1. 任务设置
U n s u p e r v i s e d D o m a i n A d a p t a t i o n f o r I m a g e C l a s s i f i c a t i o n \rm Unsupervised~Domain~Adaptation~for~Image Classification Unsupervised Domain Adaptation for ImageClassification
2. 符号与任务定义
| 符号 | 意义 | 备注 |
|---|---|---|
| S \mathcal S S | 源域数据集,有配对数据 S = { ( x 1 s , y 1 s ) , . . . , ( x N s s , y N s s ) } \mathcal S=\{(x_1^s,y_1^s),...,(x_{N_s}^s,y_{N_s}^s)\} S={ (x1s,y1s),...,(xNss,yNss)} |
N s N_s Ns表示数据集大小 |
| T \mathcal T T | 目标域数据集,无标签 T = { x 1 t , . . . , x N t t } \mathcal T=\{x_1^t,...,x_{N_t}^t\} T={ x1t,...,xNtt} |
N t N_t Nt表示数据集大小 |
| y s y^s ys/ y t y^t yt | 类别标签 y s ∈ { 0 , 1 , . . . , M − 1 } y^s\in\{0,1,...,M-1\} ys∈{ 0,1,...,M−1}, y t ∈ { 0 , 1 , . . . , M − 1 } y^t\in\{0,1,...,M-1\} yt∈{ 0,1,...,M−1} |
这个任务要求源域与目标域是对同样的类别集合的图像数据集 |
| Φ θ \Phi_\theta Φθ | 是对图像提取特征的网络,有 L \mathcal L L层 | 记: l ∈ L l\in \mathcal L l∈L |
| ϕ l ( x ) \phi_l(x) ϕl(x) | 网络提取的 x x x在第 l l l层的特征 |
U D A \rm UDA UDA的目的就是通过使用有标签的数据集 S \mathcal S S和无标签的数据集 T \mathcal T T来训练一个网络,这个网络能够对 T \mathcal T T上的样本作出正确的分类 { y ^ t } \{\hat y^t\} { y^t}。
3. 方法
3.1 回顾MMD(Maximum Mean Discrepancy Revisit:最大平均差异)
在
MMD中,我们假设源域和目标域的数据集来自两个独立的边缘分布 P ( X s ) P(X^s) P(Xs) 和 Q ( X t ) Q(X^t) Q(Xt),因此这两个数据集作为从两个分布分别抽取的样本 { x i s } \{x_i^s\} { xis} 和 { x i t } \{x_i^t\} { xit} 是 i . i . d i.i.d i.i.d。
在直觉上,`MMD` 认为如果两个分布是等同的,这两个分部的所有统计数据就应该是一样的。
在形式上,我们定义 `MMD` 位再生核希尔伯特空间(the reproducing kernel Hibert space/RKHS)中,两个分部的样本的平均编码之间的某种距离,我们要最小化它。即:
D H ( P , Q ) = △ sup f ∼ H ( E X s [ f ( X s ) ] − E X t [ X t ] ) H (1) \mathcal D_{\mathcal H}(P,Q) \overset{\bigtriangleup}{=} \sup_{f\sim\mathcal H}(\mathbb E_{X^s}[f(X^s)]-\mathbb E_{X^t}[X^t])_{\mathcal H}\tag{1} DH(P,Q)=△f∼Hsup(EXs[f(Xs)]−EXt[Xt])H(1)
在实际应用中,我们通常是取每个数据集中的一个 m i n i b a t c h mini~batch mini batch S ′ ⊂ S \mathcal S'\subset \mathcal S S′⊂S 和 T ′ ⊂ T \mathcal T' \subset \mathcal T T′⊂T,假设大小分别为: n s = ∣ S ′ ∣ n_s=|\mathcal S'| ns=∣S′∣, n t = ∣ T ′ ∣ n_t=|\mathcal T'| nt=∣T′∣,则在每次迭代中,我们可以计算
MMD为:D ^ l m m d = 1 n s 2 ∑ i = 1 n s ∑ j = 1 n s k l ( ϕ l ( x i s ) , ϕ l ( x j s ) ) + 1 n t 2 ∑ i = 1 n t ∑ j = 1 n t k l ( ϕ l ( x i t ) , ϕ l ( x j t ) ) − 2 n s n t ∑ i = 1 n s ∑ j = 1 n t k l ( ϕ l ( x i s ) , ϕ l ( x j t ) ) (2) \hat{\mathcal D}_l^{mmd}={1\over{n_s^2}}\sum_{i=1}^{n_s}\sum_{j=1}^{n_s}k_l(\phi_l(x_i^s), \phi_l(x_j^s))\\+{1\over{n_t^2}}\sum_{i=1}^{n_t}\sum_{j=1}^{n_t}k_l(\phi_l(x_i^t), \phi_l(x_j^t))\\-{2\over{n_sn_t}}\sum_{i=1}^{n_s}\sum_{j=1}^{n_t}k_l(\phi_l(x_i^s), \phi_l(x_j^t))\tag{2} D^lmmd=ns21i=1∑nsj=1∑nskl(ϕl(xis),ϕl(xjs))+nt21i=1∑ntj=1∑ntkl(ϕl(xit),ϕl(xjt))−nsnt2i=1∑nsj=1∑ntkl(ϕl(xis),ϕl(xjt))(2)
上式其实就是类似求欧几里得距离的 ( a − b ) 2 (a-b)^2 (a−b)2 公式。
基于上面的整个数据分布的宏观拉近,导致的结果如下图中所示:明显的不足是忽略了两个域内部的不同类别的数据分布之间的微观结构不同,宏观的拉近导致了微观结构的不严格对齐。类似于上一篇文章:如下图右,致力于两个域的微观结构中,相同类的数据的分布分别拉近、对齐。
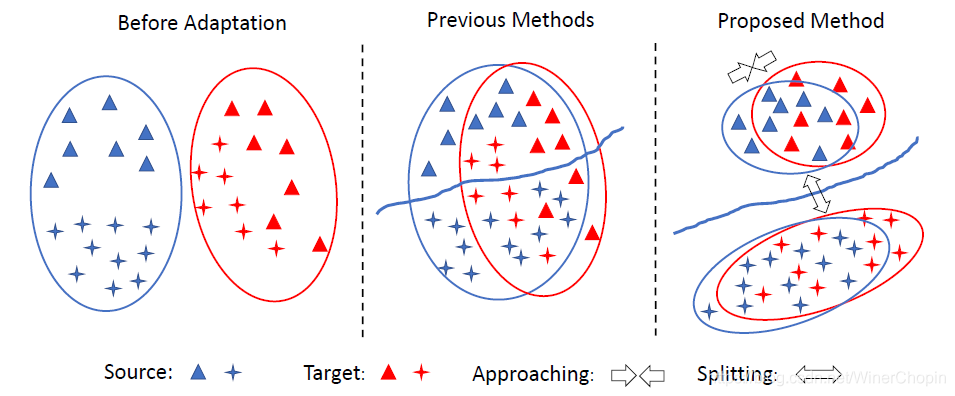
3.2 对比性域差异(Contrastive Domain Discrepancy/CDD)
原文:
""" To explicitly take the class information into account and measure (1)the intra-class(类内) and (2)inter-class(类间) discrepancy (3)across domains ... Yhe intra-class and inter-class discrepancied are jointly optimized to improve the adaptation performance. """
CDD是加入类别标签作为条件后的MMD,即它是对两个域的 m i n i b a t c h mini~batch mini batch 数据中分别用单独一个类别的数据去计算MMD,如果是两个相同的类则最小化这个差异,否则最大化这个差异。
现在我们有 c o n d i t i o n a l conditional conditional 数据集合: P ( ϕ ( X s ) ∣ Y s ) P(\phi(X^s)|Y^s) P(ϕ(Xs)∣Ys) 与 Q ( ϕ ( X t ) ∣ Y t ) Q(\phi(X^t)|Y^t) Q(ϕ(Xt)∣Yt),我们假设存在某个判断函数:
μ c c ′ ( y , y ′ ) = { 1 i f y = c , y ′ = c ′ ; 0 o t h e r w i s e . (3) \mu_{cc'}(y,y')=\begin{cases} 1& {\rm if} ~y=c,y'=c';\\ 0& {\rm otherwise.} \end{cases}\tag{3} μcc′(y,y′)={ 10if y=c,y′=c′;otherwise.(3) 即我们只对指定的类别 c c c 和 c ′ c' c′ 计算差异值。
我们可以定义我们的CDD为:D ^ c 1 c 2 ( ∘ , ϕ ) = e 1 + e 2 − 2 e 3 (4) \hat {\mathcal D}^{c_1c_2}(\circ, \phi)=e_1+e_2-2e_3\tag{4} D^c1c2(∘,ϕ)=e1+e2−2e3(4) ,其中有:
e 1 = ∑ i = 1 n s ∑ j = 1 n s μ c 1 c 1 ( y i s , y j s ) ⋅ k ( ϕ ( x i s ) , ϕ ( x j s ) ) ∑ i = 1 n s ∑ j = 1 n s μ c 1 c 1 ( y i s , y j s ) ← 求 均 值 的 基 数 e 2 = ∑ i = 1 n t ∑ j = 1 n t μ c 2 c 2 ( y ^ i t , y ^ j t ) ⋅ k ( ϕ ( x i t ) , ϕ ( x j t ) ) ∑ i = 1 n t ∑ j = 1 n t μ c 2 c 2 ( y ^ i t , y ^ j t ) e 3 = ∑ i = 1 n s ∑ j = 1 n t μ c 1 c 2 ( y i s , y ^ j t ) ⋅ k ( ϕ ( x i s ) , ϕ ( x j t ) ) ∑ i = 1 n s ∑ j = 1 n t μ c 1 c 2 ( y i s , y ^ j t ) (5) e_1=\sum_{i=1}^{n_s}\sum_{j=1}^{n_s}{ {\mu_{c_1c_1}(y_i^s, y_j^s)\cdot k(\phi(x_i^s),\phi(x_j^s))}\over{\sum_{i=1}^{n_s}}\sum_{j=1}^{n_s}\mu_{c_1c_1}(y_i^s,y_j^s)\leftarrow求均值的基数} \\e_2=\sum_{i=1}^{n_t}\sum_{j=1}^{n_t}{ {\mu_{c_2c_2}(\hat y_i^t, \hat y_j^t)\cdot k(\phi(x_i^t),\phi(x_j^t))}\over{\sum_{i=1}^{n_t}}\sum_{j=1}^{n_t}\mu_{c_2c_2}(\hat y_i^t,\hat y_j^t)} \\e_3=\sum_{i=1}^{n_s}\sum_{j=1}^{n_t}{ {\mu_{c_1c_2}(y_i^s,\hat y_j^t)\cdot k(\phi(x_i^s),\phi(x_j^t))}\over{\sum_{i=1}^{n_s}\sum_{j=1}^{n_t}\mu_{c_1c_2}(y_i^s,\hat y_j^t)}} \tag{5} e1=i=1∑nsj=1∑ns∑i=1ns∑j=1nsμc1c1(yis,yjs)←求均值的基数μc1c1(yis,yjs)⋅k(ϕ(xis),ϕ(xjs))e2=i=1∑ntj=1∑nt∑i=1nt∑j=1ntμc2c2(y^it,y^jt)μc2c2(y^it,y^jt)⋅k(ϕ(xit),ϕ(xjt))e3=i=1∑nsj=1∑nt∑i=1ns∑j=1ntμc1c2(yis,y^jt)μc1c2(yis,y^jt)⋅k(ϕ(xis),ϕ(xjt))(5)我们可以看出,与
MMD的计算方式是一模一样的。只不过多了类别的标签来决定哪些数据不参与计算,哪些参与计算。
我们知道, T \mathcal T T 域是没有标签的 G T \rm GT GT 的,因此作者和其他的 U D A \rm UDA UDA 使用同样的方法(伪标签或者 K K K-聚类),得到对应的暂时的分类 { y ^ i t } \{\hat y_i^t\} { y^it}。
既然源域数据是有 G T \rm GT GT 的,那么公式 4 的变量就是: ∘ = { y ^ 1 t , y ^ 2 t , . . . , y ^ n t t } = y ^ 1 : n t t \circ=\{\hat y_1^t, \hat y_2^t,...,\hat y_{n_t}^t\}=\hat y_{1:n_t}^t ∘={ y^1t,y^2t,...,y^ntt}=y^1:ntt
最后对于两个域的所有类别的数据分布之间,我们定义完整CDD为:
D ^ c d d = 1 M ∑ c = 0 M − 1 D c c ^ ( y ^ 1 : n t t , ϕ ) ⏟ i n t r a − c l a s s − 1 M ( M − 1 ) ∑ c = 1 M − 1 ∑ c ′ = 1 , c ′ ≠ c M − 1 D ^ c c ′ ( y ^ 1 : n t t , ϕ ) ⏟ i n t e r − c l a s s (6) \hat{\mathcal D}^{cdd}=\underbrace{ {1\over M}\sum_{c=0}^{M-1}\hat {\mathcal D^{cc}}(\hat y_{1:n_t}^t,\phi)}_{intra-class}\\ \underbrace{-{1\over{M(M-1)}}\sum_{c=1}^{M-1}\sum_{c'=1,c'\neq c}^{M-1}\hat {\mathcal D}^{cc'}(\hat y_{1:n_t}^t,\phi)}_{inter-class}\tag{6} D^cdd=intra−class M1c=0∑M−1Dcc^(y^1:ntt,ϕ)inter−class −M(M−1)1c=1∑M−1c′=1,c′=c∑M−1D^cc′(y^1:ntt,ϕ)(6) 公式的意思是:(1)对所有的类别,目标域的样本分布要分别与源域相同类别的样本分布在某一层特征空间中拉近;(2)对于所有的类别,目标域的某个类别 c ′ c' c′ 的样本分布要与源域所有不同类别 c c c 的样本分布都拉开距离(最大化差异)。
对比
我们可以发现:上一篇文章通过在单独每个域内,用 triplet loss 实现类内拉近类间相疏,再借由 conditional feature loss 来实现两个域的微观结构对齐(对应类别的样本的编码embedding的中心要尽可能一致);而这一篇文章则是通过跨域的同类相近异类相疏同时实现类间的相疏和类内的相近,以及域间微观结构对齐。
3.3 CAN: Contrastive Adaptation Network
将上面讲的
CDD作为 loss 函数的正则项,引入到一般的分类网络如 R e s N e t \rm ResNet ResNet 中即可,即:
min θ l = l c r o s s e n t r o p y + β D ^ L c d d (7) \min _{\theta} \mathcal l=\mathcal l^{cross~entropy}+\beta \hat{\mathcal D}_{\mathcal L}^{cdd}\tag{7} θminl=lcross entropy+βD^Lcdd(7),其中,
l c r o s s e n t r o p y = − 1 n s ′ ∑ i ′ = 1 n s ′ log P θ ( y i ′ s ∣ x i ′ s ) (8) \mathcal l^{cross~entropy}=-{1\over{n'_s}}\sum_{i'=1}^{n'_s}\log P_\theta(y_{i'}^s|x_{i'}^s)\tag{8} lcross entropy=−ns′1i′=1∑ns′logPθ(yi′s∣xi′s)(8) D ^ L c d d = ∑ l = 1 L D ^ c d d (9) \hat{\mathcal D}_{\mathcal L}^{cdd}=\sum_{l=1}^L \hat{\mathcal D}^{cdd} \tag{9} D^Lcdd=l=1∑LD^cdd(9)
3.4 优化 CAN
模型和目标函数都有了,那怎么优化呢?
Alternative Optimization( A O \rm AO AO)(交替式优化)在每次迭代中,固定网络参数 ϕ \phi ϕ,给定当前的特征表征,更新目标域的样本聚类;之后基于更新了的目标标签,我们计算
CDD,并最小化它来更新网络参数。
譬如说,在 R e s N e t \rm ResNet ResNet 中,每个样本能够被表示为 G A P \rm GAP GAP 层后的向量;我们有 M M M 类,所以聚类数为 K = M K=M K=M。
1)使用源域的数据的表征计算每个类别的样本编码中心: O s , c O^{s,c} Os,c,其中 c c c 是某个特定的类别,我们用这些源域中心初始化目标域的 K K K-聚类的中心 O t , c O^{t,c} Ot,c,其中: O s c = ∑ i = 1 n s 1 y i s = c ϕ l ( x i s ) ∣ ∣ ϕ l ( x i s ) ∣ ∣ O^{sc}=\sum_{i=1}^{n_s}1_{y_i^s=c}{ {\phi_l(x_i^s)}\over{||\phi_l(x_i^s)||}} Osc=∑i=1ns1yis=c∣∣ϕl(xis)∣∣ϕl(xis), 1 y i s = c = { 1 i f y i s = c ; 0 o t h e r w i s e . 1_{y_i^s=c}=\begin{cases} 1& {\rm if} ~y_i^s=c;\\ 0& {\rm otherwise.} \end{cases} 1yis=c={ 10if yis=c;otherwise., c = { 0 , 1 , . . . , M − 1 } c=\{0,1,...,M-1\} c={ 0,1,...,M−1}。
2)计算样本与中心之间的距离,我们使用余弦相似度,即: d i s t ( a , b ) = 1 2 ( 1 − a ⋅ b ∣ ∣ a ∣ ∣ ∣ ∣ b ∣ ∣ ) dist(a,b)={1\over 2}(1-{ {a\cdot b}\over{||a||~||b||}}) dist(a,b)=21(1−∣∣a∣∣ ∣∣b∣∣a⋅b);
3)聚类的过程是迭代的:① 对每个目标域的样本找到所对应的聚类中心: y ^ i t = arg min c d i s t ( ϕ ( x i t ) , O t c ) \hat y_i^t=\argmin_c dist(\phi(x_i^t), O^{tc}) y^it=cargmindist(ϕ(xit),Otc);② 更新聚类中心: O t c ← ∑ i = 1 N t 1 y ^ i t = c ϕ 1 ( x i t ) ∣ ∣ ϕ 1 ( x i t ) ∣ ∣ O^{tc}\leftarrow \sum_{i=1}^{N_t}1_{\hat y_i^t=c}{ {\phi_1(x_i^t)}\over{||\phi_1(x_i^t)||}} Otc←∑i=1Nt1y^it=c∣∣ϕ1(xit)∣∣ϕ1(xit);迭代知道收敛或者抵达最大聚类步数停止;
4)聚类结束后,每个目标域的样本 x i t x_i^t xit 被赋予一个标签 y ^ i t \hat y_i^t y^it(对应隶属的聚类);
5)此外,我们设定一个阈值 D 0 ∈ [ 0 , 1 ] D_0\in [0,1] D0∈[0,1],将属于某个簇但是距离仍然超过给定阈值(即余弦相似度值小于 D 0 D_0 D0)的数据样本删除,不参与本次计算CDD: T ^ = ( x t , y ^ t ) ∣ d i s t ( ϕ l ( x t ) , O t , y ^ t ) < D 0 , x t ∈ T \hat {\mathcal T}={(x^t,\hat y^t)|dist(\phi_l(x^t),O^{t,\hat y^t})<D_0,x^t\in \mathcal T} T^=(xt,y^t)∣dist(ϕl(xt),Ot,y^t)<D0,xt∈T;
6)更有甚者,我们为了提供更准确的样本分布的统计数据,我们假设每个类别挑选出来的集合 T ^ \hat \mathcal T T^ 的大小至少包含某个数量的样本,不然这个类别本次也不参与计算,即最后参与计算的类别与样本集为: C T e = { c ∣ ∑ i ∣ T ^ ∣ 1 y ^ i t = c > N 0 , c ∈ { 0 , 1 , . . . , M − 1 } } \mathcal C_{T_e}=\{c|\sum_i^{|\hat \mathcal T|}1_{\hat y_i^t=c}>N_0,c\in\{0,1,...,M-1\}\} CTe={ c∣∑i∣T^∣1y^it=c>N0,c∈{ 0,1,...,M−1}}。训练一开始的时候,因为存在 domain shift,只有部分的类的样本参与; 但随着训练的进行,越来越多的类别也被包含。 这是因为: 1) 随着训练的进行,模型变得越来越准确; 2) 得益于 CDD 的乘法,类内的域差异变得越来越小,类间的域差异越来越大。
Class Sampling( C A S \rm CAS CAS)(类别关注的采样)
这是为了防止当采样的结果导致两个域的 m i n i b a t c h mini~batch mini batch 中无法同时含有某个类别的样本。
因此提出了一个类别关注的采样策略:司机选择集合 C T e \mathcal C_{T_e} CTe 的子集 C T e ′ \mathcal C'_{T_e} CTe′,然后从源域和目标域采集 C ‘ ’ T e \mathcal C‘’_{T_e} C‘’Te 中的类别的样本数据。
最后我们可以看一下具体的算法:

1 − 4 1-4 1−4 行是在当前最优的模型下完成了聚类;完了后,更新参数 θ \theta θ 才是重点——
1)重复多次迭代;
2)每次迭代中:① 随机获取获得 C T e ′ \mathcal C'_{T_e} CTe′ 作为类别子集,作类别关注的采样;② 计算 D ^ L c d d \hat \mathcal D_{\mathcal L}^{cdd} D^Lcdd;③ 从 S \mathcal S S 采样计算有监督的分类损失 l c r o s s e n t r o p y \mathcal l^{cross entropy} lcrossentropy;④ 反向传播;⑤ 更新网络参数 θ \theta θ。
4. 实验与结果
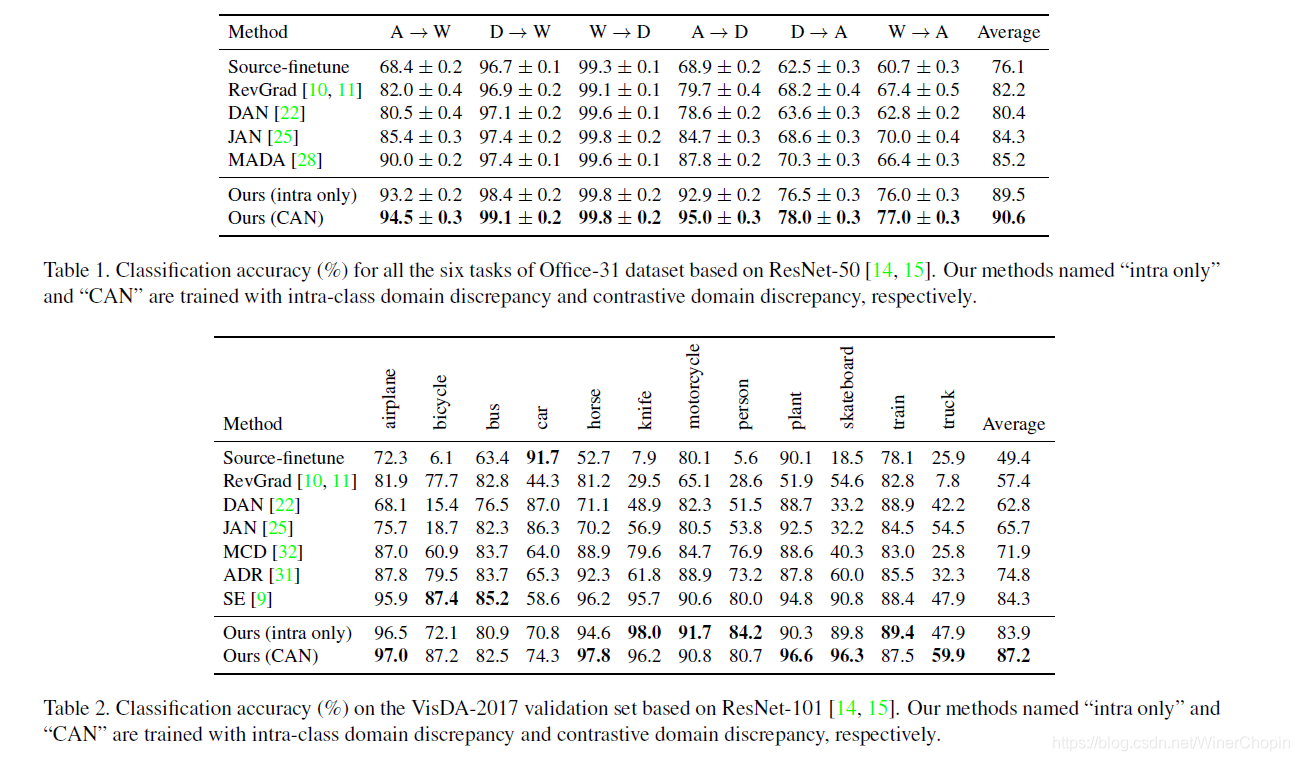
在数据集 o f f i c e − 31 office-31 office−31 和 V i s D A − 2017 \rm VisDA-2017 VisDA−2017 上做的实验,结果是吊打别人:
以及最后对目标域经过模型的特征作 t S N E \rm tSNE tSNE 可视化,结果证明上面的正则项确实可以实现类内相近类间相疏——

当然还需要证明提出的两个优化 C A N CAN CAN 的策略: A O \rm AO AO + C A S \rm CAS CAS 的作用(销蚀实验):

作者还尝试了使用伪标签去训练: p s e u d o 0 \rm pseudo_0 pseudo0 是指使用聚类后对目标域样本赋予的标签去训练模型(最小化在目标域上的分类loss)(没有交替优化,应该是在源域的分类模型已经训练好了); P s e u d o 1 \rm Pseudo_1 Pseudo1 是指交替优化,并用不断优化的源域模型去更新目标域样本的伪标签,用伪标签训练模型(这里的源域模型与目标与模型不知道是不是同一个,,)
