来自微软和中国科技大学研究学者的论文《Deep High-Resolution Representation Learning for Human Pose Estimation》和相应代码已经公布。
该文为第一作者Ke Sun在微软亚洲研究院实习期间发明的算法。
作者观察到,现有姿态估计算法中往往网络会有先降低分辨率再恢复高分辨率的过程,比如下面的几种典型网络。
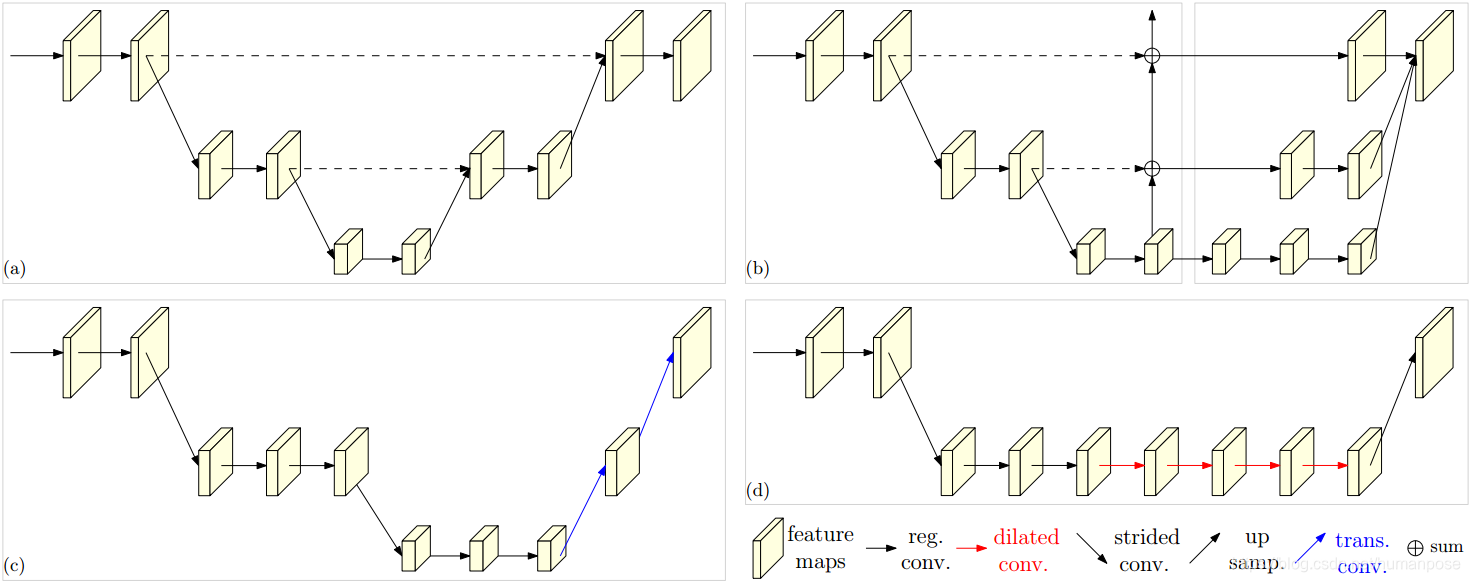
(a) Hourglass (b) Cascaded pyramid networks(c)Simple Baseline (d) Deepercut
作者希望不要有这个分辨率恢复的过程,在网络各个阶段都存在高分辨率特征图。
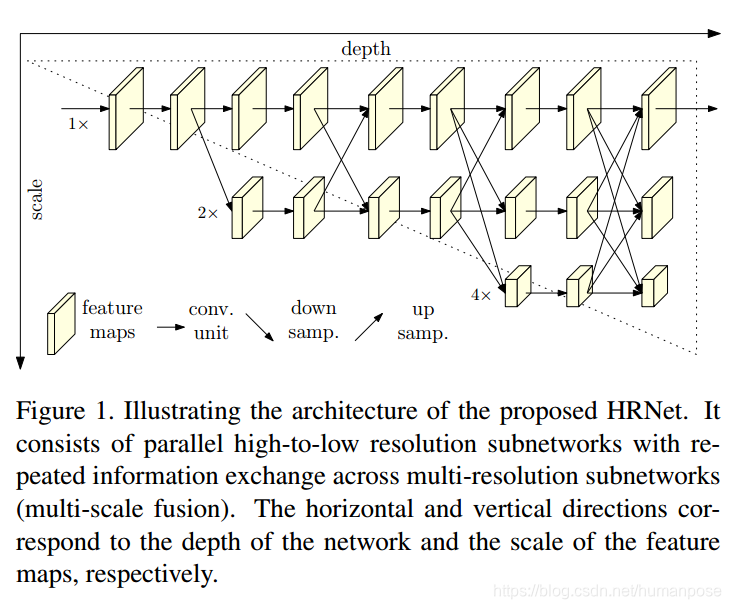
在上图中网络向右侧方向,深度不断加深,网络向下方向,特征图被下采样分辨率越小,相同深度高分辨率和低分辨率特征图在中间有互相融合的过程。
作者描述这种结构为不同分辨率子网络并行前进。
这么做有什么好处?
作者认为:
1)一直维护了高分辨率特征图,不需要恢复分辨率。
2)多次重复融合特征的多分辨率表示。
与目前的state-of-the-art比较,取得了各个指标的最高值。相同分辨率的输入图像,与之前的最好算法相比增长了3个百分点!
在COCO test-dev 数据集上和 MPII test 数据集上,同样取得了很好的结果!