论文笔记:Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning
论文信息

论文及代码下载:http://mmlab.ie.cuhk.edu.hk/projects/RL-Restore/
1.Introduction
深度卷积神经网络在低层视觉任务中取得了巨大成功,而且,与传统的基于模型的优化方法相比,具有更好的性能和更快的测试速度。
深度卷积神经网络低层视觉任务:
(1)deblurring
1)S. Nah, T. H. Kim, and K. M. Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. In
CVPR, 2017.
2 )J. Sun, W. Cao, Z. Xu, and J. Ponce. Learning a convolutional neural network for non-uniform motion blur removal.
In CVPR, 2015.
3)L. Xu, X. Tao, and J. Jia. Inverse kernels for fast spatial deconvolution. In ECCV, 2014.
(2)denoising
1)Y. Chen, W. Yu, and T. Pock. On learning optimized reaction diffusion processes for effective image restoration. In CVPR, 2015.
2)S. Lefkimmiatis. Non-local color image denoising with convolutional neural networks. In CVPR, 2017.
(3)JPEG artifacts reduction
(4)super-resolution
1)C. Dong, C. C. Loy, K. He, and X. Tang. Image superresolution using deep convolutional networks. TPAMI, 38(2):295–307, 2016.
2)J. Kim, J. Kwon Lee, and K. Mu Lee. Accurate image superresolution using very deep convolutional networks. In CVPR, 2016.
3)T.-W. Hui, C. C. Loy, and X. Tang. Depth map superresolution by deep multi-scale guidance. In ECCV, 2016.
4)Y. Tai, J. Yang, X. Liu, and C. Xu. Memnet: A persistent memory network for image restoration. In ICCV, 2017.
5)X. Wang, K. Yu, C. Dong, and C. C. Loy. Recovering realistic texture in image super-resolution by deep spatial feature
transform. In CVPR, 2018.
由于CNN的判别特性,大部分的模型之前被训练用来处理特定的低层视觉任务。近期的一些图像复原工作(如VDSR、DnCNN等)证实了一个CNN网络可以处理多种失真类型或不同失真程度的降质图像,这为解决混合失真问题提供了新的思路。但是,这类算法均选用了复杂度较高的网络模型,带来了较大的计算开销。另外,这些算法的网络均使用同一结构处理所有图像,未考虑一些降质程度较低的图像可以使用更小的网络进行复原。
针对现有图像复原CNN算法模型复杂,计算复杂度高的问题,本文提出的RL-Restore算法弥补了这些不足,以更加高效灵活的方式解决了复杂的图像复原问题。
当前流行的图像复原理念认为解决复杂的图像复原问题需要一个大型的CNN,而本文提出了一种全新的解决方案,即使用多个小型CNN专家以协作的方式解决困难的真实图像复原任务。RL-Restore算法的主要思路是设计一系列基于小型CNN的复原工具,并根据训练数据学习如何恰当地组合使用它们。这是因为现实图像或多或少受到多种失真的影响,针对复杂失真的图像学习混合使用不同的小型CNN能够有效的解决现实图像的复原问题。不仅如此,因为该算法可以根据不同的失真程度选取不同大小的工具,相较于现有CNN模型,这一新方法使用的参数更少,计算复杂度更低。
本文提出的RL-Restore算法贡献如下:
1)基于强化学习的图像复原。
2)提出一个用于同时训练代理(agent)和工具(tool)的联合学习框架。使得框架可以有效处理中间过程中新引入的未知失真。
3)动态组成的工具链性能优于人工设计的网络,且计算量较少。我们的方法更易懂,因为它展示了混合失真是如何一步一步被去除的。
2.Related Work
一些开创性研究可以用一个网络同时处理多种失真:
1)J. Kim, J. Kwon Lee, and K. Mu Lee. Accurate image superresolution using very deep convolutional networks. In CVPR,
2016. 一个单一模型处理多尺度图像超分辨率。
2)J. Guo and H. Chao. One-to-many network for visually pleasing compression artifacts reduction. arXiv preprint arXiv:1611.04994, 2016. 一个one-to-many网络处理不同程度的compression artifacts。
3)K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. TIP, 2017. 一个20层的深度CNN同时处理多种复原任务,包括图像去噪、JPEG compression artifacts和超分辨率。
但是,以上研究均不能处理混合失真,即一种图像同时受到多种失真影响。而本文就是探索小规模CNN网络(3至8层)是否可以用来联合复原混合失真图像。
有一些方法通过直接压缩一个较大的网络来减少计算量,但本文是通过学习一个策略来选择合适的CNN网络来复原图像。
强化学习。
3.Learning a Restoration Toolchain
退化过程描述为:
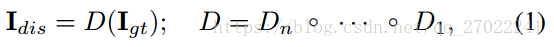
◦表示退化函数的组合
D1,......,Dn 表示不同的退化函数
面临的两个挑战:
(1)如何选择工具成为本文解决的主要挑战之一。复原种类、复原程度和复原顺序的选择都影响最终性能。
(2)没有一个已有的工具可以恰当的处理“中间结果”。例如,去模糊的工具可能也会放大噪声,导致后面已有的去噪工具无法有效处理新引入的未知失真。
挑战应对:
(1)将工具选择问题看作Markov Decision Process (MDP),使用强化学习算法训练得到有效的工具选择策略。
(2)提出联合训练算法对所有工具进行端到端的训练以解决有效复原“中间结果”的挑战。
RL-Restore算法的目标是对一张失真图像有针对性地选择一个工具链(即一系列小型CNN工具)进行复原,因而其该算法包含了两个基本组件:
(1)一个包含多种图像复原小型CNN的工具箱;
(2)一个可以在每一步决定使用何种复原工具的强化学习算法。
3.1 Toolbox
本文提出的工具箱中包含了12个针对不同降质类型的CNN(如表1所示)。每一种工具解决一种特定程度的高斯模糊、高斯噪声、JPEG失真,这些失真在图像复原领域中最为常见。针对轻微程度失真的复原工具CNN仅有3层,而针对严重程度失真的工具达到8层。
为了增强复原工具的鲁棒性,本文在所有工具的训练数据中均加入了轻微的高斯噪声及JPEG失真。

3.2 Agent
RL-Restore的算法框架:对于一张输入图像,agent首先从工具箱中选择一个工具对它进行恢复。然后agent根据当前的状态(包括复原中间结果和之前工具的选择)来选取下一个动作(使用复原工具或停止),直到算法决定终止复原过程。
动作(action):在每一个复原步骤 t,算法会选择一个动作at将其应用于当前输入图像,除了停止动作以外,其余每一个动作均代表使用某个复原工具。在本文中,工具箱内共包含12个工具,因而算法总共包含13个动作。输出向量vt是一个N+1维的动作估值向量,每一个元素代表每个动作的值。一旦天之动作被选择,重建过程就会终止并且当前输入图像就是最终结果。
状态(state):状态是算法可以观测到的信息,在步骤t的状态记为St={It,v ̃t},其中It是当前步骤的输入图像,v ̃t=vt-1是前一步骤的动作估值向量,包含了前一步骤的决策信息。在步骤1时,I1是输入图像,v ̃1是零向量。
回报(reward):在强化学习中,算法的学习目标是最大化所有步骤的累积回报,因而回报是驱动算法学习的关键。本文希望确保图像质量在每一步骤都得到提升,因此设计了一个逐步的回报函数rt=Pt+1-Pt,其中Pt和Pt+1分别代表步骤t的输入图像和输出图像的PSNR,度量每个步骤中图像PSNR的变化。注意,也可以使用其它图像质量评价标准(perceptual loss,GAN loss)。
结构(structure):在步骤t时,agent根据输入状态St来评价每个动作的值,可以描述为:
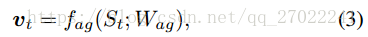
其中,fag表示agent网络,Wag表示它的参数,向量vt表示动作的值向量。用at表示向量vt中的最大元素值。
虚线框内的agent包含了三个模块(如图3所示):
- 特征提取器(Feature Extractor),包含了4个卷积层和1个全连接层,将输入图像转化为32维特征向量;
- One-hot编码器(One-hot Encoder),其输入是前一步骤的N+1维动作估值向量,输出将其转换为对应的N维特征向量;
- LSTM(Long Short-Term Memory),其以前两个模块输出作为输入,这个模块不仅观测当前步骤的状态特征,还存储了历史状态的信息,该模块最后输出当前步骤的估值向量vt,用于复原工具的选取。
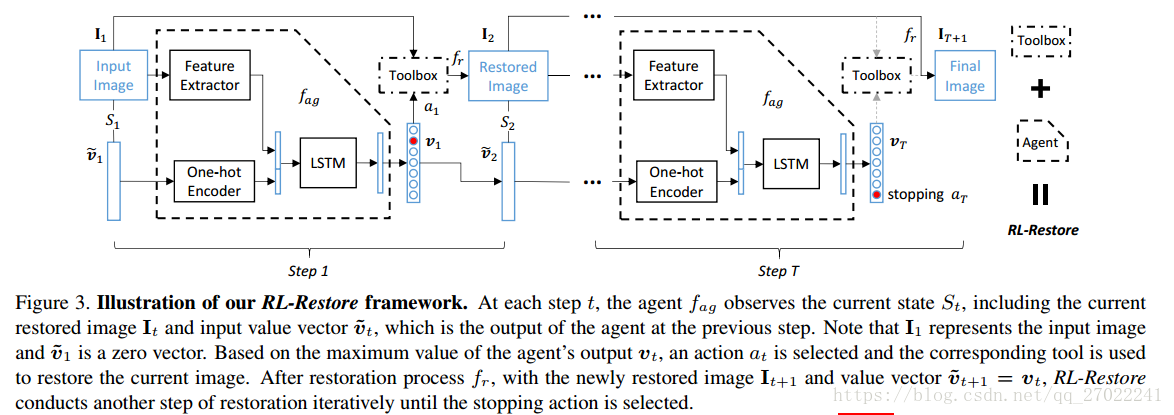
复原(Restoration):一旦获得向量vt中的最大元素值at,相应的工具就会应用于输入图像It,从而得到一个复原图像:
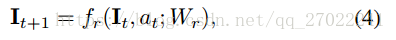
其中,fr表示复原函数,Wr表示所选工具的复原参数。如果选择了停止动作,那么fr就是恒等映射。
整个复原过程可以表述为:

其中,

T表示停止动作被选择时的步骤次数,设置步骤次数上限Tmax 。
3.3 Training
待更新
4 Experiments
数据集和评价标准(Datasets and Evaluation Metrics)
数据集:DIV2K 数据集。
800张训练图片被分成两部分:1)前750张图片用于训练;2)50张用于测试。验证图片用于验证。
扩增样本:下采样2,3,4。然后将其分割成63*63的图像块,得到训练集249344个图像块,测试集3584个图像块。
本文在每一张图像上随机加上不同程度的高斯模糊、高斯噪声和JPEG压缩。
算法在训练样本中排除一些极度轻微或严重的失真,使用中度失真的图像进行训练(如图3所示),而在轻度、中度和重度失真的图像上进行测试。
比较(Comparisons)
VDSR
DnCNN
VDSR-s:将VDSR从20层减少到15层。参数量与RL-Restore相当。

4.1. Quantitative Evaluation on Synthetic Dataset
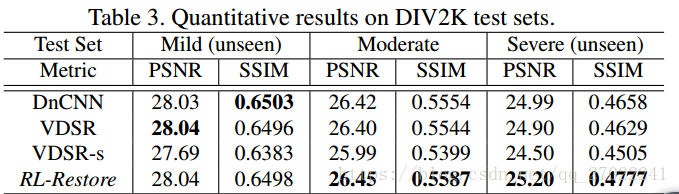
在中度失真数据集上测试,发现本文方法优于VDSR-s,且与DnCN和VDSR相当,但计算复杂度较低。在严重失真数据集上(失真类型之前未见过)测试时,本文方法PSNR分别比DnCNN和VDSR高0.2dB和0.3dB,它表明我们的方法在处理未见失真时更加灵活。
4.2 Qualitative Evaluation on Real-World Images
本文也使用实际场景图像对RL-Restore算法进行了进一步测试。如图5所示,测试图像由智能手机采集,其中包含了模糊、噪声和压缩等失真,直接使用训练好的RL-Restore和VDSR模型在这些真实场景图像进行测试。由结果可以看到,RL-Restore算法取得了明显更加优异的复原结果,图7(a, c) 展示了RL-Restore算法成功修复由曝光噪声和压缩带来的严重失真;图7(b, d, e) 展示了本文方法可以有效地处理混合的模糊与噪声。

4.3 Ablation Studies
为了更好地区分各个因素的有效性,在此部分我们不使用联合训练策略。
工具箱数量和工具链长度:经实验发现,N=12,Tmax=3时性能较好,少于此设置性能变差,多于此设置性能变化不大。失真程度较轻时需要较少的工具链长度。
工具训练:正如3.1所述,为了减轻中间状态产生的复杂失真,提出了两个策略:1)在训练工具时,在训练数据时添加轻度噪声和压缩;2)联合训练。研究这两种策略的影响。Original:表示基准。+Noise:表示采取第一个策略。+Joint:表示同时使用两个策略。结果发现:只采用第一个策略,结果提高了0.2dB,同时使用两个策略,结果又提高了0.2dB。
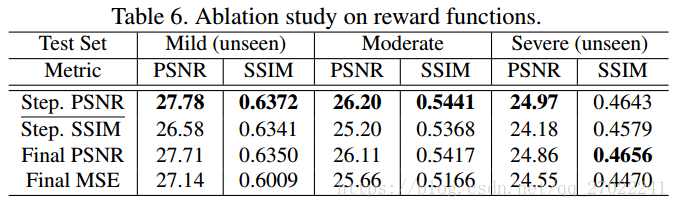
回报函数:
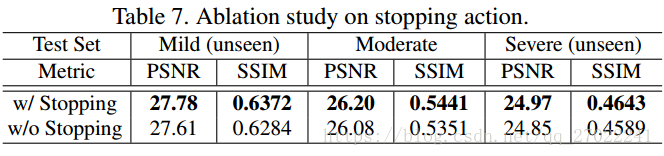
自动停止(Automatic Stopping):
5. Conclusion
本文提出了一种新颖的基于强化学习的图像复原算法—RL-Restore。与现有的深度学习方法不同,RL-Restore算法通过学习动态地选取工具链从而对带有复杂混合失真的图像进行高效的逐步复原。基于合成数据与现实数据的大量实验结果证实了该算法的有效性和鲁棒性。由于算法框架的灵活性,通过设计不同的工具箱和回报函数,RL-Restore算法为解决其他富有挑战性的底层视觉问题也提供了新颖的解决思路。