本文的方法第一步是对矩阵做定点分解,第二步是做全精度的权值的恢复,第三步是权值balancing,最后一步是fine-tuning。

同样是一个8*8的矩阵,把权值分解成两个矩阵的乘积形式,保证分解后的两个矩阵是一个定点表示,分解出来的左边矩阵,是一个ternary,右边是ternary的一个表示,中间有一个全精度的,浮点的,对称的矩阵,相当于一个尺度因子。

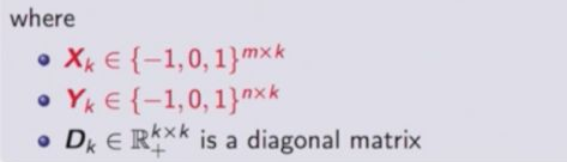
一个直观的解释,如果不考虑正负,他会选择某些行某些列,根据这些行和列选出来的位置用同一个权值表示,对选出来的行和列做一个重排,这些行业这些例都是一个值,另一行另一列是另一个值。
具体到神经网络,就是给定一个权值矩阵,做分解,保证x和y是ternay的形式。
有了这样一种分解方式以后,
后面要做一个fine tuning,在做fine tuning的阶段,因为做了这样的矩阵分解以后,全精度的权值就消失了,在fine tuning的时候肯定需要全精度的权值,来做误差的累积。所以需要把权值恢复出来。
所以本文作者提出了一种方法恢复全精度的权值,思路是把问题转化成优化问题,就是还是去拟合原始的全精度的w,

另一个方法就是对权值做均衡,
比如把w分解成p和q,这样一层网络会变成两层,在反向传播的时候,如q乘一个系数,比如乘上10,p除10,计算出来的q的梯度,是缩小了10倍,p的梯度增加了10倍,所以scale在神经网络训练中是一个非常重要的
x乘一个系数,y乘一个系数,d乘一个系数,来评估它们之间的scale
通过实验证明不做权值均衡,三层网络的梯度差别很大,做了权值均衡以后,三层网络的梯度都在0.1范围内。
ref
https://zhuanlan.zhihu.com/p/70427660
