基于多元正则化度量学习的行人再识别
ABSTRACT
度量学习是行人再识别的有效方法。 它利用潜在因素找到适合测量距离的合适空间。 通常,少数因素不足以匹配行人,而大量因素导致高计算成本。 在本文中,为了平衡这种操作,提出了一种新的多元正则化距离度量学习方法。 对于特征表示,从源图像中提取局部判别特征,并且提出邻接最大约束以处理未对准的问题。 然后利用多样正则化容器通过使潜在因子不相关来学习度量,使得少量潜在因子可以在减少计算负担的同时保持测量距离的有效性。 我们的实验结果表明,与现有技术方法相比,所提出的具有少量因子的方法可以获得相对甚至更好的性能。
索引术语 - 人员重新识别,度量学习,多样性正则化,邻接最大约束
1. INTRODUCTION
行人重识别旨在从候选图像库中找到探测图像中的人。 它在智能视频监控中具有重要应用,如交叉摄像机跟踪,行人检测和人工检索。 然而,这在视觉监控中是一项非常具有挑战性的任务,因为不同视角中的个体的外观在观点,姿势,照明和遮挡等方面经历了很大的变化。在过去的几年中,已经研究了许多用于人重新识别的方法。 [1,2],在这个领域取得了很大的进步。
为了表示在各种条件下的行人重识别需要的具有辨别力的特征,[3]中提出的对称驱动的局部累积特征(SDALF)对于视点变化是稳健的,而Ma等人[4]结合了生物启发特征和协方差描述符(kBiCov),用于处理背景和光照变化。Liao等人 [5]通过最大化局部特征的水平发生和应用Retinex变换来处理不同类型的变化。 为了获得人员重新识别的显着性信息,Zhao等人[6]利用邻接约束策略来构建错位的斑块对应关系。 然而,如何设计涵盖用于行人再识别的各种条件的稳健特征表示仍然是一个具有挑战性的问题。 为了构建更全面和更健壮的行人描述符,我们通过最大化邻接水平区域采样的子窗口来扩展[5]。
除了提取判别特征之外,距离度量学习还被广泛用于行人再识别。Zheng等人[7]提出了概率相对距离比较(PRDC)方法,该方法将度量学习问题假设为一对匹配的概率。Martin等[8]旨在从等价约束(KISSME)中学习度量。 Alexis等[9]引入了成对约束分量分析(PCCA)算法,用于从稀疏成对相似性/不相似性约束中学习距离度量。Li等人在 [10]提出了局部自适应决策函数(LADF)的学习,它可以被视为距离度量和局部适应的阈值规则的联合模型。这些方法旨在学习合适的潜在空间,其可以被解释为将数据从原始特征空间投影到潜在空间。然而,他们中的大多数旨在学习表达信息来测量所有潜在因素的距离,这可能导致高计算成本。一些方法[11,8,12]直接应用PCA来减少特征尺寸,使得潜在因子的数量相应地减少。但是这种操作并不是最佳的,因为PCA不能保证维数减小的特征的可辨性。因此,为了缓解计算成本与判别性之间的矛盾,我们考虑潜在因素之间的关系,并对潜在因素强加多样性正则化,以使得它们不相关和正交。结果,少数组件能够捕获大部分信息。
这项工作的主要贡献可以概括为第三方。 首先,对于特征表示,设计邻接最大约束来处理由视点变化和姿势变化引起的错位问题。其次,我们提出了一种新颖有效的度量学习方法,它利用对数损失函数来增强成本评估。 我们证明了我们的目标函数可以快速分离不相似的对,因为它们的成本很高。 第三,我们在行人再识别的距离度量中引入了一个多样性正则化器,它可以通过减少潜在因子的数量来降低计算复杂度,同时保持匹配各种图像的有效能力。
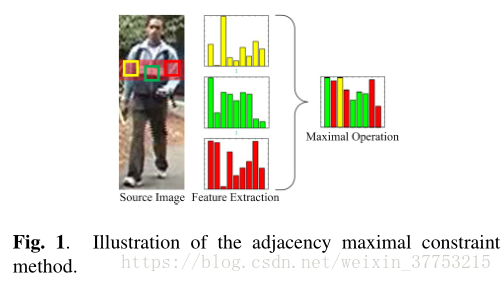
2. FEATURE REPRESENTATION
2.1. Local feature extraction
已经证明,颜色和纹理特征对于行人再识别是成功的。 我们将[5]中提出的局部极大发生(LOMO)特征与邻接约束相结合。 LOMO功能首先将Retinex变换应用于图像预处理应对光照变化。 然后提取一组滑动窗口,大小为10×10,步长为5像素。 每个子窗口从图像中提取HSV颜色直方图和尺度不变局部三元模式(SILTP)。 对于尺度变化和视点变化的问题,建立三尺度金字塔并分别计算水平最大值。
2.2. Adjacency maximal constraint
在我们的工作中,提出邻接最大约束以进一步考虑未对准问题而不是水平视点变化。 我们将15个像素的大小定义为放宽的相邻垂直区域,然后以2个像素的步长随机采样相同区域中每列的子窗口。 最后,计算来自邻接区域的所有子窗口的最大操作以克服未对准。 图1显示了所提出的邻接最大约束的过程。 总之,该特征最终由具有26960维度的描述符向量表示。我们将组合特征表示为局部邻接最大特征(LAMF)。
3. DIVERSITY REGULARIZED METRIC LEARNING
3.1. Distance metric learning
大多数距离度量学习方法选择学习一个马氏距离

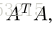

其中,
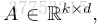

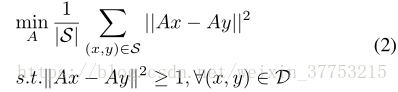
其中,

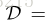
3.2. Diversify distance metric learning
在[13,14]中研究了增强潜在变量模型中潜在因子多样性的问题,以减少潜在因子的冗余并改善独特潜在特征的覆盖范围。
所提出的多样性方法基于[13],它对潜在因素施加了正则化,以使得它们接近正交性。 给定

一个较大的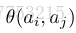
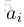
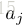


其中,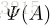


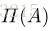

为了让潜在的因素多样化,我们定义一个多样规则化的度量学习问题如下:

其中,术语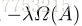
3.3. Optimization
在本节中,我们展现一个算法来解决定义在等式(5)中的问题。在[15]中先进的采样技术启发下,我们建议忽略那些已经很好分离的样本并专注于未分离的样本。类似于基于有效的Impostor度量学习(EIML)分类[11],我们定义一个来自于不相似对的子集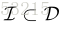
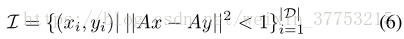
为了增加对欺骗者的惩罚,采用标准对数损失函数来增强损失评估,记为:

与铰链损失函数相比,对数损失函数具有较大的损失值,随着x的减小而迅速增大,如图2 (a)所示,引入对数损失函数来提高相似对的成本,得到:

此外,我们的方法具有较快的收敛速度。图2(b)表明我们的方法仅在20次迭代后收敛,且替用者分离速度快。
为了便于优化,让




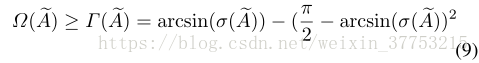
其中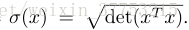


其中,


4. EXPERIMENTS
4.1. Datasets and evaluation protocol
我们通过对三个广泛使用的数据集进行实验来评估我们的方法。数据集和实验协议的细节描述在后面。
VIPeR dataset [16]包含632对人,从两个不同的相机拍摄。所有图片缩放到128×48像素。该数据库中广泛采用的实验协议是将632对图像随机分为两组进行训练,另一组进行测试,重复10次以获得平均性能。
PRID 450S dataset [17]是一个新的更真实的数据集,建立在PRID 2011之上。它由450幅图像对,从两个不重叠的相机视图。在实验中,所有图片归一化168×80像素,我们使用与VIPeR数据集一样的实验协议。
iLIDS-VID dataset [18]包含600套图片为300人在机场。每个人有两个来自两个摄像头的图像集,其中每个图像集包含23到192个图像,平均数字为73。在我们的实验中,iLIDS-VID数据集用于多镜头场景。
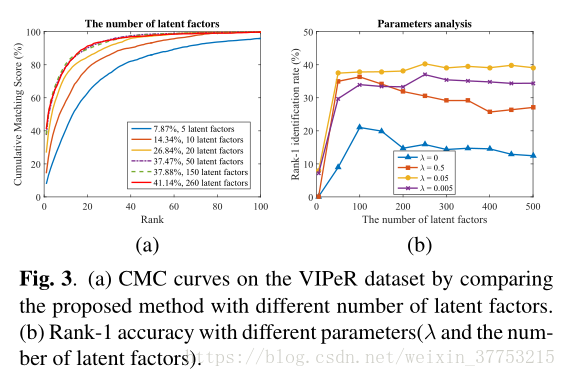

4.2. Parameters analysis and settings
在我们提出的方法中有两个关键参数:权衡参数λ和潜在因子k的数量。图3(a)显示了具有不同k的累积匹配特征(CMC)曲线。可以看出,随着k的增加,DRML整体上表现更好。图3(b)显示了随着k增加,rank-1精度如何随着不同的λ而变化。我们可以看到,学习具有多样性正则化的度量比没有多样性正则化(λ= 0)的度量要好得多。我们还看到,最初增加λ提高了rank-1的准确度,而继续增加λ会降低精度。原因是较大的λ会促使距离度量更加多样化,但是如果λ太大,则多样性正则化器可能主导距离损失并且会损害测量距离的有效性。当k很小时,rank-1的精度很低。这是因为小的k会使距离矩阵的效率降低。随着k增加,模型容量增加并且rank-1准确度相应地增加。但是,由于数据过度拟合,进一步增加k会导致性能下降。总之,需要选择适当的λ和k以实现最佳平衡,并且对于所有后续实验我们选择λ= 0.05和k = 260。

4.3. Comparison with the state-of-the-art methods
在VIPeR,PRID 450S和iLIDS-VID数据集上进行了与最先进方法的比较实验。表1显示具有LOMO特征的DRML在等级1的VIPeR上获得比较性能,并且最终LAMF + DRML优于所有其他rank-1的最先进的方法有260个潜在因素。 此外,在表2和表3中,我们提出的方法分别在PRID 450S和iLIDS-VID数据集上改进了rank-1的第二最佳方法,分别为12.04%和8.6%。 大多数度量学习方法都适用于PCA以减少特征维度。 但是,它们并不是最佳的,因为PCA不考虑距离度量学习。 合理的解释是DRML使得潜在因素不相关并单独捕获独特的信息。 因此,可以广泛地减少潜在因素的数量。
5. CONCLUSIONS
本文提出了一种局部特征的邻接约束策略和一种用于行人再识别的多样性正则化距离度量学习方法。 邻接约束充分考虑了未对准,并且多样化鼓励潜在因素彼此不同,目的是学习紧凑度量。 对三种广泛使用的挑战性数据集的实验证明了所提出方法的有效性。
6. ACKNOWLEDGMENTS
This work was supported by Shenzhen Engineering Laboratory of Broadband Wireless Network Security, and the Macao Science and Technology Fund: FDCT/056/2012/A2, and UM Multi-year Research Grant: MYRG2014-00009-FST.
7. REFERENCES
[1] Shaogang Gong, Marco Cristani, Shuicheng Yan, and
Chen Change Loy, Person re-identification, vol. 1,
Springer, 2014.
[2] Roberto Vezzani, Davide Baltieri, and Rita Cucchiara,
“People reidentification in surveillance and forensics: A
survey,” ACM Computing Surveys (CSUR), vol. 46, no.
2, pp. 29, 2013.
[3] Loris Bazzani, Marco Cristani, and Vittorio Murino,
“Symmetry-driven accumulation of local features for
human characterization and re-identification,” Com-
puter Vision and Image Understanding, vol. 117, no. 2,
pp. 130–144, 2013.
[4] Bingpeng Ma, Yu Su, and Frederic Jurie, “Covariance
descriptor based on bio-inspired features for person re-
identification and face verification,” Image and Vision
Computing, vol. 32, no. 6, pp. 379–390, 2014.
[5] Shengcai Liao, Yang Hu, Xiangyu Zhu, and Stan Z Li,
“Person re-identification by local maximal occurrence
representationandmetriclearning,” inIEEEConference
on Computer Vision and Pattern Recognition (CVPR),
2015, pp. 2197–2206.
[6] Rui Zhao, Wanli Ouyang, and Xiaogang Wang, “Person
re-identification by salience matching,” in IEEE Inter-
national Conference on Computer Vision (ICCV), 2013,
pp. 2528–2535.
[7] Wei-Shi Zheng, Shaogang Gong, and Tao Xiang, “Per-
son re-identification by probabilistic relative distance
comparison,” in IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), 2011, pp. 649–656.
[8] Martin Koestinger, Martin Hirzer, Paul Wohlhart, Pe-
ter M Roth, and Horst Bischof, “Large scale metric
learning from equivalence constraints,” in IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), 2012, pp. 2288–2295.
[9] Alexis Mignon and Frédéric Jurie, “Pcca: A new ap-
proach for distance learning from sparse pairwise con-
straints,” in IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), 2012, pp. 2666–2672.
[10] Zhen Li, Shiyu Chang, Feng Liang, Thomas S Huang,
Liangliang Cao, and John R Smith, “Learning locally-
adaptive decision functions for person verification,”
in IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), 2013, pp. 3610–3617.
[11] Martin Hirzer, Peter M Roth, and Horst Bischof, “Per-
son re-identification by efficient impostor-based metric
learning,” in IEEE Ninth International Conference on
Advanced Video and Signal-Based Surveillance (AVSS),
2012, pp. 203–208.
[12] Fei Xiong, Mengran Gou, Octavia Camps, and Mario
Sznaier, “Person re-identification using kernel-based
metric learning methods,” in Computer Vision–ECCV
2014, pp. 1–16. Springer, 2014.
[13] Pengtao Xie, “Learning compact and effective dis-
tance metrics with diversity regularization,” in Machine
Learning and Knowledge Discovery in Databases, pp.
610–624. Springer, 2015.
[14] Pengtao Xie, Yuntian Deng, and Eric Xing, “Diversify-
ing restricted boltzmann machine for document model-
ing,” in Proceedings of the 21th ACM SIGKDD Inter-
national Conference on Knowledge Discovery and Data
Mining, 2015, pp. 1315–1324.
[15] Jong-Min Park and Yu Hen Hu, “On-line learning for
active pattern recognition,” Signal Processing Letters,
IEEE, vol. 3, no. 11, pp. 301–303, 1996.
[16] Douglas Gray, Shane Brennan, and Hai Tao, “Evalu-
ating appearance models for recognition, reacquisition,
and tracking,” in Proc. IEEE International Workshop on
Performance Evaluation for Tracking and Surveillance
(PETS), 2007, vol. 3.
[17] Peter M Roth, Martin Hirzer, Martin Köstinger, Csaba
Beleznai, and Horst Bischof, “Mahalanobis distance
learning for person re-identification,” in Person Re-
Identification, pp. 247–267. Springer, 2014.
[18] Taiqing Wang, Shaogang Gong, Xiatian Zhu, and
Shengjin Wang, “Person re-identification by video rank-
ing,” in Computer Vision–ECCV 2014, pp. 688–703.
Springer, 2014.
[19] Yang Yang, Jimei Yang, Junjie Yan, Shengcai Liao,
Dong Yi, and Stan Z Li, “Salient color names for person
re-identification,” in Computer Vision–ECCV 2014, pp.
536–551. Springer, 2014.
[20] Rui Zhao, Wanli Ouyang, and Xiaogang Wang, “Learn-
ing mid-level filters for person re-identification,” in
IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), 2014, pp. 144–151.
[21] Yang Shen, Weiyao Lin, Junchi Yan, Mingliang
Xu, Jianxin Wu, and Jingdong Wang, “Person re-
identification with correspondence structure learning,”
in IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), 2015, pp. 3200–3208.