原文: https://zhuanlan.zhihu.com/p/48959800
本文介绍15年发表在NIPS上的一篇文章:Pointer Networks[1],以及后续应用了Pointer Networks的三篇文章:Get To The Point: Summarization with Pointer-Generator Networks[2]、Incorporating Copying Mechanism in Sequence-to-Sequence Learning [3]和Multi-Source Pointer Network for Product Title Summarization[4]。
一、从Sequence2Sequence说起
Sequence2Sequence(简称seq2seq)模型是RNN的一个重要的应用场景,顾名思义,它实现了把一个序列转换成另外一个序列的功能,并且不要求输入序列和输出序列等长。比较典型的如机器翻译,一个英语句子“Who are you”和它对应的中文句子“你是谁”是两个不同的序列,seq2seq模型要做的就是把这样的序列对应起来。
由于类似语言这样的序列都存在时序关系,而RNN天生便适合处理具有时序关系的序列,因此seq2seq模型往往使用RNN来构建,如LSTM和GRU。具体结构见Sequence to Sequence Learning with Neural Networks[5]这篇文章提供的模型结构图:
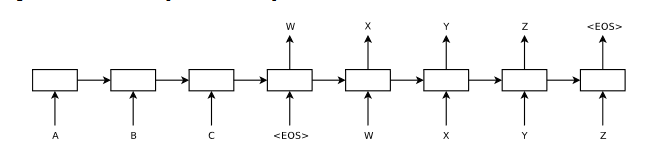
图1:Seq2seq模型结构
在这幅图中,模型把序列“ABC”转换成了序列“WXYZ”。分析其结构,我们可以把seq2seq模型分为encoder和decoder两个部分。encoder部分接收“ABC”作为输入,然后将这个序列转换成为一个中间向量C,向量C可以认为是对输入序列的一种理解和表示形式。然后decoder部分把中间向量C作为自己的输入,通过解码操作得到输出序列“WXYZ”。
后来,Attention Mechanism[6]的加入使得seq2seq模型的性能大幅提升,从而大放异彩。那么Attention Mechanism做了些什么事呢?一言以蔽之,Attention Mechanism的作用就是将encoder的隐状态按照一定权重加和之后拼接(或者直接加和)到decoder的隐状态上,以此作为额外信息,起到所谓“软对齐”的作用,并且提高了整个模型的预测准确度。简单举个例子,在机器翻译中一直存在对齐的问题,也就是说源语言的某个单词应该和目标语言的哪个单词对应,如“Who are you”对应“你是谁”,如果我们简单地按照顺序进行匹配的话会发现单词的语义并不对应,显然“who”不能被翻译为“你”。而Attention Mechanism非常好地解决了这个问题。如前所述,Attention Mechanism会给输入序列的每一个元素分配一个权重,如在预测“你”这个字的时候输入序列中的“you”这个词的权重最大,这样模型就知道“你”是和“you”对应的,从而实现了软对齐。
二、Pointer Networks
背景讲完,我们就可以正式进入Pointer Networks这部分了。为什么在讨论Pointer Networks之前要先说seq2seq以及Attention Mechanism呢,因为Pointer Networks正是通过对Attention Mechanism的简化而得到的。

作者开篇就提到,传统的seq2seq模型是无法解决输出序列的词汇表会随着输入序列长度的改变而改变的问题的,如寻找凸包等。因为对于这类问题,输出往往是输入集合的子集。基于这种特点,作者考虑能不能找到一种结构类似编程语言中的指针,每个指针对应输入序列的一个元素,从而我们可以直接操作输入序列而不需要特意设定输出词汇表。作者给出的答案是指针网络(Pointer Networks)。我们来看作者给出的一个例子:

图2:Pointer Networks实例:寻找凸包
这个图的例子是给定p1到p4四个二维点的坐标,要求找到一个凸包。显然答案是p1->p4->p2->p1。图a是传统seq2seq模型的做法,就是把四个点的坐标作为输入序列输入进去,然后提供一个词汇表:[start, 1, 2, 3, 4, end],最后依据词汇表预测出序列[start, 1, 4, 2, 1, end],缺点作者也提到过了,对于图a的传统seq2seq模型来说,它的输出词汇表已经限定,当输入序列的长度变化的时候(如变为10个点)它根本无法预测大于4的数字。图b是作者提出的Pointer Networks,它预测的时候每一步都找当前输入序列中权重最大的那个元素,而由于输出序列完全来自输入序列,它可以适应输入序列的长度变化。
那么Pointer Networks具体是怎样实现的呢?
我们首先来看传统注意力机制的公式:
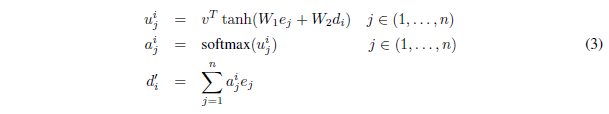
图3:传统注意力机制公式
其中是encoder的隐状态,而是decoder的隐状态,v,W1,W2都是可学习的参数,在得到之后对其执行softmax操作即得到。这里的就是分配给输入序列的权重,依据该权重求加权和,然后把得到的拼接(或者加和)到decoder的隐状态上,最后让decoder部分根据拼接后新的隐状态进行解码和预测。
根据传统的注意力机制,作者想到,所谓的正是针对输入序列的权重,完全可以把它拿出来作为指向输入序列的指针,在每次预测一个元素的时候找到输入序列中权重最大的那个元素不就好了嘛!于是作者就按照这个思路对传统注意力机制进行了修改和简化,公式变成了这个样子:
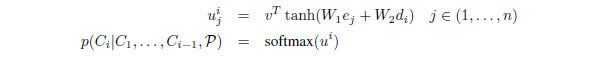
图4:Pointer Networks公式
第一个公式和之前没有区别,然后第二个公式则是说Pointer Networks直接将softmax之后得到的当成了输出,让承担指向输入序列特定元素的指针角色。
所以总结一下,传统的带有注意力机制的seq2seq模型的运行过程是这样的,先使用encoder部分对输入序列进行编码,然后对编码后的向量做attention,最后使用decoder部分对attention后的向量进行解码从而得到预测结果。但是作为Pointer Networks,得到预测结果的方式便是输出一个概率分布,也即所谓的指针。换句话说,传统带有注意力机制的seq2seq模型输出的是针对输出词汇表的一个概率分布,而Pointer Networks输出的则是针对输入文本序列的概率分布。
其实我们可以发现,因为输出元素来自输入元素的特点,Pointer Networks特别适合用来直接复制输入序列中的某些元素给输出序列。而事实证明,后来的许多文章也确实是以这种方式使用Pointer Networks的。
如果对Poiter Networks的实现感兴趣,可以参考这篇文章提供的若干实现:https://www.atyun.com/7771.html
三、Pointer Networks应用
由于本次介绍的文章中有两篇都是用于文本摘要领域的,我们先简单介绍一下文本摘要的背景知识。
3.1文本摘要背景介绍
所谓文本摘要,就是用一个较短的句子来总结一段文本的主要信息(Summarization is the task of condensing a piece of text to a shorter version that contains the main information from the original.[2])。而目前主流的文本摘要方法分为两个大的类别:Extractive和Abstractive。顾名思义,Extractive类方法就是从源文本中抽取出若干关键词来表达源文本的语义;而Abstractive类方法则是除了获取源文件中的一些词外还要生成一些新的词汇来辅助表达语义,类似人类做文本摘要的方式。
我们本次要介绍的两篇文本摘要领域的文章,其中Get To The Point: Summarization with Pointer-Generator Networks结合了Extractive和Abstractive两种方式来做文本摘要,而另一篇Multi-Source Pointer Network for Product Title Summarization则是偏重Extractive方向。
3.2使用Pointer-Generator网络的文本摘要方法
本部分介绍谷歌联合斯坦福于17年发表在ACL上的文章:Get To The Point: Summarization with Pointer-Generator Networks。
在这篇文章中,作者认为,用于文本摘要的seq2seq模型往往存在两大缺陷:1、模型容易不准确地再现事实细节,也就是说模型生成的摘要不准确;2、往往会重复,也就是会重复生成一些词或者句子。而针对这两种缺陷,作者分别使用Pointer Networks和Coverage技术来解决。
而最终的效果,作者提供了一张图来做对比:

图5:方法效果对比
在这张图中,基础的seq2seq模型的预测结果存在许多谬误的句子,同时如nigeria这样的单词反复出现(红色部分)。这也就印证了作者提出的基础seq2seq在文本摘要时存在的问题;Pointer-Generator模型,也就是在seq2seq基础上加上Pointer Networks的模型基本可以做到不出现事实性的错误,但是重复预测句子的问题仍然存在(绿色部分);最后,在Pointer-Generator模型上增加Coverage机制,可以看出,这次模型预测出的摘要不仅做到了事实正确,同时避免了重复某些句子的问题(摘要结果来自原文中的蓝色部分)。
那么,Pointer-Generator模型以及变体Pointer-Generator+Coverage模型是怎么做的呢,我们具体来看。
首先,我们来看看传统seq2seq模型图与Pointer-Generator模型图之间有什么区别:
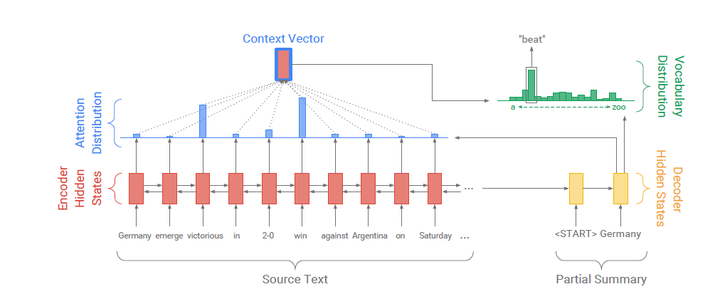
图6:传统seq2seq模型结构图
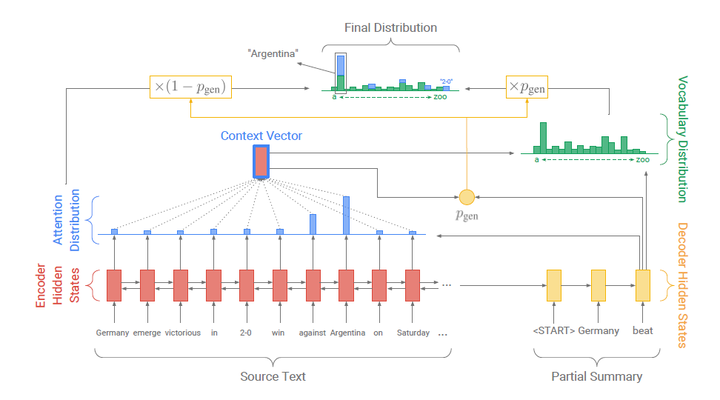
图7:Pointer-Generator模型结构图
可以很明显地看到,传统seq2seq模型正如我们开始描述的那样,通过Attention Mechanism将encoder的隐状态和decoder的隐状态结合成一个中间向量C,然后使用decoder解码并预测,最后经由softmax层得到了针对词汇表的概率分布,从中选取概率最高的作为当前预测结果。
而Pointer-Generator模型除了上述过程,还加入了Pointer Networks的部分。作者对Pointer Networks应用的思想非常直观,就是用它来复制源文本中的单词。简单来说,在每一次预测的时候,通过传统seq2seq模型的预测(即softmax层的结果)可以得到针对词汇表的概率分布(图7中绿色柱形图),然后通过Pointer Networks可以得到针对输入序列的概率分布(图7中蓝色柱形图),对二者做并集就可以得到结合了输入文本中词汇和预测词汇表的一个概率分布(最终结果的柱形图中的“2-0”这个词不在预测词汇表中,它来自输入文本),这样一来模型就有可能直接从输入文本中复制一些词到输出结果中。当然,直接这样操作未必会有好的结果,因此作者又加入了一个Pgen来作为软选择的概率。Pgen的作用可以这样理解:决定当前预测是直接从源文本中复制一个词过来还是从词汇表中生成一个词出来。
结合公式,Pgen是这样生成的:
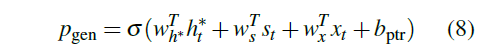
图8:Pgen计算公式
和Attention Mechanism中的的计算方式极其相似对吧?得到Pgen之后,我们就可以这样计算最终预测出一个词的概率:

图9:预测公式
其中Pvocab(w)就是传统seq2seq模型通过softmax层计算出来的当前词的概率,而则是使用Pointer Networks计算出的源文本中的该词的概率,最后通过Pgen这个软选择概率结合在一起就得到了最终预测结果。
通过以上过程,作者得到了Pointer-Generator模型,解决了摘要中存在事实性错误的问题。然后作者又向前走了一步,就是加入了Coverage机制来解决重复问题。
Coverage机制的思想同样简单而直接:每次预测的时候我们都会得到概率分布,这个就反映了模型对源文本各个元素的注意程度(概率越高的部分被认为得到越多的注意力),如果模型在预测时总是注意相同的部分,那么就很有可能会预测出相同的单词,因此为了防止这种情况发生,我们就强迫模型多去关注之前没被注意过的角落。公式如下:

图10:coverage vector计算公式
这个公式的意思是说,当预测时刻t的单词时,我们就来看看在过往的t-1个时刻中,源文本被关注程度的分布情况如何,接下来我们用一些方法来做出相应调整。调整的方法是这样的:
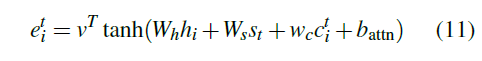
图11:调整公式
这个公式其实是对传统Attention公式(见图3)的调整,也就是在结合encoder隐状态和decoder隐状态的基础上又加入了coverage vector的信息,这样就把coverage信息结合了进去。
最后,为了鼓励多把注意力转向之前不被注意的角落的行为,作者在原本的loss function中加入了针对Coverage机制的loss项:
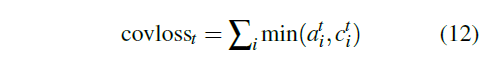
图12:Coverage损失公式
至此,一个完整的用于克服文章开头提出的两个问题的Pointer-Generator+Coverage模型就完成了。
通过这篇文章我们可以看出,虽然很多想法非常简单而直观,但是把它们放在合适的位置上就可以让它们发挥不简单的力量。
3.3赋予seq2seq模型复制能力——CopyNet
本部分介绍华为和港大合作的一篇文章:Incorporating Copying Mechanism in Sequence-to-Sequence Learning,并以此作为和3.2部分介绍的文章的对照(因为那篇文章的作者提到,他们的工作和本文的CopyNet比较相似)。
本文开篇,作者就提出他们的目标是解决seq2seq模型的复制问题,并且提供了一个例子:

图13:对话实例
在这个例子中,我们要对用户提出的问题做出回答,显然,蓝色部分根本不需要理解语义,直接复制即可。针对这种情形,作者希望能赋予seq2seq复制的能力。
解决方案其实和前一篇ACL17的文章有些类似。那么为什么先介绍17年的文章,后介绍16年的呢?这是因为ACL17的文章相对较为通俗易懂,我们在读过它后再来理解ACL16的文章会更容易。
模型包含两个部分:Generation-Mode用来根据词汇表生成词汇,然后Copy-Mode用来直接复制输入序列中的一些词(是不是觉得有些眼熟)。看一下模型结构图:
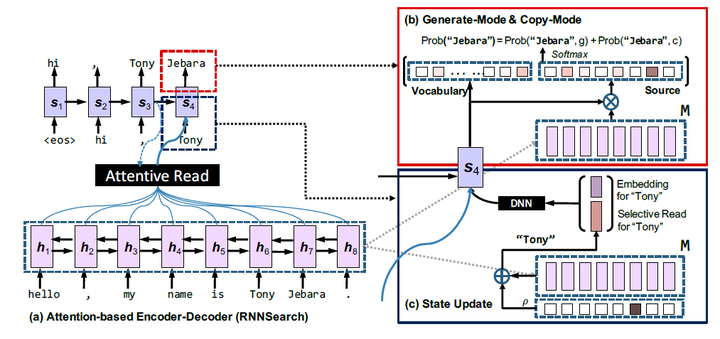
图14:CopyNet结构图
在红色矩形圈出的部分中,左边正是在词汇表上的概率分布,而右边则是在输入序列上的概率分布,将这两部分的概率进行加和即得到最终的预测结果。公式如下:
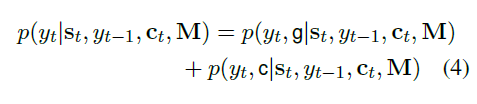
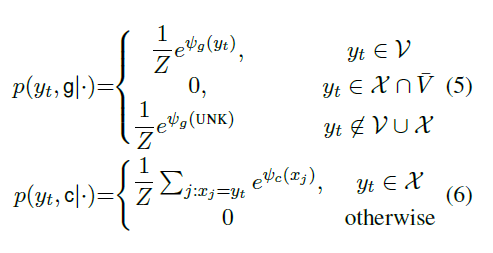
图15:CopyNet预测公式
是不是和之前的文章的公式非常相似?不同的是ACL17的文章还计算了一个软选择的概率Pgen用来结合生成概率和复制概率,而在这里则是直接加和。
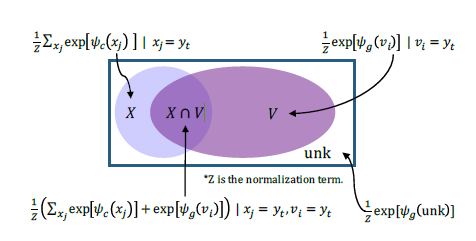
图16:词汇分布图
为了更好地理解,作者绘制了一幅词汇分布图。图中X部分是输入序列的词汇集合,而V部分代表输出词汇集合,当然,通常情况下两个集合都存在交集,而在X和V并集之外的部分就是未知词汇:UNK。所以我们用一句话来解释上面的公式:当某个词是输入序列独有的则该词的生成概率为0,复制概率不变;若某个词是输出词汇表独有的则该词的复制概率为0,而生成概率不变;若某个词既存在于输入序列又存在于输出词汇表则生成概率和复制概率都不变。最后,将生成概率和复制概率加和得到最终的概率。
那么生成概率和复制概率具体怎么计算呢?来看公式:

图16:Generation-Mode计算公式
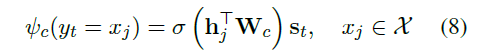
图17:Copy-Mode计算公式
看起来有点复杂,但对比一下,其实形式和attention计算公式非常相似。
最后,通过一个实例看到模型的能力还是很强的:
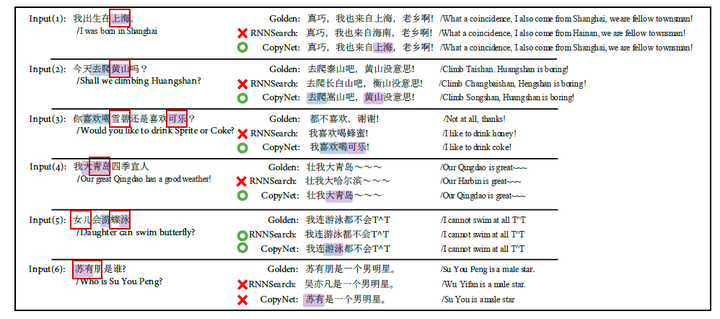
图18:CopyNet应用实例
3.4使用多来源Pointer Network的产品标题摘要方法
本部分介绍新鲜出炉的阿里团队18年发表在CIKM上的文章:Multi-Source Pointer Network for Product Title Summarization。
这篇文章描述了这样的一个场景:用户在移动设备上使用电子商务软件进行购物的时候,由于移动设备屏幕的限制,往往在列表页无法看到商品的完整名称,为了弄清楚这商品具体是什么不得不点开商品的详细信息页(即使用户还没有决定购买该商品),而这会有损用户体验(如图19)。那么为了让用户在列表页就准确知道该商品的主要信息,就有必要对较长的商品标题做一个摘要,用短短几个词准确表达商品信息。
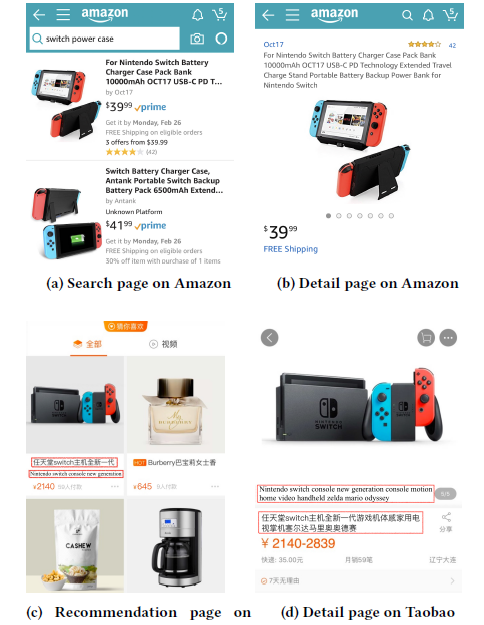
图19:列表页与详情页的商品标题
作者认为,商品标题摘要这个特殊问题天然存在对模型的两个限制:(1)摘要中不能引入不相关信息;(2)摘要中必须保留源文本的关键信息(如品牌名和商品名)。作者提出的解决办法是Multi-Source Pointer Network。
对于第一点限制,作者使用Pointer Networks来直接从源标题中提取词汇,保证不会引入不相关信息,针对第二点,作者提出了knowledge encoder技术来满足要求。
模型结构如下:
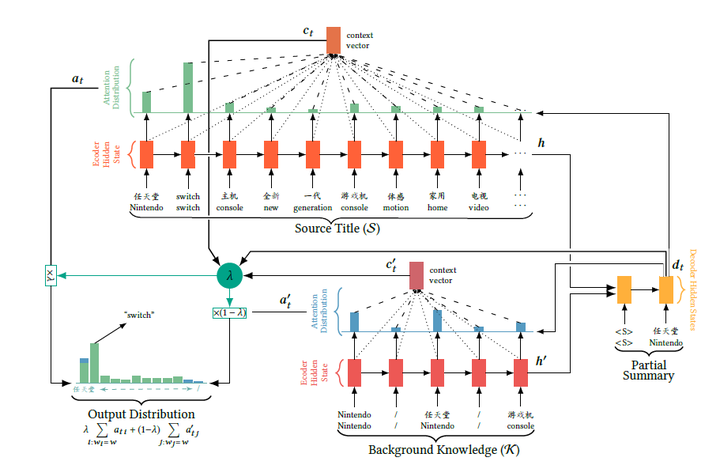
图20:MS-Pointer模型结构图
可以看出,在这个模型中存在两个输入,即原本的商品标题以及额外提供的“knowledge”,在这里作者提供的“knowledge”主要是商品名称和品牌名。source encoder从商品标题中抽取单词信息(绿色概率分布),而knowledge encoder从“knowledge”序列中抽取信息(蓝色概率分布),将二者结合得到最终的输出。
所以用一句话来形容MS-Pointer的功能就是:从两个信息来源:原始商品标题和知识信息中抽取信息,然后将二者进行综合得到最后的结果。
然后我们通过公式来看看具体的计算过程:
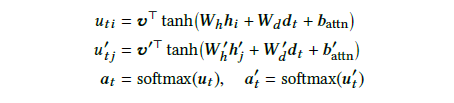
图21:公式1
这三个公式类似之前提到的传统seq2seq模型中的attention过程,其中hi是source encoder的隐状态,dt是decoder的隐状态,而hj’则是knowledge encoder的隐状态,最后分别得到针对商品标题和knowledge的概率分布:和。
然后我们对二者进行一个综合,从而得到最终的结果:
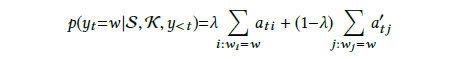
图22:公式2
可以看到,综合的方式是引入了概率值。这样就得到了当前输出。那么又是怎么得到的呢?如下图:
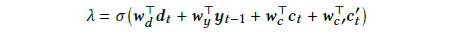
图23:公式3
这个公式有点类似我们之前讨论的Get To The Point: Summarization with Pointer-Generator Networks计算决定复制还是生成的概率Pgen的计算方式。所不同的是,这里不仅结合了当前decoder隐状态和上一时刻的输出,另外还结合了两个encoder提供的向量和。而同样的,和就是两个encoder经过编码之后得到的中间向量:
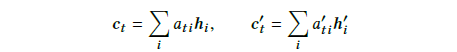
图24:公式4
当然,最后的实验也验证了作者提出的方法确实在电子商务的商品标题摘要任务上取得了非常好的效果。
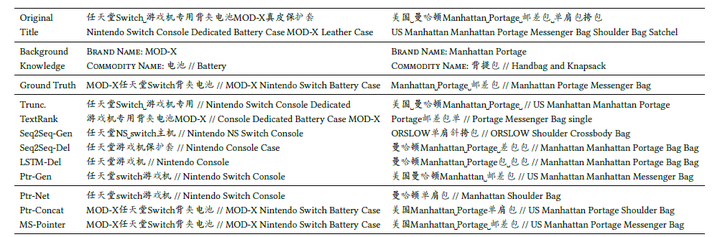
图25:实验结果
四、总结
读过三篇关于Pointer Networks的文章后,相信大家会对Pointer Networks有一个比较直观的感受。笔者的感受是,由于Pointer Networks天生具备输出元素来自输入元素这样的特点,于是它非常适合用来实现“复制”这个功能。而从本次介绍的两篇Pointer Networks应用文章来看,很多研究者也确实把它用于复制源文本中的一些词汇。另外由于摘要这个任务所需的词汇较多,也非常适合使用复制的方法来复制一些词。这就造成了目前Pointer Networks成为文本摘要方法中的利器的局面。那么未来Pointer Networks的应用会走向什么方向呢?当然也会和“复制”这个关键词分不开。正如Multi-Source Pointer Network for Product Title Summarization的作者提到的,Pointer Networks其实特别适合用于解决OOV(out of vocabulary)问题,或许它可以在NLP的其他任务中被用来解决OOV问题。至于更多创新应用,我们拭目以待。
五、参考文献
[1] Vinyals O, Fortunato M, Jaitly N. Pointer Networks[J]. Computer Science, 2015, 28.
[2] See A, Liu P J, Manning C D. Get To The Point: Summarization with Pointer-Generator Networks[J]. 2017:1073-1083.
[3] Gu J, Lu Z, Li H, et al. Incorporating Copying Mechanism in Sequence-to-Sequence Learning[J]. 2016:1631-1640.
[4] Sun F, Jiang P, Sun H, et al. Multi-Source Pointer Network for Product Title Summarization[J]. 2018.
[5] Sutskever I, Vinyals O, Le Q V. Sequence to Sequence Learning with Neural Networks[J]. 2014, 4:3104-3112.
[6] Bahdanau D, Cho K, Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate[J]. Computer Science, 2014.