Deep image prior阅读笔记
论文:《 Deep image prior 》
项目主页:https://dmitryulyanov.github.io/deep_image_prior
1. Introduction(介绍)
- CNN在图像生成和图像复原任务中应用广泛,效果好
- 有种解释是因为CNN能从大量数据中学到真实图像的先验知识,强调的是大量数据和学习能力,但是这种解释并不充分
- 作者认为网络的泛化能力要求网络结构应该契合数据结构
- 与普通解释中将CNN的效果归结于学习能力不同,本文表明大量的图像先验知识是由卷积网络的结构获取的,而不是通过大量数据的学习!
##2. 方法
在传统的图像复原方法中,常常是一个附加正则项的优化问题,目标函数如下:
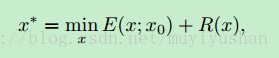
其中,E(x;x0)是与任务无关的数据项,比如MSE等,描述生成(或复原)图像与目标图像的差距,R(x)是正则项,是根据图像先验知识对解空间的约束。这些图像先验一般人为设计(hand-crafted),比如图像梯度重尾分布,total variation等。本文则提出使用卷积网络结构替换具有先验知识的正则项R(x),公式如下:
z为网络输入,f(z)为生成图像。上式的含义是,通过优化网络参数(使用梯度下降),使生成的图像与目标图像能满足目标函数E最小。而网络结构就能从图像中获取自然图像的结构模式,相当于替换了R(x)的作用。需要注意的是,当我们只有退化的图像,没有*’退化图像/原始图像* 训练对进行监督训练,所以输入的z是random code vector,类似GAN中的latent code。而目标图像就是退化图像。
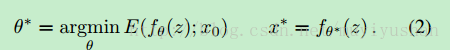
z大小与图像相同,初始化有有两种:1)random 2)meshigrid
网络结构如下:

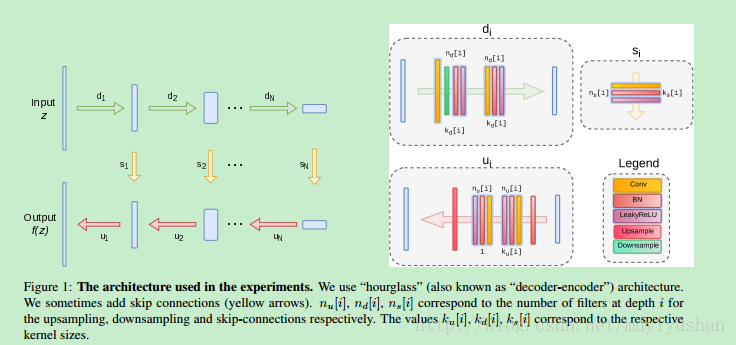
目标函数E的选取与任务有关,但是常用的就是MSE等l2 loss。总的来说,对于一张退化图像x0,输入z(随机初始化,训练时不变),通过输出f(z)与x0的loss不断迭代优化参数,直达输出达到满意的结果。
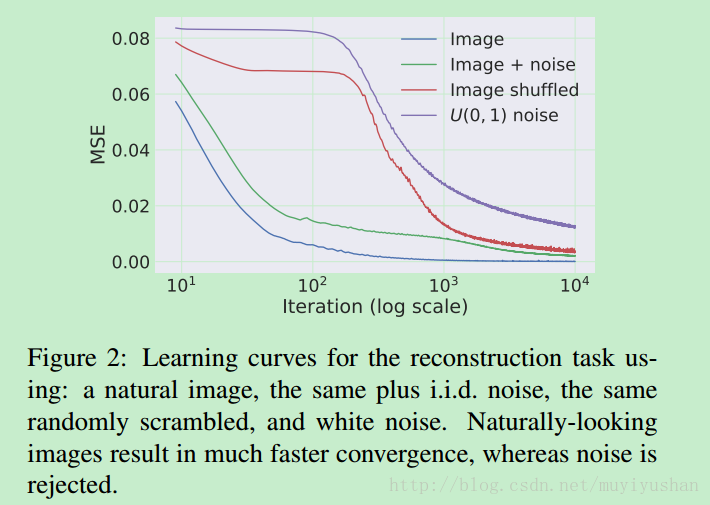
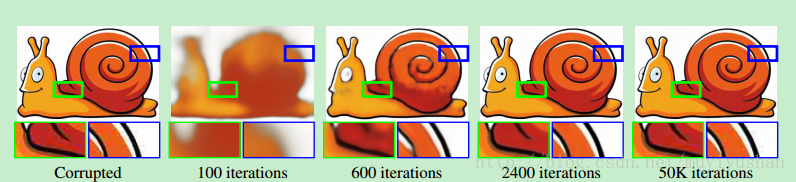
这里面个问题:针对不同任务,模型的收敛速度不同,如下图。对自然图像和加性噪声的图像拟合速度更快,对随机噪声图像和shuffled 图像拟合速度更慢。这就说了CNN对自然图像具有更强的倾向性,或者说CNN的网络结构对自然图像分布信息具有更好的捕获和模仿能力。论文说,CNN对信号阻抗小,对噪声阻抗大。因此对于大部分任务要限制网络的迭代次数,让CNN先拟合自然图像信号,而不是过拟合把噪声也捕获到。具体如何设置迭代次数,估计也要不断实验尝试。
3. Application(应用)
本方法在图像去噪,超分重建,图像修复上等取得不错效果。
本文方法适用场景:
1)难以建模图像退化过程
2)难以得到训练图像进行监督训练
这算是优点吧。
但是,在region inpainting 中,学习率的选择非常重要,也很敏感。调参估计不容易啊!

其他
另外,这个方法优点类似于基于self-similarity和基于字典的方法,但作者认为CNN与卷积稀疏码关系更接近,这块不了解,有空再看看。不多,antoencoder本身就是用一个自相似的度量方式训练网络,而本文类似gan中只是增加了一个latent space,用z做输入。

还有一个缺点就是: 计算量大。一张图像都要迭代几千次。
总而言之,本文思路比较清奇,做惯了end-2-end监督训练,这种思路还是挺有意思。CNN对自然图像信号阻抗低,对噪声阻抗大的结论也很有启发性,希望有更多后续工作发表出来。
[1]: http://math.stackexchange.com/