Improving Person Re-identification by Attribute and Identity Learning
论文链接
1.摘要&介绍
(1)Re-ID:全局特征,Attribute recognition:局部特征。将这两个方面融合形成新的网络APR,在CNN的基础结构上改进。
(2)Person Re-ID是在非重叠相机下找到查询行人;Attribute recognition是预测一张图像出现的属性。
(3)与之前研究的不同之处:1) 大多方法使用attribute加强元组或三元组之间的联系。历史上,这种方法的出现是因为数据集通常每个行人身份只提供两张图像。但是最近的数据集比如Market-1501和DukeMTMC-reID对每一个类都提供了大量的训练样例。并且classification模型的效果比siamese模型的效果更好。这篇文章因此使用classification CNN模型训练Multi-TASK网络。2)我们试验看re-ID是否能提高attribute recognition的准确度。这篇文章我们主要关注ID-level(人本身)的属性而不是instance-level(人在特定时刻,如打电话、骑车等等)的属性。
(4)这是第一次为Re-ID将attribute融入classification CNN模型。网络基于两条baseline网络创建,一条Re-ID,另一条attribute recognition。
2.相关的工作
(1)CNN-based person re-ID
①重识别领域被基于CNN的算法支配,分为两种:深度度量学习(deep metric learning) &深度表示学习(deep representation learning)
②deep metric learning:对网络输入图片二元组或者三元组。通常将空间约束加入到相似度学习过程中(如门函数加入卷积层可以捕获到细微的差异)。更适合于较小的数据集,其效率在大型数据集上不行。
③deep representation learning:较高的准确度和效率。
④本文用这一条做re-ID的baseline.
(2)Attributes for person re-ID
①多数研究只是将属性(attributes)作为re-ID的辅助。(而不是另外生成一个新的网络来计算LOSS,再将其与re-ID融合)
(3)Attributes for face applications
①通过属性进行面部识别历史悠久。[43]文中的 CNNs通过面部各个区域识别人,这是我们所使用的网络结构。但实施时这个方法很耗时。
3.(两个数据集)属性(的人工)标记
对两个数据集(Market-1501,DukeMTMC-reID)重新标注,Market-1501新添27个属性标记,DukeMTMC-reID新添23个属性标记。
4.提出算法
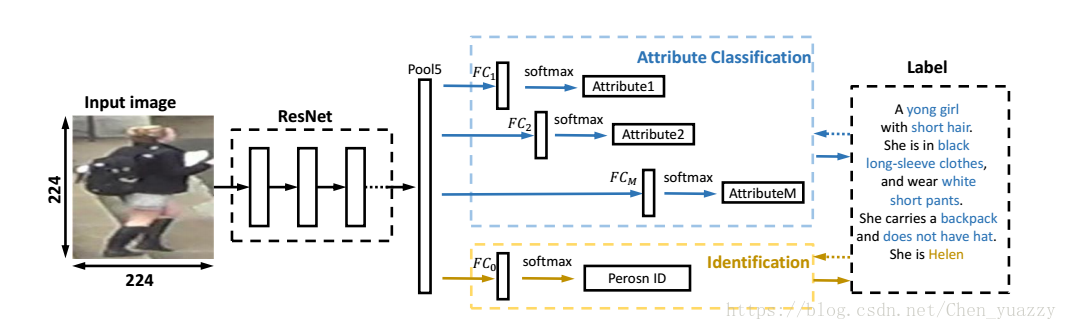
(1)4.1 基准方法:
①Resnet-50为基础网络,并在Imagenet上预先训练。再分别用新注释的attribute和现有的id标签进行微调(fine-tune)(精细调整)。
②Person re-ID : 最后一层全连接层K个神经元,代表训练身份为K。全连接层之前有dropout层(避免过拟合,dropout率为0.9)。在测试时,对于每一个query和gallery图像,都从Pool5层抽取2048维特征向量。对于每一个query,计算query和gallery特征之间的欧氏距离,在排序步骤之前。
③Pedestrian attribution recognition &re-ID:有M个全连接层,最后有一个softMax层。M代表属性的数量。全连接层之前也有dropout层。CaffeNet中,M个FC层代替了FC8层。ResNet-50中,他们代替了FC层。对于m个类的Attributes,FC层是m维的。
(2)Attribute-Person Recognition(APR)network:
①APR由base model,M+1个全连接层(在loss计算前),1个ID classification的loss和M个attribute的loss。M代表M个属性,1代表re-ID。FC0用来做ID分类,剩下FC1-FCM的用来做属性识别。 图像尺寸(224*224->resnet-50,227*227->caffenet)
Loss计算:
假设有n张图像,K个身份。每个身份有M个属性。Di={xi,di,li},xi代表第i张图像,di代表xi图像的身份,li={li1,li2,….liM}代表xi的M个属性标签集。
给定训练样本x,我们的模型首先计算了pool5描述符f。输出向量为1*1*2048.FC0层的输出为z=[z1,z2,…,zk]。所以每一个ID标签k的预测概率为:
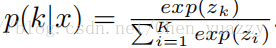
忽略k和x之间的关联,ID classification的cross entropy loss被写成如下形式:
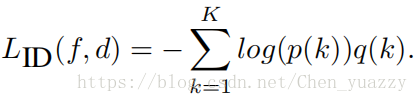
假设y是ground-truth的ID标签,q(y)=1且q(k)=0(k!=y)。因此,最小化loss等同于最大化指定ground-truth类的概率。
我们也使用了M个softmax loss作为attribute预测。假定某一attribute有m个类,指定样例x,attribute类j的概率为:
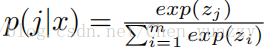
相似的。loss写成如下形式:
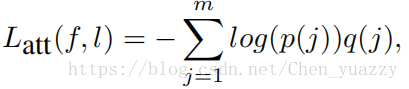
ym是ground-truth的attribute标签。Q(ym)=1且q(j)=0(j!=ym)。
最终的loss为如下形式:
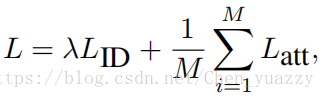
参数λ平衡两个loss的贡献,取决于Market-1501的验证集。
5.实验(过程和结果)(详见原论文,多种测评角度,值得学习)
(1)数据集和评估协议
①Market-1501
②DukeMTMC-reID
③评估尺度
(2)实现细节
(3)Re-ID的评估
①参数验证
②属性识别提高re-ID准确度(比基准)
③与最佳方法比较
④相机对之间的比较结果
⑤学习的可扩展性
⑥消融学习(除去一部分的属性变量)
(4)Attribute recognition的评估
6.结论
7.引文