pdf
本节课是对自然语言处理的定义介绍和应用介绍,还顺带说了NLP的难点;
传统的机器学习技术,需要人为地去做特征工程,将这些的特征喂给机器学习算法;然后机器学习算法去训练,来找到最拟合训练数据+正则化损失最小的权重 。教授说,我们的传统机器学习技术,其实主要是在做数值优化 的问题。
人为设计的特征具有如下缺点:
over-specified,过于具体的
incomplete. 不够完整的
take a long time to design and validate 需要长时间的设计和验证
深度学习是机器学习的一个子域。它使用算法,让机器能够自动地学习特征;我们只需要将最原生的特征喂给深度学习算法,它就可以自己学习特征,自己分类,表现得很好。
经常用到的英文术语:
linguistics 语言学
推荐的阅读文献:
Deep Learning in Neural Networks: An Overview
2018-pdf 2017-pdf
webster dictionary 韦氏字典
扫描二维码关注公众号,回复:
3532815 查看本文章
在语言学中,词的含义就是通过这个词所传达的具体的指代,或人的想法和意志。可以用如下公式表示:
s
i
g
n
i
f
i
e
r
(
s
y
m
b
o
l
)
⟺
s
i
g
n
i
f
i
e
d
(
i
d
e
a
o
r
t
h
i
n
g
)
signifier(symbol) \Longleftrightarrow signified(idea \ or \ thing)
s i g n i f i e r ( s y m b o l ) ⟺ s i g n i f i e d ( i d e a o r t h i n g )
d
e
n
o
t
i
o
n
denotion
d e n o t i o n
在计算机中有三种方式去表示词/词的有用信息:
类似WordNet的资源库
离散化的符号例如“one-hot encoding”
利用“distributional similarity”分布相似性
下面分别说下这三种方法。
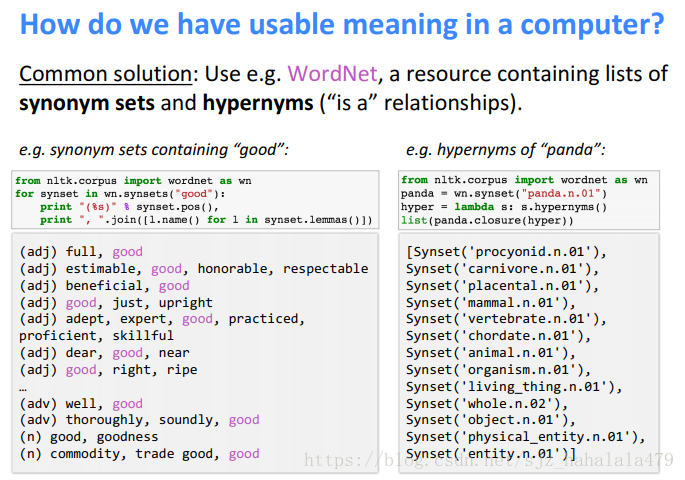
WordNet是一个包含了词的同义词和上级词的很大的资源库。
如果让计算机使用wordnet的方法获取词义会有一些问题:
词在不同的情况下有不同的同义词,但计算机并不知道如何区分使用环境。例如上图中的"good",它有表示专业上熟练的同义词“proficient”,也有表示食物熟了的同义词"wipe",但是"proficient"和"wipe"并不是同义词。
人类的语言是不断进化的,资料库不能保证永远up-to-date。
资料库是主观的,而且需要大量的人类精力来维护。
计算机不好根据资料库来计算词之间的相似度。
传统NLP中,我们会使用离散的符号表示离散的词语。比如,独热编码。
利用独热编码,将每个词汇都表示为一个向量。向量的维度是词汇表中词语的数量。
我们纵然可以使用这种方法来计算,包含不同词语的语言文本之间的相似性。但是,计算机仍然不懂这些词语的意思。由于词与词之间是正交的,点积的结果是0,计算机也无法计算词语之间的相似性。
那么我们自然而然想到的解决方式有两种:
一种是利用资料库,我们再做一个巨大的表示词与词相关性的矩阵
第二种是,我们能否例用表示一个词的向量本身,来去编码词与词的相关性。
根据词汇语义理论中的相似性分布是上一节中第二种解决方式的延伸。
它的核心想法是:一个词语的意义是由文本内容中它邻近的其它词赋予的 。考虑上图中banking的例子,它的意义就是有和它一起出现的gorvenment, debt problem, Europe等词赋予的。
corpus 语料库
在开始的时候,我们介绍一下神经网络词嵌入 的一个通用方法。我们希望定义一个模型。它通过词向量,基于中心词
w
t
w_t
w t
p
(
c
o
n
t
e
n
t
∣
w
t
)
p(\ content\ |w_t)
p ( c o n t e n t ∣ w t )
J
J
J
J
=
1
−
p
(
(
c
o
n
t
e
n
t
∣
w
t
)
)
J = 1 - p((\ content\ |w_t))
J = 1 − p ( ( c o n t e n t ∣ w t ) )
神经网络的历史中,关于直接学习低维词向量的目标,有一些比较经典的论文:
现在说回Word2Vec ,Word2Vec是一个学习词向量的框架,由谷歌在2013年首次提出。
有一个巨大的文本语料库
在固定的词汇表中,每个词都可以表示为1个向量
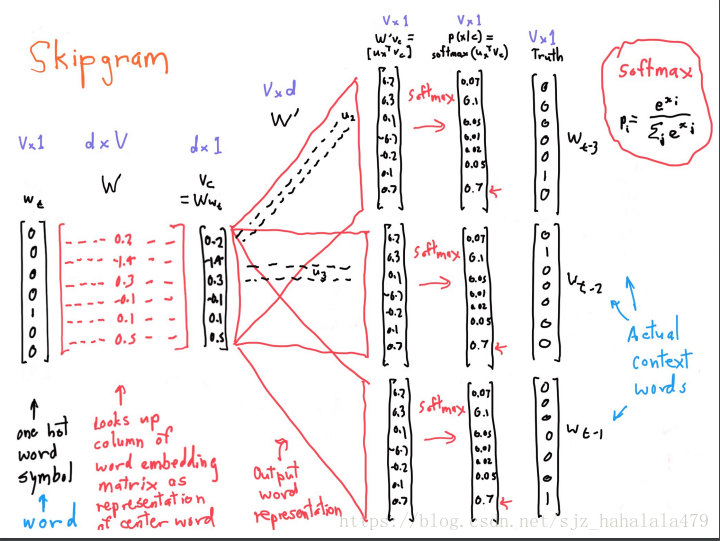
对文本的每个位置t 进行遍历,每个t 上都有中心词c ,和上下文词o 。
我们可以根据c和o的相似性,来计算给定c的情况下产生o的概率
我们需要不断调整词向量来最大化概率
本节课重点介绍两种算法:
skip-gram 算法
continuous bag of words算法
还有两种有效的训练方法:
Hierarchical softmax
Negative sampling
目标函数
给定超参数m 作为窗口的固定大小,对于文本的每个位置t ,基于中心词
w
t
w_t
w t
L
(
θ
)
=
∏
t
=
1
T
∏
−
m
≤
j
≤
m
,
j
≠
0
p
(
w
t
+
j
∣
w
t
;
θ
)
L(\theta) = \prod_{t=1}^{T} \prod_{-m \le j \le m, \ j \ne 0} p(w_{t+j}|w_{t} ; \theta)
L ( θ ) = t = 1 ∏ T − m ≤ j ≤ m , j ̸ = 0 ∏ p ( w t + j ∣ w t ; θ )
θ
\theta
θ
由于直接计算连乘概率十分不友好,我们将
L
(
θ
)
L(\theta)
L ( θ )
L
(
θ
)
L(\theta)
L ( θ )
J
(
θ
)
J(\theta)
J ( θ )
术语:loss function = objective function = cost function
如何计算
p
(
w
t
+
j
∣
w
t
;
θ
)
p(w_{t+j}|w_{t} ; \theta)
p ( w t + j ∣ w t ; θ ) softmax 函数。我们对每个词
w
w
w
v
w
v_w
v w
u
w
u_w
u w c )和上下文词(记做o ),有
P
(
o
∣
c
)
=
e
x
p
(
u
o
T
v
c
)
∑
w
∈
V
e
x
p
(
u
w
T
v
c
)
P(o|c) = \frac{exp({u_o}^Tv_c)}{\sum_{w \in V}exp(u_w^Tv_c)}
P ( o ∣ c ) = ∑ w ∈ V e x p ( u w T v c ) e x p ( u o T v c )
softmax 函数可以将任意的实值
x
i
x_i
x i
p
i
p_i
p i
“max”由于指数函数的特性,大的数映射后会更大,所以softmax对最大的
x
i
x_i
x i
“soft”是指,它仍然会分一点概率给小的值
skip-gram的流程如下:
关于
θ
\theta
θ
本节使用纯数学推导梯度,原式为:
P
(
o
∣
c
)
=
l
o
g
(
e
x
p
(
u
o
T
v
c
)
∑
w
∈
V
e
x
p
(
u
w
T
v
c
)
)
P(o|c) =log( \frac{exp({u_o}^Tv_c)}{\sum_{w \in V}exp(u_w^Tv_c)} )
P ( o ∣ c ) = l o g ( ∑ w ∈ V e x p ( u w T v c ) e x p ( u o T v c ) )
θ
\theta
θ
∂
P
∂
v
c
\frac{\partial P}{\partial v_c}
∂ v c ∂ P
首先:
∂
P
∂
v
c
=
∂
∂
v
c
l
o
g
(
e
x
p
(
u
o
T
v
c
)
−
∂
∂
v
c
l
o
g
(
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
)
=
∂
∂
v
c
(
u
o
T
v
c
)
−
∂
∂
v
c
l
o
g
(
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
)
(
1
)
\frac{\partial P}{\partial v_c} = \frac{\partial}{\partial v_c} log(exp({u_o}^Tv_c) - \frac{\partial}{\partial v_c} log(\sum_{w=1}^T exp(u_w^Tv_c)) \\ = \frac{\partial}{\partial v_c} ({u_o}^Tv_c) - \frac{\partial}{\partial v_c} log(\sum_{w=1}^T exp(u_w^Tv_c)) \ \ (1)
∂ v c ∂ P = ∂ v c ∂ l o g ( e x p ( u o T v c ) − ∂ v c ∂ l o g ( w = 1 ∑ T e x p ( u w T v c ) ) = ∂ v c ∂ ( u o T v c ) − ∂ v c ∂ l o g ( w = 1 ∑ T e x p ( u w T v c ) ) ( 1 )
求梯度时,有个很有用的tip:
∂
x
T
a
∂
x
=
∂
a
T
x
∂
x
=
a
\frac{\partial x^Ta}{\partial x} = \frac{\partial a^Tx}{\partial x} = a
∂ x ∂ x T a = ∂ x ∂ a T x = a
so,(1)式减号左边的项简化为
u
o
u_o
u o
Z
=
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
Z = \sum_{w=1}^T exp(u_w^Tv_c)
Z = w = 1 ∑ T e x p ( u w T v c )
F
=
l
o
g
(
Z
)
F = log(Z)
F = l o g ( Z )
∂
F
∂
v
c
=
∂
F
∂
Z
⋅
∂
Z
∂
v
c
=
1
Z
⋅
∂
Z
∂
v
c
\frac{\partial F}{\partial v_c} = \frac{\partial F}{\partial Z} \cdot \frac{\partial Z}{\partial v_c} = \frac{1}{Z} \cdot \frac{\partial Z}{\partial v_c}
∂ v c ∂ F = ∂ Z ∂ F ⋅ ∂ v c ∂ Z = Z 1 ⋅ ∂ v c ∂ Z
∂
Z
∂
v
c
\frac{\partial Z}{\partial v_c}
∂ v c ∂ Z
∂
Z
∂
v
c
=
∂
∂
v
c
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
=
∑
w
=
1
T
∂
∂
v
c
e
x
p
(
u
w
T
v
c
)
(
2
)
\frac{\partial Z}{\partial v_c} = \frac{\partial}{\partial v_c} \sum_{w=1}^T exp(u_w^Tv_c) \\ = \sum_{w=1}^T \frac{\partial}{\partial v_c} exp(u_w^Tv_c) \ (2)
∂ v c ∂ Z = ∂ v c ∂ w = 1 ∑ T e x p ( u w T v c ) = w = 1 ∑ T ∂ v c ∂ e x p ( u w T v c ) ( 2 )
Q
w
=
u
w
T
v
c
Q_w = u_w^Tv_c
Q w = u w T v c
∂
Z
∂
v
c
=
∂
Z
∂
Q
⋅
∂
Q
∂
v
c
\frac{\partial Z}{\partial v_c} = \frac{\partial Z}{\partial Q} \cdot \frac{\partial Q}{\partial v_c}
∂ v c ∂ Z = ∂ Q ∂ Z ⋅ ∂ v c ∂ Q
(2)式中,
∂
Z
∂
Q
=
∂
∂
Q
∑
w
=
1
T
e
x
p
(
Q
w
)
=
∑
w
=
1
T
∂
∂
Q
e
x
p
(
Q
w
)
=
∑
w
=
1
T
e
x
p
(
Q
w
)
\frac{\partial Z}{\partial Q} = \frac{\partial}{\partial Q} \sum_{w=1}^T exp(Q_w) \\ = \sum_{w=1}^T \frac{\partial}{\partial Q} exp(Q_w) \\ = \sum_{w=1}^T exp(Q_w)
∂ Q ∂ Z = ∂ Q ∂ w = 1 ∑ T e x p ( Q w ) = w = 1 ∑ T ∂ Q ∂ e x p ( Q w ) = w = 1 ∑ T e x p ( Q w )
∂
Z
∂
v
c
=
∂
Z
∂
Q
⋅
∂
Q
∂
v
c
=
∑
w
=
1
T
e
x
p
(
Q
w
)
⋅
u
w
=
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
⋅
u
w
\frac{\partial Z}{\partial v_c} = \frac{\partial Z}{\partial Q} \cdot \frac{\partial Q}{\partial v_c} \\ = \sum_{w=1}^T exp(Q_w) \cdot u_w \\ = \sum_{w=1}^T exp(u_w^Tv_c) \cdot u_w
∂ v c ∂ Z = ∂ Q ∂ Z ⋅ ∂ v c ∂ Q = w = 1 ∑ T e x p ( Q w ) ⋅ u w = w = 1 ∑ T e x p ( u w T v c ) ⋅ u w
那么,
∂
F
∂
v
c
=
1
Z
⋅
∂
Z
∂
v
c
=
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
⋅
u
w
Z
=
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
⋅
u
w
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
(
3
)
\frac{\partial F}{\partial v_c} = \frac{1}{Z} \cdot \frac{\partial Z}{\partial v_c} \\ = \frac{\sum_{w=1}^T exp(u_w^Tv_c) \cdot u_w}{Z} \\ =\frac {\sum_{w=1}^T exp(u_w^Tv_c) \cdot u_w}{\sum_{w=1}^T exp(u_w^Tv_c) } \ (3)
∂ v c ∂ F = Z 1 ⋅ ∂ v c ∂ Z = Z ∑ w = 1 T e x p ( u w T v c ) ⋅ u w = ∑ w = 1 T e x p ( u w T v c ) ∑ w = 1 T e x p ( u w T v c ) ⋅ u w ( 3 )
∑
x
=
1
T
e
x
p
(
u
x
T
v
c
)
⋅
u
x
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
=
∑
x
=
1
T
e
x
p
(
u
x
T
v
c
)
⋅
u
x
∑
w
=
1
T
e
x
p
(
u
w
T
v
c
)
=
∑
x
=
1
T
p
(
x
∣
c
)
⋅
u
x
\frac {\sum_{x=1}^T exp(u_x^Tv_c) \cdot u_x}{\sum_{w=1}^T exp(u_w^Tv_c) } \\ = \sum_{x=1}^T \frac {exp(u_x^Tv_c) \cdot u_x}{\sum_{w=1}^T exp(u_w^Tv_c) } \\ = \sum_{x=1}^T p(x|c) \cdot u_x
∑ w = 1 T e x p ( u w T v c ) ∑ x = 1 T e x p ( u x T v c ) ⋅ u x = x = 1 ∑ T ∑ w = 1 T e x p ( u w T v c ) e x p ( u x T v c ) ⋅ u x = x = 1 ∑ T p ( x ∣ c ) ⋅ u x
∂
P
∂
v
c
=
u
o
−
∑
x
=
1
T
p
(
x
∣
c
)
⋅
u
x
\frac{\partial P}{\partial v_c} = u_o - \sum_{x=1}^T p(x|c) \cdot u_x
∂ v c ∂ P = u o − x = 1 ∑ T p ( x ∣ c ) ⋅ u x
实际上,梯度可以看作,我们观察到的上下文当前的词向量,减去所有文本的期望。
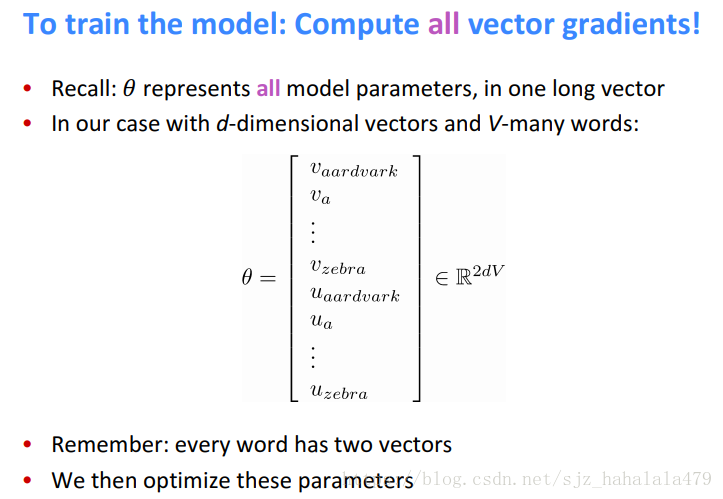
上文提到,我们不仅需要对每个center word求偏导,还要对context word求偏导。
上节演示了梯度的计算,这节我们要思考如何根据梯度优化我们的目标函数。
写成矩阵形式:
θ
n
e
w
=
θ
o
l
d
−
α
∇
θ
J
(
θ
)
\theta^{new} = \theta^{old} - \alpha \nabla_{\theta}J(\theta)
θ n e w = θ o l d − α ∇ θ J ( θ )
θ
\theta
θ
θ
j
\theta_{j}
θ j
θ
j
n
e
w
=
θ
j
o
l
d
−
α
∂
∂
θ
j
o
l
d
θ
J
(
θ
j
)
\theta_{j}^{new} = \theta_{j}^{old} - \alpha \frac{\partial}{\partial \theta_{j}^{old}}{\theta}J(\theta_j)
θ j n e w = θ j o l d − α ∂ θ j o l d ∂ θ J ( θ j )
def func1 ( ) :
while True :
theta_grad = evaluate_gradient( J, corpus, theta)
theta_new = theta_old = alpha * theta_grad
每次对
θ
\theta
θ
θ
j
\theta_j
θ j 随机梯度下降(SGD) 。
def func2 ( ) :
while True :
window = sample_window( cprpus)
theta_grad = evaluate_gradient( J, window, theta)
theta_new = theta_old = alpha * theta_grad