学习笔记:cs224n6
学习视频:cs224n6
学习课件:cs224n6
这节课,又听的云里雾里的,感觉真的很多的东西一遍真的听不懂,听不明白。所以要多听几遍,多去思考。
第一个问题:常用的描述语法的二种观点。
1)短语结构文法,用英语来表述:Constituency=phrase structure grammar=context free grammers(CFGs)
这种表达语法的方法用固定数量的规则来分解句子为短语和单词,分解短语为更短的短语或者单词。
这种方法用大白话来表示,就是把一个句子不断的进行划分为短语和单词,然后不断划分的过程。
这里涉及一个概念:上下文无关文法规则。下面的链接简单的描述了上下文无关文法规则。
http://www.cnblogs.com/HUGHUG/p/9213481.html
这些类似的研究,做的是乔姆斯基谱系。

2) 依存结构,(dependency structure)用单词之间的依存关系来表达语法。具体来说,一个单词用于修饰另一个单词,那么这个单词依赖于另一个单词。
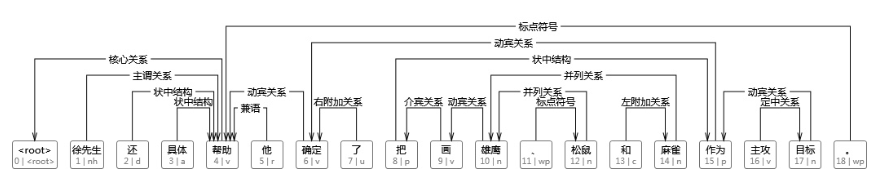
这种方式用大白话来表示,就是描述单词之间的关系,来寻找句子中二二单词之间的关系,存在关系,就存在依赖,不存在关系,就没有箭头。
对于语义模糊的情况,可以优先考虑采用依存结构来解决。

比如在这个有歧义的分析中,我们理所当然认为是第二者,研究太空中的鲸鱼,但真实的新闻报道确是第一种的理解,是通过卫星追踪技术来研究。
我们可以通过修饰关系来解释有歧义的句子,然后消除歧义。
在这个部分,有一个新的名词:Catanlan number。卡特兰数,又称为了卡塔兰数,是一个比较多见且高深的数列。
简单的了解一下卡特兰数的性质和应用。https://blog.csdn.net/wu_tongtong/article/details/78161211
百度百科其实也写的挺不错的,一些常见的比如出栈次序,括号化,凸多边三角划分,给定节点组成的二叉搜索树个数等。
https://baike.baidu.com/item/%E5%8D%A1%E7%89%B9%E5%85%B0%E6%95%B0/6125746?fr=aladdin
第二个问题:完整的语言学以树库(treebank)的形式标注数据
将句子的句法结构描述为依存关系图,然后把它叫做树库(treebank)。标注数据库,来制作语料库。

上图就是一个标记好的树库,对于树库而言,是可以重复利用的,可以说是一个基本的框架,而且可以相比于规则的死板而言,树库可以作为评测的标杆,得到越来越多的引用。
第三个问题:依存语法和依存结构
二种语言学的表示中,现在我们常用的是后者 ,也就是常用的是依存句法的表述,而不是短语结构的表示。
对于没有加上标记的依存句法树,跟上下文无关语法树是类似的,其实也就是短语结构树的一种。

对于加上了标记的依存句法树,情况大大不同。

上面箭头上的标签就是依存关系的分类的名称。
对于依存句法的历史:最古老的从印度语言学家Panini对于语义,句法和形态依存的分类研究开始出现,然后阿拉伯的语言学家研究的也涉及到了依存关系文法之说,一直不断的进行发展,依存句法支付之父的研究表明在次、词序比较自由的语言中比较流行。
第四个问题:如何进行依存分析。
在进行依存句法分析的时候,遵循的一些原则,一般来说,相邻的词语之间存在依存关系,中间是标点二边的词语不太可能存在依存,一个词语最多有几个依赖者,对于二个相近的词汇,不可能存在依存等。
在进行依存句法分析的时候,有几个约束条件:root只能被一个词依赖,也就是存在一个中心词,这个root是一个虚拟的项;在依存弧中,不可能存在环。
在依存句法的分析中,大部分语言是相互嵌套,也就是不存在交叉的情况,但少部分语言也是存在交叉的情况。这个性质叫做投影性,也就是没有交叉的情况,是具有投影性的,成为投影依存树。(从依存句法树中,不能恢复到原来的句子的顺序,句子顺序是丢失了的。)
常见的依存句法分析的方法有:
1)动态编程(Dynamic programming)
2)图算法(Grapg algorithms)
3)约束补偿(Constraint Statisfaction)
4)基于贪心决策动作拼装句法树(Transition-based parsing/ deterministic dependency parsing)
第四种,是目前的主流方法,而且方法的时间复杂度为O(N)线性关系。
第五个问题:如何进行基于贪心决策动作拼接句法树
1) 基于弧标准过度的依存分析(Arc-standard transition)
这里有一个详细的讲解:http://www.hankcs.com/nlp/parsing/neural-network-based-dependency-parser.html/2#h2-6

这种分析中,存在三个操作,第一个操作是平移,第二个操作是左移,第三个操作是右移。涉及到了三个容器,第一个容器是一个栈,用来存储已经处理过的句法子树的根节点, 第二个容器是一个队列,用于存储序列,第三个容器是存储依存弧,左依存弧和右依存弧。
MaltPraser是一个具体的依存语法解析的实现。http://www.maltparser.org/intro.html

2)在传统的依存分析中,特征的表示
采用了一种稀疏的特征表示。就是一种指示的特征,每一位来表示每种特征是否出现,由栈和队列中的单词,词性,依存标签的组合的特征函数,是一个超长的稀疏的01向量。
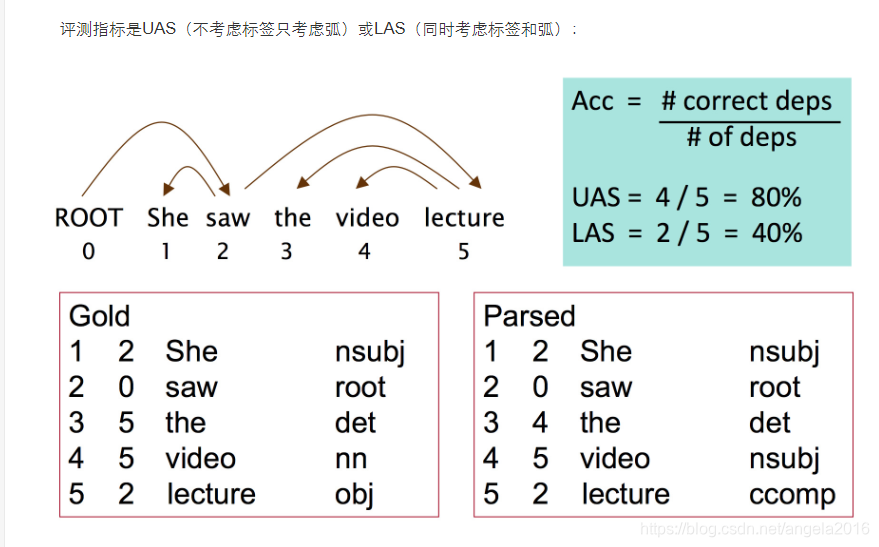
3)依存分析中的效果评估。
4) 采用神经网络句法分析器
在传统的特征表征的依存句法分析中,特征稀疏,计算代价大,主要花费在了计算特征,查询特征的权重之上了。
现在通过利用神经网络句法分析器来进行处理,将其视为了一个分类的问题。我们分类的目标是二个词之间是否存在弧,以及是否要进行平移的关系(也就是不存在依赖弧)。
