行人重识别之摄像头视角
Camera viewpoint learning for person re-identification
这次分享一篇自己的文章,这篇文章针对了摄像头视角的问题。
先来说一个行人重识别中本质而又容易被忽略的问题:
行人重识别是跨摄像头检索任务,也就是说,找到同一个摄像头中的同一个人是没有意义的。最终计算准确率的时候,会把rank序列中和query摄像头视角相同且是同一个人的图像全部去除。
也就是说,和query摄像头视角相同的gallery在检索中都是没有意义的。我们可以视其为干扰图像。
这个问题其实挺严重的:同一摄像头下行人的类间距离往往小于不同摄像头下行人的类内距离。如下图,ci表示第i个摄像头视角。

所以,这篇文章提出了两个方法,两者相辅相成:
Mean and Variance Loss function (MVL)
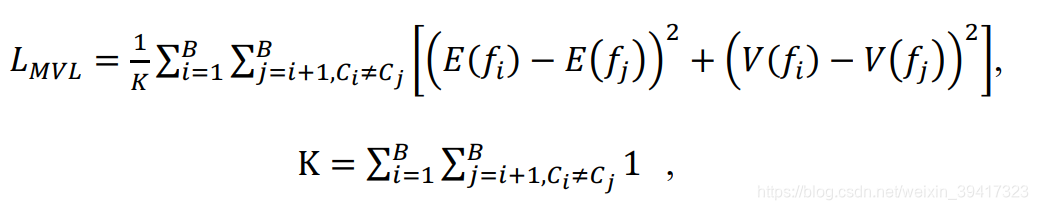
f代表特征向量,B是batchsize,c代表摄像头视角编号。所以mvl就是对不同摄像头视角下图像特征向量的均值之间和方差之间的差异性进行惩罚。也就是约束了特征向量的统计特征,使得网络对于不同摄像头视角下的图像一视同仁。
实验结果如下:
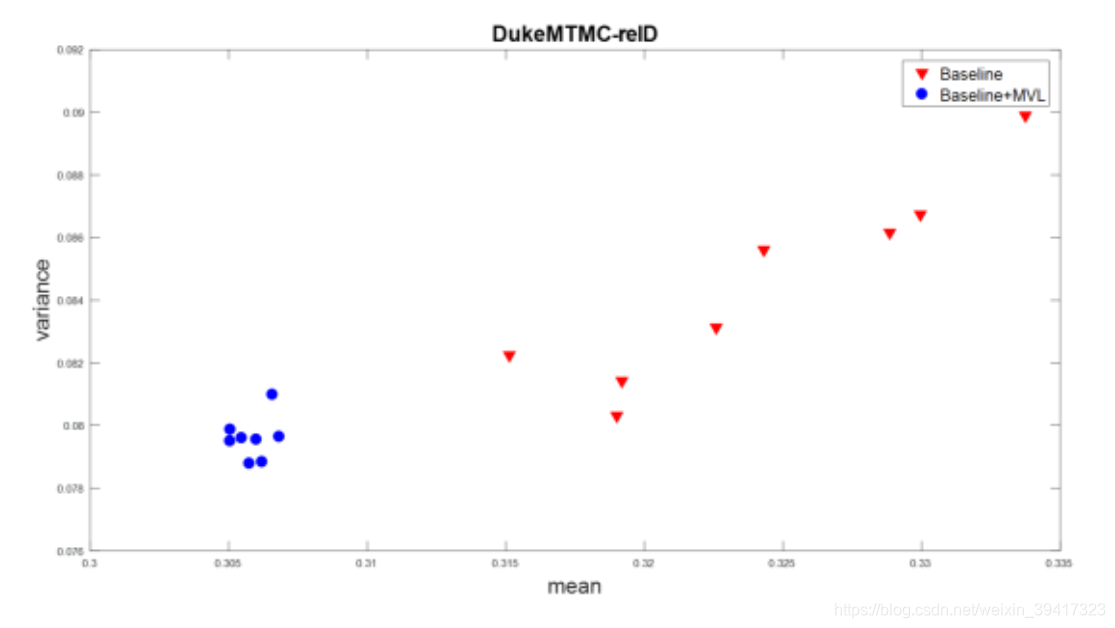
每一个点代表一个摄像头视角下所有特征向量均值和方差的平均值。可以发现,使用MVL后,摄像头视角间的差异性缩小了。
The Camera Id Classifier (CIC)
基于最开始的结论,和query摄像头视角相同的gallery都是干扰图像。那么,我们可以直接识别图像和query的摄像头视角是否相同,如果相同,直接过滤掉。
所以我们用图像的摄像头视角id作为标签,训练一个网络。在测试的过程中,该网络提取query和gallery的特征向量,进行比较,根据阈值,判断是否属于同一个摄像头视角。
我最开始觉得这个方案不可行,因为觉得很多不同视角的图像看上去非常像同一个视角。然而,我低估了深度学习…训练后,直接识别的准确率至少都能达到70%以上的水平。(对于market1501是6分类,对于duke是8分类,两者的平均识别准确率分别是79.71%和85.33%)如果比较特征向量的差异性判断是否属于同一视角,那么准确率又会大幅提高。
最后,附上两张实验结果图:


总结:一篇创新性很弱,但是比较实用的文章。可以作为re-id的tricks。
完
欢迎讨论 欢迎吐槽
