本文将深度学习方法引入到单图像的超分辨中。同时表明传统的用稀疏编码(sparse-coding)实现超分辨的方式可以视作是深度卷积神经网络。但是不同于传统的将每个组分单独处理的方式,本文提出的方法将所有的层进行联合优化。
state-of-the-art方法大多数都是基于样例的:要么是开发图像内部的相似性,要么是从外部的高-低分辨率图像对中学习映射函数。基于外部图像学习的方式常常需要充足的样本,但也会面临有效、密集地对数据建模的困难。
在基于外部样本的图像超分辨方法中,sparse-coding是具有代表性的一种。其步骤为:
①从源图像中密集地提取出交叠的图像块并且进行预处理;
②用低分辨率的字典对图像块进行编码;
③将稀疏系数被传递到高分辨的字典中来重建高分辨图像块,再将这些图像块进行聚合产生输出图像。
先前的超分辨方法尤其注重于学习和优化字典或者构建字典的方法,但在同一的优化框架下,上述的其他步骤却很少被优化或者是被考虑到。而本文展示了上述sparse-coding的这些步骤是等同于一个深度卷积神经网络的。与这些已有的基于外部样本的图像超分辨方法不同的是,本文提出的SRCNN是从低分辨图像到高分辨图像的端到端映射,字典的学习是通过隐藏层隐式实现的,图像块的提取和聚合是由卷积层完成的,并且整个过程都是通过学习实现的,几乎不需要预处理和后续处理。
本文的三个主要贡献为:
①提出了将卷积神经网络用于图像超分辨。网络直接学习了低分辨到高分辨图像的端到端映射,并且在优化过程中几乎不需要预处理或者后续处理;
②建立了基于深度学习的超分辨方法和传统的基于系数编码的方法。这种关系为设计网络结构提供了一种指导;
③证明了深度学习在超分辨这一经典计算机视觉问题上是有用的,并且能够达到很好的质量和速度。
在具体实现上,考虑一张低分辨率的图像,首先将其用双三次插值法提升到目标大小,记作图像Y,这是整个过程中的唯一预处理。目标是将Y恢复为F(Y),使之尽可能与ground truth的高分辨图像X相似,因此我们希望学习映射F,其包含三个操作,而这些操作组成了一个卷积神经网络。
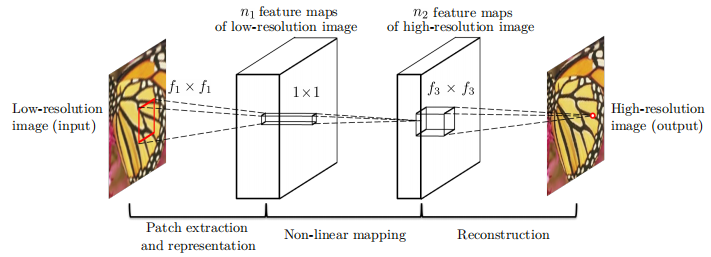
1、Patch extraction and representations(块提取与表示):从低分辨图像Y中提取图像块并表示为高维向量,这些向量组成了一系列等数量的特征映射,第一层表示为F1,将每个图像块提取出n1维特征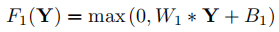
2、Non-linear mapping(非线性映射):将n1维向量映射为n2维向量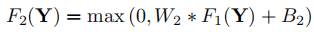
3、Reconstruction(重建):传统方法中是将交叠图像块进行平均来重建整个图像,这种平均可以视作在一系列特征映射上的滤波器,因此可以用卷积层来产生最终的结果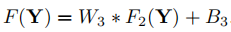
与sparse-coding的联系:
①从输入图像中提取f1*f1大小的低分辨图像块,减去均值并投射到大小为n1的字典 → 用n1个f1*f1的线性滤波器处理输入图像
②稀疏编码后的n2个系数被投射到高分辨字典 → n2个线性卷积
整个网络的损失函数用MSE来衡量,因此偏好高的PSNR。在与其他的SR方法相比时,SRCNN效果很好。另外,如果增加训练集的数量、增大网络的规模、增大滤波器的大小,对于网络的性能都会有提升。
总的来说,传统的基于sparse-coding的图像超分辨方法能够用深度卷积神经网络来再现,这种轻量级的结构的效果相比state-of-the-art都要好,并且由于其简单性和鲁棒性,还能被用于图像去模糊或是同时实现SR和去噪等其他低级的视觉问题。