摘要:
为了解决情感分类中数据不足的问题,本文通过一个专用的内存模块引入外部一般线索(本文称为情感嵌入),这部分信息来自于其他的数据,将这部分信息加入到神经网络的处理过程中,可以获得更好的泛化能力。本实验在七种语言的数据集上都取得了很好的效果。
Approach:
1 Sentiment Embedding Computation
该文章提出word2vec以及glo ve这些常用的生成词向量的方法没有考虑情感信息,因此本篇文章将一些外部的情感信息加入神经网络中,本文用于生成外部情感信息的方法采用了迁移学习的方法,假如有n元分类任务(n个域),那么训练n个线性分类器(本文用的是SVM),用n个线性分类器对每一个词计算得分,依次作为该词的情感嵌入(这篇文章这部分说的并不清楚,关于情感嵌入的做法是个人理解)
本文是在七种语言的数据集上进行实验,由于大部分的资源都是英语的,所以对于其他语言可能没有充足的数据来生成外部的情感信息,因此该文章使用一种基于图传播的扩展用来生成其他语言的外部情感信息。
假设有词汇知识图GL = (V, AL),V代表不同语言的集合,AL是有向加权弧,代表由两种语言表示的两个词之间的相似度,该文章用最小化以下公式来生成其他语言的情感嵌入。
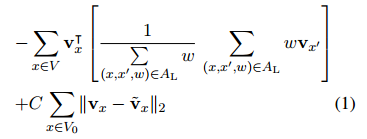
2 Dual-Module Memory based CNNs
获得外部的情感信息后将其加入神经网络的处理过程中,本文的整体结构图如下所示;

图a的左侧是普通的卷积神经网络,进行词向量生成,卷积,池化这些过程,图a中灰色部分为双层内存模型,用来处理外部情感信息,vs表示每个词的外部情感信息,对一个句子中所有的vs求平均值得到vp表示句子的外部情感信息表示,然后计算每一个vi与vp的相似度si作为该词在句子中的权重,计算公式如下:
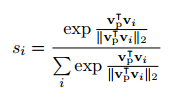
得到每一个词的权重后,将规范化的权重乘上该词的外部情感信息之后在求和,得到句子的表示vo:
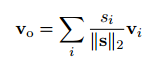
将vo与初始的vp相加后输入到下一层中,将第二层得到的结果与卷积神经网络经最大池化得到的结果进行连接,然后进行全连接后,有softmax得到最后的概率。
实验:
数据集:

结果:

总结:
本文的特点我认为主要有:
1.将外部情感信息加入到cnn中使模型具有更好的泛化能力(但是本文在如何获得外部信息这一部分描述的并不详细)
2.利用资源多的语言的外部信息生成其他语言的外部信息
综合来讲不推荐详细阅读,文章关键的部分没有讲述清楚,其他部分都是常规做法。