 - 5×5×256 - 3×3×384 - 3×3×384 - 3×3×256 - 4096 - 4096 - N。第一个全连接层4096维度的输出,作为CNN的特征向量。
第一个网络(Small holistic CNN)的结构有所不同,它使用在另一文档图像分析工作中的超参数。 该网络具有两个卷积层和三个全连接的层,并在其间的几个阶段使用池化,ReLU和dropout。 网络将尺寸为150×150的图像作为输入图像。 完整的体系结构可以写成150×150-36×36×20-8×50-1000-1000-N。第一个全连接层1000维度的输出,作为CNN的特征向量。
第二个网络(Ensemble of CNNs)有不同的结构,它使用从基于特定区域的CNN中提取的特征向量来进行分类。 由于长度为
的向量太大而无法分类,因此使用主成分分析(PCA)将各个基于区域的向量压缩到640维,然后将它们连接在一起进行分类。 网络体系结构可以写成3200×4096×N。对于检索任务,将特征向量分别压缩到128个维度,然后连接,产生具有640个维度的向量。
为了测试迁移学习的效果,我们仅使用BigTobacco数据集中的两个类别(书信和备忘录)对整体文档图像处理的CNN(LetterMemo CNN)进行训练。 该网络在ImageNet上预训练。
为了从图像中提取特定区域,首先将所有图像调整到780×600。标题区域取自每个图像中的前256行的像素。 页脚区域取自每个图像中的最后256行的像素。左侧正文取自每个图像中间的400行和左侧的300列。右侧正文与左侧对称。 每个提取的区域在输入之前被调整为227×227。
本文还实施了几种目前最先进的词袋(BoW)的文件表示方法。省略。。
对于检索任务,计算测试集描述符与训练集的每个描述符之间的欧几里德距离。 然后对距离进行排序,用这个序列对训练数据的图像进行排序,并返回排序后的文档列表。特征向量大于128维,在检索之前使用PCA压缩到128维。 这不仅可以实现快速检索,还可以将任务保持在合理的内存限制内。
3.3 分类结果
在SmallTobacco中,Ensemble CNNs表现比任何其他方法都要好,分类准确率达到79.9%。 Holistic CNN的表现只比Ensemble CNNs稍差。当Holistic CNN和Small holistic CNN都用随机权重初始化时,两者性能相似,这似乎表明在大网络中的附加参数(额外增多的层)不一定有益。 使用ImageNet训练的权重初始化可以显着提高性能。 如果没有这种初始化,CNN的表现与BoW方法类似。
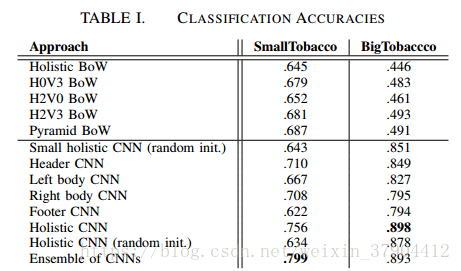
在BigTobacco上,来自Imagenet的Holistic CNN表现优于其他任何方法,包括Ensemble CNNs。 这表明,如果有足够的训练数据,Ensemble CNNs所获得的优势将被Holistic CNN的学习能力所消除。 .在这些结果中,CNN方法的表现远好于BoW方法。 正如SmallTobacco所观察到的,微调可以提高结果,尽管收益比较小。
仅对书信和备忘录进行分类的CNN在该任务上达到了95%的准确率。

3.4 检索结果
检索使用mAP进行测量。 mAP的平均值作为某个时间间隔的召回函数。 形式上,这个度量的由下式给出:
其中,k是正在检索的文档的排序,并且如果文档是相关的,则rel(k)等于1,否则等于0。 该度量对排序顺序很敏感,因此如果在不相关的文档之前检索相关文档,分数会更高。 平均平均精度仅仅是所有查询的平均精度总和除以查询次数。 如果检索到的文档与查询图像具有相同的类标签,则被确定为“相关”。 图6总结了两个数据集前10次检索的平均精度。
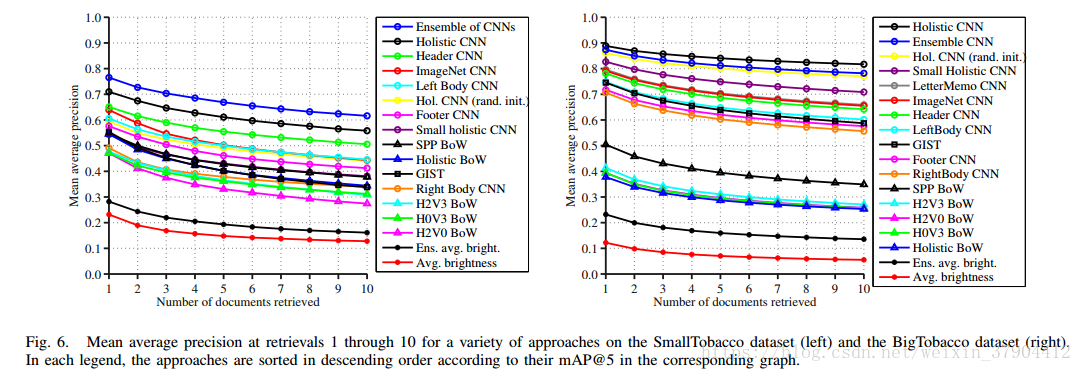
在SmallTobacco数据集中,Ensemble CNNs表现最佳,其次是由ImageNet精细调整的Holistic CNN。 有趣的是,使用通用的ImageNet描述符也表现良好,超出了大多数其他描述符的性能。
在BigTobacco数据集上,Holistic CNN表现最好,略微超过Ensemble CNNs,但大幅超过大多数其他方法。 “LetterMemo”CNN稍微提升了通用ImageNet描述符的性能,表明从信件和备忘录中学到的一些知识转移到所有16个类别,有收益但不大。
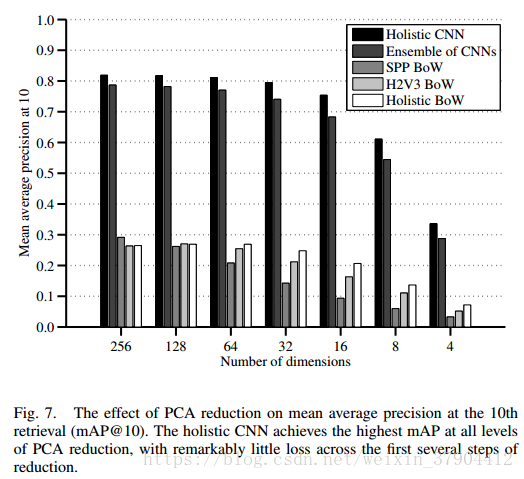
另一个实验来测量PCA压缩对BigTobacco数据集上mAP @ 10性能的影响,其结果总结在图7中。值得注意的是,CNN几乎没有显示的性能损失,直到它们减小到16维。 在所有级别的压缩中,Holistic CNN的执行超过了其他方法的性能。
4 总结
本文使用深度卷积神经网络学习的特征,为文档图像分类和检索建立了一种新的技术。 在CNN中提取的特征达到了最高性能,并且对文档图像上的这些特征进行微调还可以提升结果。 有趣的是,实验还表明,如果有足够的训练数据,则不需要执行特定区域的特征学习; 在整个图像上训练的单一CNN与在文档图像的特定子区域上训练的集成CNN一样。 总而言之,这项工作表明,CNN文件图像表示方法超越了手工提取的力量。