0 摘要
近年来,在训练大型深度神经网络方面取得了巨大进展,其中包括训练卷积神经网络识别自然图像。 然而,我们对这些模型如何工作的理解,特别是他们在中间层执行的计算,已经落后了。通过开发更好的可视化和解释神经网络的工具,这一领域的进展将进一步加速。 我们在这里介绍两种工具。 第一种是在处理图像或视频时,将训练过的每个图层上产生的激活可视化的工具。我们发现,随着用户输入的改变,通过查看实时的激活值有助于理解卷积网络的工作原理。 第二种工具通过图像空间中的正则化,可视化DNN每一层的特征。在这里我们介绍几种新的正则化方法,这些方法结合起来可以产生更清晰,更可理解的可视化图像。 这两种工具都是开源的。
简单说:
可视化工作分为两大类,一类是非参数化方法:这种方法不分析卷积核具体的参数,而是先选取图片库,然后将图片在已有模型中进行一次前向传播,对某个卷积核,我们使用对其响应最大的图片块来对之可视化;而另一类方法着重分析卷积核中的参数,使用参数重构出图像。
1 介绍
过去几年在训练强大的深度神经网络模型方面取得了巨大的进步,这些模型在各种具有挑战性的机器学习任务中正在接近甚至超越人类能力。 一个标志性的例子是训练深度卷积神经网络AlexNet,分类自然图像。 该领域大放异彩受益于GPU强大的计算能力,更好的训练技巧(dropout),更好的激活单元(ReLU), 和较大的标记数据集(ImageNet)。
虽然我们对如何创建高性能架构和学习算法的知识有了相当大的改进,但我们对这些大型神经模型如何运作的理解却落后了。 神经网络一直被称为“黑盒子”,因为很难准确理解一个具有大量神经元相互作用、非线性变换的神经网络,训练之后会有什么功能。大型现代神经网络由于其规模更难研究。例如,了解广泛使用的AlexNet DNN需要理解6000万训练过的网络参数。
理解神经网络学习到了什么本身就很有趣,并且这也是进一步改善模型的关键途径:理解当前模型学习到的知识,才可以提出使它们变得更好的方法。 例如,使用反卷积技术,可视化DNN隐藏单元学习到的特征,提出了使用较小的卷积核的结构。这一改进(ZFNet),取得了2013年ImageNet的最佳水平。
本文提供了两种可视化的工具,这两种工具都是开源的,以便科学家和从业人员可以将它们与自己的DNN集成从而更好地理解DNN。第一种工具是交互式的软件,它根据用户提供的图像或视频,让它们通过DNN后,绘制出每一层上产生的激活。第二个工具可以更好地显示由DNN每层的单个神经元计算出的学习特征。观察已经学习到的特征对于理解当前的DNN如何工作以及如何改进它们很重要。
过去的研究大致分为两个不同的阵营:以数据集为中心和以网络为中心。前者需要一个训练好的DNN并在该网络上进行前向运算;后者只需要一个训练好的DNN。以数据集为中心的方法从训练或测试集挑选图像,让这些图像通过DNN网络,DNN网络的每个单元都会产生高或低的激活值。
以网络为中心的方法直接调查网络,而不需要数据集中的任何数据。典型代表是ZFNet的反卷积方法。例如2009年Visualizing higher-layer features of a deep network一文中,通过使特定单元产生高的激活值来合成图像。从初始输入
开始,计算在某个单元
处由该输入引起的激活
。然后沿着梯度
的方向在输入空间中步进迭代,使得单元
产生的激活值越来越高,最终的
被认为是该单元
正在寻找的答案(最希望看到的特征)。在输入空间是图像的情况下,可以直接显示
来解释。其他人也纷纷效仿,使用梯度来查找能使输出单元产生更高激活的图像或更低激活的图像。这些基于梯度的方法在简单性上很有吸引力,但优化过程倾向于生成与自然图像不相似的图像。(高激活产生的图像可能无法辨认)。但是如果能够适当地调整优化,可以用这种方法获得一些有用的可视化。2013年Deep inside convolutional networks: Visualising image classification models and saliency maps一文中,利用L2正则化生成了略微可辨别的图像。本文基于前人的基础研究提供了三种正则化的形式,这些正则化生成的图像比以前的方法更容易识别。
2 实时卷积激活的可视化
我们的第一个可视化方法非常简单:绘制图像或视频经过神经网络的前向计算在每个卷积层中神经元的激活值。 在全连接的神经网络中,神经单元的顺序是不相关的,因此这些矢量的图不具有空间信息性。然而,在卷积网络中,卷积核的使用方式会考虑到输入图像空间信息。

上图绘制出了输入图像经过conv5层后的激活值。 conv5层的大小为256×13×13,我们将其描述为256个13×13灰度图像。每个256张小图像包含了与输入数据在相同的x-y空间中的激活值。并且这256个图像被简单地划分成16×16网格。

上图显示了一个conv5层上的第151通道的13×13激活的视图。该通道响应人脸和动物脸部。这个深度神经网络是在ImageNet上训练的,该网络中不包含脸部类,但包含许多带有脸部的图像。 但是该通道可以对人类和动物的脸部做出反应。
尽管这种可视化很容易实现,但我们发现它很有用,因为所有流经网络的数据都可以被可视化。 幕后没有任何神秘的事情发生。因为这个卷积网络只包含从输入到输出的单一路径,所以每一层都是一个bottleneck ,所有信息都必须通过这个bottleneck传递给分类决策。 迄今为止,我们已经从该工具中收集到了一些令人惊讶的发现:
1.在某些层面上的表示似乎是局部的。例如,我们可以在conv4和conv5上看到文本,鲜花,水果和脸部的检测器,而不是在所有图层上进行分布表示。
2.当直接使用来自Google Images 的照片文件进行分类时,分类通常是正确并且是高度自信的(对于正确分类的softmax概率接近1)。当使用来自网络摄像头的输入时,预测往往不能正确,因为训练集中没有相应的类别。训练集的1000个类虽然很多,但并不包含大多数常见的家庭用品。因此显示网络摄像头中的人时,如果这个人不在ImageNet类别内,输出就不会有很高的概率。这个概率向量是有噪声的,如果输入有微小变化,这个向量会产生显著的变化。绘制全连接层(fc6和fc7)也有类似情况发生。
3.最后三层对小的输入变化很敏感,大部分较低层是非常鲁棒的。 例如,当可视化conv5层时,通过移动摄像头前方的物体,可以找到许多面部,肩部等检测器。尽管1000个类别不包含明确标记的面部或肩部,但网络可以识别这些是因为它们是人的部位,识别整个人需要这些有用的局部信息,有了这些局部信息,将这些局部信息整合起来将有助于最终的分类决定。Conv5上第151通道是一个面部检测器,如上图所示的那样,它可以激活人脸、狮子脸、猫脸。
3 经过正则优化后的可视化
本论文的第二个贡献是引入了几种正则化方法,通过正则优化生成的图像可以有更直观的解释。 几种正规化方法组合起来更为有效。我们通过随机超参数搜索找到了一些有用的组合。
考虑一张图像
,C是颜色通道C=3,H=W=227像素。图像输入神经网络对某一个单元
产生激活
,定义参数化的正则化函数
。
我们的网络在ImageNet上进行了训练,首先减去ImageNet中每个像素的平均值,然后将训练样例输入到网络中。因此,网络的输入x可以被认为是一个以零为中心的输入。我们提出寻找图像
的优化问题:
(寻找一个
使得后面的式子最大)。通过一个运算符
来定义正则化,该运算符将
映射到稍微更正规化的形式。为了更容易求解这个式子,我们通过下面的式子来更新
:
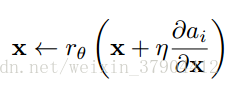
我们提出了四种正则化的方式:
1、L2 decay
一个普通的正则化,L2 decay惩罚大的值,排除一些少量极端的像素。 因为这种极端的像素值既不会频繁出现,也不会用于可视化。L2 decay实现的公式是:
2、Gaussian blur
通过梯度上升生成的图像往往会产生一些高频成分。虽然这些图像可以引起高激活值,但它们不可解释(因为高频成分多)。因此有效的正则化就是惩罚高频信息。我们用高斯模糊来实现:
因为每一步都平滑计算量很大,我们增加一个超参数
每隔几个优化步骤而不是每个步骤模糊图像。高斯模糊就是把某一点周围的像素色值按高斯曲线统计起来,采用数学上加权平均的计算方法得到这条曲线的色值,最后能够留下人物的轮廓,达到平滑的效果。
3、Clipping pixels with small norm
前两种正则化方法是抑制高振幅高频信息,留下来的图像包含很多非零像素。这些非零像素会识别多个目标,而我们希望只识别主要的那个目标。因此我们的做法是设置个阈值,将小于阈值的像素置为零。范数的阈值
被指定为
中所有像素范数的百分位数。
4、Clipping pixels with small contribution
计算出每个像素对激活值的贡献,即把像素
置为0 ,看激活值增加还是减少。
,即把第
个像素置为0。这种方法直观但效率特别低,实现起来非常慢,因此文中采用了一种近似的求解方法。
,即梯度和
的内积,RGB三个通道相加,求绝对值,然后把贡献值低于阈值
的像素值设为0。这里将
近似看成
的线性函数,使得每维的贡献可以被
与梯度的内积算出来。
为了选出合适的一组超参数,采用随机搜索300个可能组合的方式最后找到4个较合适的组合。
以下内容摘自论文Visualizing higher-layer features of a deep network中的一部分:Maximizing the activation。解释了为什么可视化要最大化激活值。
最大化激活值
这个思想是很简单:我们寻找使一个给定的隐层单元的激活值最大的输入模式。因为第一层的每一个节点的激活函数都是输入的线性函数,所以对第一层来说,它的输入模式和滤波器本身是成比例的。
我们回顾下诺贝尔医学奖David Hubel 和Torsten Wiesel 的那个伟大的实验。他们发现了一种被称为“方向选择性细胞(Orientation Selective Cell)”的神经元细胞。当瞳孔发现了眼前的物体的边缘,而且这个边缘指向某个方向时,这种神经元细胞就会活跃。也就是说某个“特定方向神经细胞”只对这个特定方向的图像边缘存在激励或者兴奋。通俗点说就是如果我这个神经元是提取这个特征的,那么如果你这个图像满足这个特征(可以理解为和它很相似),那么神经元的输出就很大,会兴奋。(有资料表明,人的大脑高层会存在“祖母细胞”,这类细胞的某一个细胞只对特定一个目标兴奋,例如你大脑里面有个能记忆你女朋友的细胞,然后一旦你女朋友出现在你面前,你这个细胞就会兴奋,告诉大脑,啊,这个是我的女朋友!)我们如果了解过模板卷积,那么我们知道如果某个卷积模板与图像中模块越相似,那么响应就越大。相反,如果某个图像输入使得这个神经元输出激励值最大,那么我们就有理由相信,这个神经元就是提取了和这个输入差不多的特征。所以我们寻找可以使这个神经元输入最大的那个
就是我们可以可视化并且有意义的表达这个神经元学习到的特征了。
用数学属于来表述就是,一旦完成网络训练后,参数W是确定的了,那么我们就可以寻找使得这个神经元最大化的激活值对应的
了,也就是:
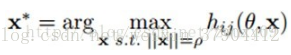
但这个优化问题通常是一个非凸优化问题,也就是是存在很多局部最小值。最简单的方法就是通过梯度下降去寻找到一个局部最小值。这会出现两种场景:一是从不同的随机值初始化开始最后都迭代得到相同的最小值,二是得到两个或者更多的局部最小值。不管是哪种情况,该神经节点提取的特征都可以通过找到的一个或者多个最小值进行描述。如果有多个最小值,那么可以寻找使激活值最大的或者将所有的进行平均,或者把所有的都显示出来。