这篇文章提出了一种Co-Segmentation Inspired Attention模块,用于专注于视频中的人像主体,忽略背景信息的干扰。本质上这是一篇将non-local模块,或是temporal self-attention机制应用于video-reid的文章,但相较于其他应用non-local在video-reid的文章来说,它的分析较为详尽。
Motivation
Video Re-id需要专注于图像主体,即人体及其背包等关联物,而忽略背景信息的干扰。达成这一目的目前有多种方法,人像姿态估计、分割。但这两种方法代价过高,且会只捕捉人体部分,而忽略人体关联物,如包等。

另一种方法是采用attention来关注画面主体,但fram-wise的attention没有充分利用丰富的时空信息,所以这个attention是次优的。
因此作者提出借鉴co-segmentation的思路,提取帧间共享attention。

Co-segmentation

Obeject co-segmentation 就是将不同图片中的公共对象提取出来,根据这些公共对象相似的结构和特征。
Co-segmentation activation module (COSAM)
Spatial Attention

如图,最左边是每一帧的特征,对于某一帧的某个像素点,计算其与所有其他帧的所有像素点的相关性,然后相加得出该像素点的attention。该点的特征在越多的位置出现,该点越有可能获得高attenion。
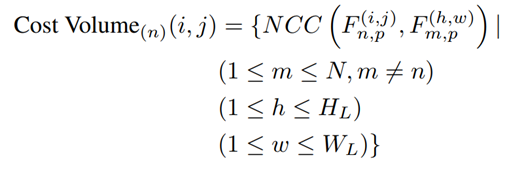
NCC是一种关联强度计算函数,其主要特点是进行了normalize:
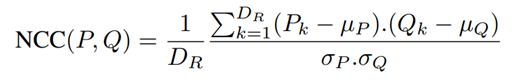
Module

整个模块的设计上,在进行像素关联性计算前进行了降维,后面还跟了一个channel-attention。

这个模块可以被插入在整个pipeline的feature extract阶段的各个block之间。
Experiment

插在后面会有一个明显的提升。

对各种time aggregation方法都有一个提升。

总体上能提一个点的样子。
Discussion
这篇文章看完之后觉得就是non-local [1] 用在了video-reid上,相似的工作我看到的还有两篇 [2, 3]。不过这篇文章确实对这个non-local机制( temporal self-attention)为什么对video-reid起作用的原因分析的比较透彻。其他文章基本沿用了non-local的说法,认为是扩大了感受野。扩大了感受野这个说法错是没错…但太笼统了。
另一个问题是,这篇文章说的其实是co-segmentation inspired attention,而不是co-segmentation。因为你如果按照co-segmentation去想的话,一段视频里面其实背景没怎么变化,直接算关联度的话,这是不会使得background被忽略的。所以这其实是在帧间attention上施加了关联度计算,所以那个“降维层”很关键,它产生的特征不只是降维特征,而是attention信息,没有这一层我觉得这个moduel会挂。
最后,这种temporal self attention是给整个video里经常出现的部分一个更强的attention,从而获得性能的提升。那么在有的任务中,某几帧的作用特别强烈(比如视频分类等,出现某一帧了就完成了分类),那么这种机制应该是无效的甚至是有害的。(就我目前和师兄弟交流的情况来说,确实有听闻non-local在video classification上失效的实践。)
Reference
[1] Wang, X., & Girshick, R. (2018). Non-local Neural Networks. Conference on Computer Vision and Pattern Recognition (CVPR), 7794–7803.
[2] Li, J., Wang, J., Tian, Q., Gao, W., & Zhang, S. (2019). Global-Local Temporal Representations For Video Person Re-Identification. The IEEE International Conference on Computer Vision (ICCV).
[3] Liu, C., Wu, C., Wang, Y. F., & Chien, S. (2019). Spatially and Temporally Efficient Non-local Attention Network for Video-based Person Re-Identificatio. British Machine Vision Conference, 1–13.
