行人重识别之语义分割网络
Densely Semantically Aligned Person Re-Identification
原文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Zhang_Densely_Semantically_Aligned_Person_Re-Identification_CVPR_2019_paper.pdf
本文解决的是行人图像不对准的问题,如下图。其实,解决不对准问题,也就同时解决了摄像头视角、姿态变化、遮挡、背景不同、行人检测效果差等问题。所以解决该问题对于行人重识别十分重要。

- 语义分割
作者使用了DensePose: Dense human pose estimation in the wild中的网络(在DensePose-COCO上训练,没有专门的行人重识别数据库训练该网络,也是制约该方法的一个因素)将身体分为了24个部分,映射到uv空间,不仅实现了各个部位的语义对应,甚至实现了像素级别的对应。效果如下图。
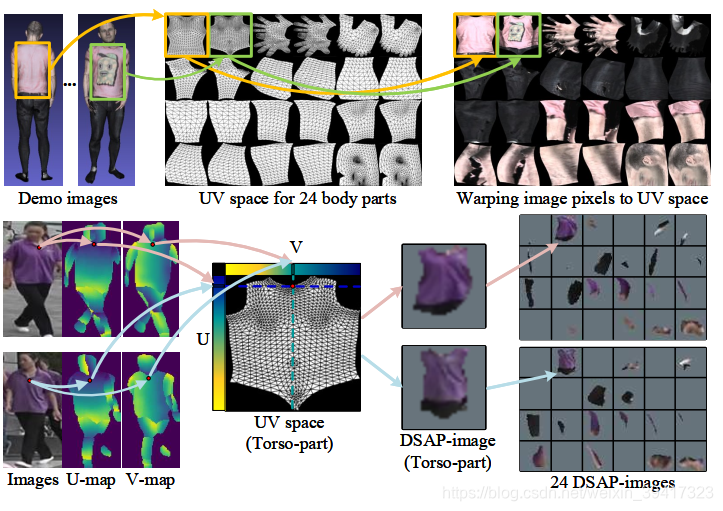
因为reid中的图像是二维的,所以24个部分会缺失一半左右。 - 整体框架
整体框架如下图:上面的网络提取整个图像的特征,下面的网络提取上述语义分割图像的特征。具体细节可以参考论文。主要说一些重要的思想。
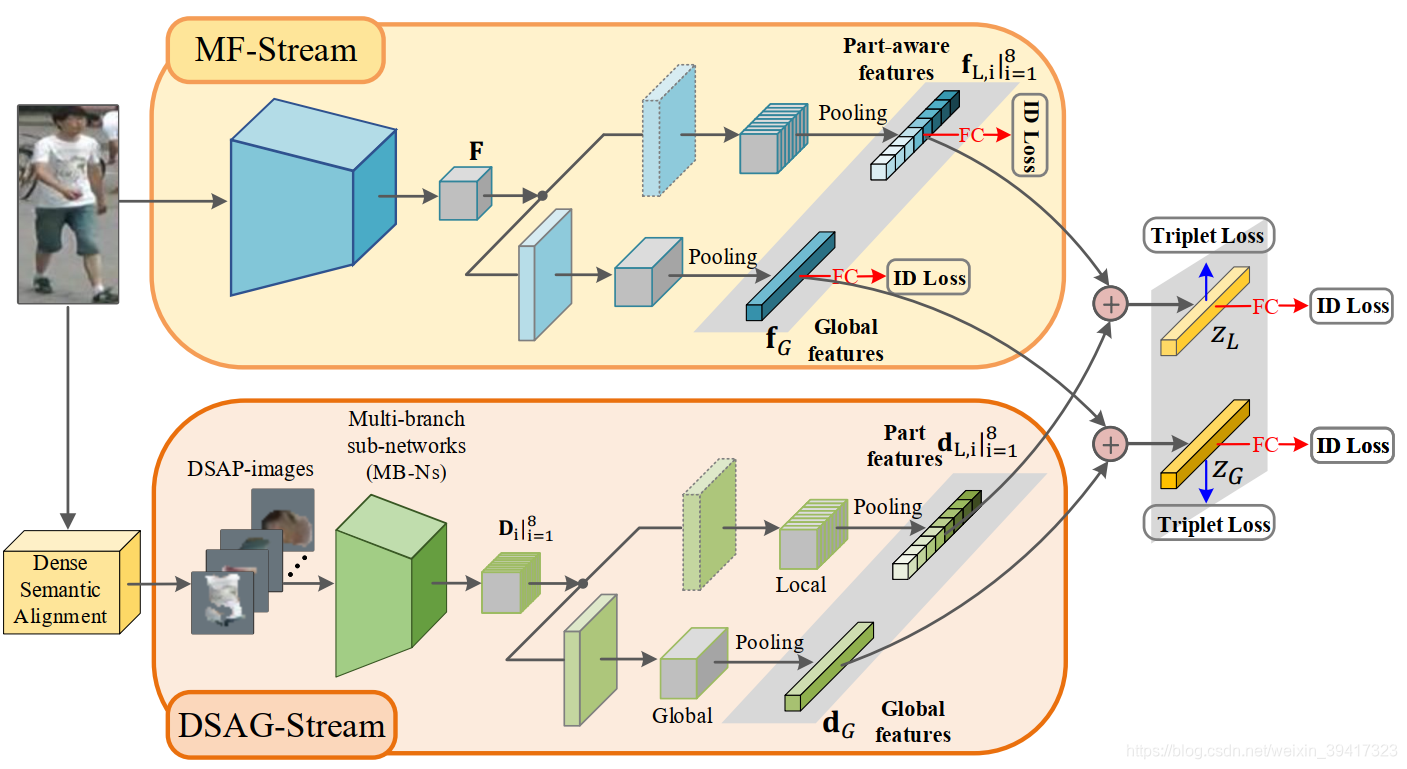
1.因为语义分割效果不好,所以只在训练中使用,将其提取的特征与上半部分的特征结合,起到监督的作用。同时也节约了测试过程的计算资源。
2.行人重识别有一个趋势:一个主干网络识别,一个小网络辅助。小网络是为了解决各个论文提出的问题。
3.交叉熵加三元组的损失函数似乎成为了reid的基础标配。
4 网络的联合训练通常效果会更好。 - 一些细节
1.如下图,24个部分经过了两层级联,最后融合成了8个部分。所谓大道至简,这种做法一定尝试了很多种可能,这也是此方法的局限性。

2.特征向量直接相加比先连接再经过全连接层效果更好,而且好很多。不知这可不可以算作一个通用结论。
总结:论文看的越来越多,感觉研究的套路性确实挺强的,这当然不是否定别人的工作。只是希望我们可以利用这些套路多做出一些东西,同时也不拘泥于套路。
完
欢迎讨论 欢迎吐槽
