看到简化版的题目,我觉得我就像一个脑残,根本看不懂,只有看到原题目,我才知道要做啥。我现在把原题目贴出来,然后一一的解答。

题目意思:
(a) 证明softmax函数的一个性质,在输入中存在偏移,但softmax的值是不随着偏移而改变。在实践中,我们认为这个偏移值一般是输入中的最大值。
(b) 给出输入矩阵,N行D列,然后计算每行的softmax函数值,最好是采用向量化来实现,以便为后续提供一个好的基础。一个非向量化实现的方式,不会得到全部的分数。
解答二个部分:
(a)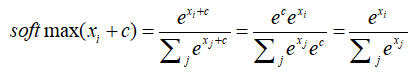
根据指数函数的性质,可以得到此偏移不变形。
(b)编程实现
在这个问题中,我们需要主要的几点:
1,在处理此类问题的时候,向量化操作真的很重要,所以能向量化就向量化,当然对于初学者来说,这种向量化的思路可能刚开始很难理解,但需要不断的熟悉这种思想,然后不断的去应用。在向量化中,必不可少的一个库就是numpy。
numpy的学习网站:https://www.jianshu.com/p/358948fbbc6e
2,在这个问题中,一个技巧,就是利用到了上一步的偏移以及trick,就是这个偏移值是最大的值,否则在官网给出的测试用例就会有溢出的问题。
import numpy as np
def softmax(x):
"""Compute the softmax function for each row of the input x.
It is crucial that this function is optimized for speed because
it will be used frequently in later code. You might find numpy
functions np.exp, np.sum, np.reshape, np.max, and numpy
broadcasting useful for this task.
Numpy broadcasting documentation:
http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html
You should also make sure that your code works for a single
D-dimensional vector (treat the vector as a single row) and
for N x D matrices. This may be useful for testing later. Also,
make sure that the dimensions of the output match the input.
You must implement the optimization in problem 1(a) of the
written assignment!
Arguments:
x -- A D dimensional vector or N x D dimensional numpy matrix.
Return:
x -- You are allowed to modify x in-place
"""
orig_shape = x.shape
if len(x.shape) > 1:
# Matrix
x = x - np.max(x, axis=1, keepdims=True)
x = np.exp(x)/np.sum(np.exp(x), axis=1, keepdims=True)
else:
# Vector
x = x - np.max(x)
x = np.exp(x)/np.sum(np.exp(x))
assert x.shape == orig_shape
return x
def test_softmax_basic():
"""
Some simple tests to get you started.
Warning: these are not exhaustive.
"""
print "Running basic tests..."
test1 = softmax(np.array([1,2]))
print test1
ans1 = np.array([0.26894142, 0.73105858])
assert np.allclose(test1, ans1, rtol=1e-05, atol=1e-06)
test2 = softmax(np.array([[1001,1002],[3,4]]))
print test2
ans2 = np.array([
[0.26894142, 0.73105858],
[0.26894142, 0.73105858]])
assert np.allclose(test2, ans2, rtol=1e-05, atol=1e-06)
test3 = softmax(np.array([[-1001,-1002]]))
print test3
ans3 = np.array([0.73105858, 0.26894142])
assert np.allclose(test3, ans3, rtol=1e-05, atol=1e-06)
print "You should be able to verify these results by hand!\n"
if __name__ == "__main__":
test_softmax_basic()
测试结果:
我把最后一个print注释掉了,截图如下:

手工去测试一下程序:对于指数函数而言,图像如下:

所以对于数值很大的情况,数值可以说很爆炸了,对于数值很小的情况,又太小了,所以采用偏移不变性是一个很好的解决措施。
对于程序里,老师给出的框架中,assert是做断言,用于捕捉错误信息,看是否计算出来的数值与真实的数值相差的情况。



题目解释:
(a)推导sigmod函数的梯度,并且将其写成复合函数的形式。假定输入的x是标量。
(b)推导梯度下降(采用交叉熵的softmax函数), 此时class label可以视为0-1的one-hot编码形式,也就是只有一个1,其余均为0。
(c)推导梯度下降,输入x,只有一层隐藏层的神经网络,损失函数利用交叉熵来度量,神经网络中激活函数利用sigmod函数来作为激活函数,利用softmax函数来作用于输出层, 标签采用one-hot的形式。(其实就是神经网络的常规推导)
(d)在上图的神经网络中有多少个参数,假定输入有Dx维,输出有Dy维,有H个神经元。
(e)编写sigmod激活函数和其梯度的程序
(f)编写梯度检测的程序
(g)编写只有一个sigmod隐藏层的神经网络的前向和后向推导。
解答这几个问题:
(a)sigmod函数求导

(b) 输出层的求导情况

(c)主要考的就是链式法则的应用,在这个问题中,主要注意的是矩阵的维度的问题,就是到底用不用转置,需要根据具体的维度变化来决定。

(d)考虑参数的个数,第一层(隐藏层)+第二层(输出层)
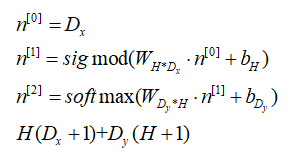
(e) 编写sigmod函数及其求导函数
#!/usr/bin/env python
import numpy as np
def sigmoid(x):
"""
Compute the sigmoid function for the input here.
Arguments:
x -- A scalar or numpy array.
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + np.exp(-x))
return s
def sigmoid_grad(s):
"""
Compute the gradient for the sigmoid function here. Note that
for this implementation, the input s should be the sigmoid
function value of your original input x.
Arguments:
s -- A scalar or numpy array.
Return:
ds -- Your computed gradient.
"""
ds = s * (1 - s)
return ds
def test_sigmoid_basic():
"""
Some simple tests to get you started.
Warning: these are not exhaustive.
"""
print "Running basic tests..."
x = np.array([[1, 2], [-1, -2]])
f = sigmoid(x)
g = sigmoid_grad(f)
print f
f_ans = np.array([
[0.73105858, 0.88079708],
[0.26894142, 0.11920292]])
assert np.allclose(f, f_ans, rtol=1e-05, atol=1e-06)
print g
g_ans = np.array([
[0.19661193, 0.10499359],
[0.19661193, 0.10499359]])
assert np.allclose(g, g_ans, rtol=1e-05, atol=1e-06)
print "You should verify these results by hand!\n"
if __name__ == "__main__":
test_sigmoid_basic()
测试结果:

(f) 梯度检查,利用双边检查,得到的精确度更高。
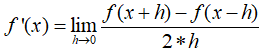
#!/usr/bin/env python
import numpy as np
import random
# First implement a gradient checker by filling in the following functions
def gradcheck_naive(f, x):
""" Gradient check for a function f.
Arguments:
f -- a function that takes a single argument and outputs the
cost and its gradients
x -- the point (numpy array) to check the gradient at
"""
rndstate = random.getstate()
random.setstate(rndstate)
fx, grad = f(x) # Evaluate function value at original point
h = 1e-4 # Do not change this!
# Iterate over all indexes ix in x to check the gradient.
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
ix = it.multi_index
# Try modifying x[ix] with h defined above to compute numerical
# gradients (numgrad).
# Use the centered difference of the gradient.
# It has smaller asymptotic error than forward / backward difference
# methods. If you are curious, check out here:
# https://math.stackexchange.com/questions/2326181/when-to-use-forward-or-central-difference-approximations
# Make sure you call random.setstate(rndstate)
# before calling f(x) each time. This will make it possible
# to test cost functions with built in randomness later.
x[ix] += h
f1 = f(x)[0]
x[ix] -= 2 * h
f2 = f(x)[0]
x[ix] += h
numgrad = (f1-f2)/(2*h)
# Compare gradients
reldiff = abs(numgrad - grad[ix]) / max(1, abs(numgrad), abs(grad[ix]))
if reldiff > 1e-5:
print "Gradient check failed."
print "First gradient error found at index %s" % str(ix)
print "Your gradient: %f \t Numerical gradient: %f" % (
grad[ix], numgrad)
return
it.iternext() # Step to next dimension
print "Gradient check passed!"
def sanity_check():
"""
Some basic sanity checks.
"""
quad = lambda x: (np.sum(x ** 2), x * 2)
print "Running sanity checks..."
gradcheck_naive(quad, np.array(123.456)) # scalar test
gradcheck_naive(quad, np.random.randn(3,)) # 1-D test
gradcheck_naive(quad, np.random.randn(4,5)) # 2-D test
print ""
if __name__ == "__main__":
sanity_check()
程序解释:在函数gradcheck_naive(f, x) , 其中f是一个函数,接受一个参数的函数,返回的是一个元祖,包含二项,第一项为损失函数cost的数值,第二项为梯度数值;x为进行检测的输入的数值,可以是标量,也可以是矩阵(向量)。设置了一个随机种子,以便你的测试是同一的随机种子产生,产生正确的结果。然后np.nditer就是一个迭代器,多重索引的迭代器,然后基于索引的基础上,然后进行双边的梯度检查,然后换下一个数据进行迭代。
【只有实践,才能发现原来有含糊的地方,是一定会出错的,不过早出错比较好。】
在这个地方:我有一个小bug的出现,在这个单个测试中,输入只是一个数值的情况下,这种方法是适用的,但如果是多个的情况下,f(x[ix]+h)是会出错的,因为这个时候输入的是一个数值,而不是整个数据。

(g) 最后一个是实现二层的神经网络(其中一层为隐藏层,一层为输出层)
#!/usr/bin/env python
import numpy as np
import random
from q1_softmax import softmax
from q2_sigmoid import sigmoid, sigmoid_grad
from q2_gradcheck import gradcheck_naive
def forward_backward_prop(X, labels, params, dimensions):
"""
Forward and backward propagation for a two-layer sigmoidal network
Compute the forward propagation and for the cross entropy cost,
the backward propagation for the gradients for all parameters.
Notice the gradients computed here are different from the gradients in
the assignment sheet: they are w.r.t. weights, not inputs.
Arguments:
X -- M x Dx matrix, where each row is a training example x.
labels -- M x Dy matrix, where each row is a one-hot vector.
params -- Model parameters, these are unpacked for you.
dimensions -- A tuple of input dimension, number of hidden units
and output dimension
"""
### Unpack network parameters (do not modify)
ofs = 0
Dx, H, Dy = (dimensions[0], dimensions[1], dimensions[2])
W1 = np.reshape(params[ofs:ofs + Dx * H], (Dx, H))
ofs += Dx * H
b1 = np.reshape(params[ofs:ofs + H], (1, H))
ofs += H
W2 = np.reshape(params[ofs:ofs + H * Dy], (H, Dy))
ofs += H * Dy
b2 = np.reshape(params[ofs:ofs + Dy], (1, Dy))
# Note: compute cost based on `sum` not `mean`.
z1 = X.dot(W1) + b1
a1 = sigmoid(z1)
z2 = a1.dot(W2) + b2
a2 = softmax(z2)
cost = -np.sum(labels * np.log(a2))
gradz2 = (a2 - labels)
gradW2 = a1.T.dot(gradz2)
gradb2 = np.sum(gradz2, axis=0, keepdims=True)
grada1 = gradz2.dot(W2.T)
gradz1 = grada1*sigmoid_grad(a1)
gradW1 = X.T.dot(gradz1)
gradb1 = np.sum(gradz1, axis=0, keepdims=True)
### Stack gradients (do not modify)
grad = np.concatenate((gradW1.flatten(), gradb1.flatten(), gradW2.flatten(), gradb2.flatten()))
grad.resize((len(grad), 1))
return cost, grad
def sanity_check():
"""
Set up fake data and parameters for the neural network, and test using
gradcheck.
"""
print "Running sanity check..."
N = 20
dimensions = [10, 5, 10]
data = np.random.randn(N, dimensions[0]) # each row will be a datum
labels = np.zeros((N, dimensions[2]))
for i in xrange(N):
labels[i, random.randint(0, dimensions[2]-1)] = 1
params = np.random.randn((dimensions[0] + 1) * dimensions[1] + (
dimensions[1] + 1) * dimensions[2], 1)
gradcheck_naive(lambda params: forward_backward_prop(data, labels, params, dimensions), params)
if __name__ == "__main__":
sanity_check()
在这个问题的实现中,我也犯了一个蠢,就是对于sigmod的求导的地方有含糊,就是不知道到底是那个进行变化,我现在对其重新确定一下。
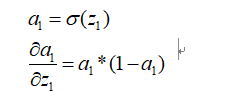
然后在本程序中,调用sigmod_grad(a1)就是求上面的这个倒数值。
测试结果:





题目解释:
(a) 中心词的索引为c,预测索引为o的词是否为中心词的窗口范围的词,其中u(w)为字典中的所有的词的词向量,其实就是用二套词向量来进行表示,方便解耦合,简化学习过程。说了这么多,这个题目就是求一个梯度。
(b)仍然求一个梯度。
(c)在(a)与(b)中,采用的传统的,也就是初步的word2vec来实现的,但我们知道采用负采样的方法,实现效率更高。所以,这个题目就是用来验证这个结论。用CE loss的运行时间除以negative sampling loss的运行时间来作为speed-up ratio。
(d)word2vec中有二种类别,一种为CBOW, 另一种为skip-gram。窗口大小为m, 然后二种方式的梯度的推导。这是一个不断扩展的问题,一步步的从抽象的情况,扩展到具体的情况。
(e)补充word2vec模型,然后利用随机梯度下降来训练你自己的词向量。在文件中,需要书写的有:一个归一化矩阵的行的函数,填充softmax函数和梯度下降函数,补充skip-gram的损失函数和梯度下降函数。(其实就是实现skip-gram)
(f)实现随机梯度下降算法
(g)下载实际生活的数据,然后利用补充的程序来训练词向量。使用的是斯坦福的语义分析树语料库来训练,这个训练好的部分会用于下一个部分的语义分析任务。
(h)扩展补充CBOW算法。
题目解答:
(a)(b)(这个地方涉及到了矩阵微分的知识,这个地方的求导有些许的问题,待我看完矩阵微分方法之后来解决这个BUG)

(c)word2vec的负采样实现中,一次迭代中只需要计算的是K+1个数据, 而对于传统的softmax方式中,则需要计算的是W+1个数据,所以,时间花费大约为(W+1)/(K+1)

(d)对于skip-gram而言, 推导如下:
现在我们考虑的是一个具体的情况,然后更新的就是vc,对于vj而言,是不做处理的,所以就是窗口范围内的更新参数。

对于CBOW而言,推导如下:

对于skip-gram而言,简单说:就是已知中心词,然后求窗口上下文的情况;对于CBOW而言,简单说:就是知道窗口上下文的情况,然后求中心词的情况,中心词采用上下文次的平均来计算。这样就可以知道,损失函数到底与什么有关,与什么无关了。
(e)这一部分卡了好久,尤其在负采样那个函数里面,卡了真的好久好久。虽然难产,但还是产出来了。
在这个程序中,第一个函数NormalizeRows(x)是对输入数据进行归一化操作,归一化的方法是通过按行的模长的归一化方法。也就是每一行的每一个数值除以此行的向量的模长来实现。(根据给出的例子,也就是test_normalize_rows我们可以推断出来。)
对于softmaxCostAndGradient函数,就是通过(a)(b)的公式来实现。但一定注意的是矩阵的维度,尤其是对于(3L, )这个问题,很容易出现各种莫名其妙的问题,所以最好就把矩阵的维度统一,这样比较容易求。
对于getNegativeSamples函数,就是通过随机采样函数,来得到K个负采样的单词的索引。
对于negSamplingCostAndGradient函数,就是通过(c)的公式来是实现,也是要注意矩阵维度的变化。
对于skipgram(cbow)函数,就是通过(d)的公式,来把每一个中心词,上下文词串起来,最后得到结果。
对于word2vec_sgd_wrapper函数,类似与一个框架,将Word2vecmodel全部框起来,也就是可以采用skipgram实现,也可以采用cbow来实现。
对于test_word2vec函数,就是测试的接口。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
import random
from q1_softmax import softmax
from q2_gradcheck import gradcheck_naive
from q2_sigmoid import sigmoid, sigmoid_grad
def normalizeRows(x):
""" Row normalization function
# 除以模长的归一化方法
Implement a function that normalizes each row of a matrix to have
unit length.
"""
x = x / (np.sqrt(np.sum(x*x, axis=1, keepdims=True)))
return x
def test_normalize_rows():
print "Testing normalizeRows..."
x = normalizeRows(np.array([[3.0,4.0],[1, 2]]))
print x
ans = np.array([[0.6,0.8],[0.4472136,0.89442719]])
assert np.allclose(x, ans, rtol=1e-05, atol=1e-06)
print ""
def softmaxCostAndGradient(predicted, target, outputVectors, dataset):
""" Softmax cost function for word2vec models
Implement the cost and gradients for one predicted word vector
and one target word vector as a building block for word2vec
models, assuming the softmax prediction function and cross
entropy loss.
Arguments:
predicted -- numpy ndarray, predicted word vector (\hat{v} in
the written component)
target -- integer, the index of the target word
outputVectors -- "output" vectors (as rows) for all tokens
dataset -- needed for negative sampling, unused here.
Return:
cost -- cross entropy cost for the softmax word prediction
gradPred -- the gradient with respect to the predicted word
vector
grad -- the gradient with respect to all the other word
vectors
We will not provide starter code for this function, but feel
free to reference the code you previously wrote for this
assignment!
"""
# 为了避免出错,最好利用reshape来将矩阵来转变为自己需要的那一种类型, 因为softmax是对行来进行
predicted = predicted.reshape([1, predicted.shape[0]])
y_hot = softmax(predicted.dot(outputVectors.T)).reshape([outputVectors.shape[0], 1])
y_real = np.zeros_like(y_hot)
y_real[target] = 1
cost = -np.log(y_hot[target])
gradPred = (y_hot-y_real).T.dot(outputVectors)
grad = (y_hot-y_real).dot(predicted)
return cost, gradPred, grad
def getNegativeSamples(target, dataset, K):
""" Samples K indexes which are not the target
随机负采样K个数值
"""
indices = [None] * K
for k in xrange(K):
newidx = dataset.sampleTokenIdx()
while newidx == target:
newidx = dataset.sampleTokenIdx()
indices[k] = newidx
return indices
def negSamplingCostAndGradient(predicted, target, outputVectors, dataset,
K=10):
""" Negative sampling cost function for word2vec models
Implement the cost and gradients for one predicted word vector
and one target word vector as a building block for word2vec
models, using the negative sampling technique. K is the sample
size.
Note: See test_word2vec below for dataset's initialization.
Arguments/Return Specifications: same as softmaxCostAndGradient
"""
# Sampling of indices is done for you. Do not modify this if you
# wish to match the autograder and receive points!
indices = [target]
indices.extend(getNegativeSamples(target, dataset, K))
predicted = predicted.reshape([predicted.shape[0], 1])
gradPred = np.zeros(predicted.shape)
cost = 0
soft_vc = sigmoid(outputVectors[target, :].dot(predicted)) # [1, D]*[D, 1]=[1, 1]
cost -= np.log(soft_vc)
gradPred += (soft_vc-1.0) * outputVectors[target, :].reshape(predicted.shape) # [D,1]
grad_temp = np.zeros([outputVectors.shape[0], 1]) # [M, 1]
grad_temp[target] = soft_vc-1.0
for i in range(1, len(indices)):
soft_vk = sigmoid(-outputVectors[indices[i], :].dot(predicted))
cost -= np.log(soft_vk)
gradPred -= (soft_vk-1.0) * outputVectors[indices[i], :].reshape(predicted.shape)
grad_temp[indices[i]] -= (soft_vk-1.0)
grad = grad_temp.dot(predicted.T) # [M, 1]*[1, D]=[M, D]
return cost, gradPred, grad
def skipgram(currentWord, C, contextWords, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient=softmaxCostAndGradient):
""" Skip-gram model in word2vec
Implement the skip-gram model in this function.
Arguments:
currentWord -- a string of the current center word
C -- integer, context size
contextWords -- list of no more than 2*C strings, the context words
tokens -- a dictionary that maps words to their indices in
the word vector list
inputVectors -- "input" word vectors (as rows) for all tokens
outputVectors -- "output" word vectors (as rows) for all tokens
word2vecCostAndGradient -- the cost and gradient function for
a prediction vector given the target
word vectors, could be one of the two
cost functions you implemented above.
Return:
cost -- the cost function value for the skip-gram model
grad -- the gradient with respect to the word vectors
"""
cost = 0.0
gradIn = np.zeros(inputVectors.shape)
gradOut = np.zeros(outputVectors.shape)
for word in contextWords:
cost_1, gradPred1, grad1 = word2vecCostAndGradient(inputVectors[tokens[currentWord]], tokens[word],
outputVectors, dataset)
cost += cost_1
gradIn[tokens[currentWord], :] += np.squeeze([gradPred1])
gradOut += grad1
return cost, gradIn, gradOut
def cbow(currentWord, C, contextWords, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient=softmaxCostAndGradient):
"""CBOW model in word2vec
Implement the continuous bag-of-words model in this function.
Arguments/Return specifications: same as the skip-gram model
Extra credit: Implementing CBOW is optional, but the gradient
derivations are not. If you decide not to implement CBOW, remove
the NotImplementedError.
"""
cost = 0.0
gradIn = np.zeros(inputVectors.shape)
gradOut = np.zeros(outputVectors.shape)
### YOUR CODE HERE
raise NotImplementedError
### END YOUR CODE
return cost, gradIn, gradOut
#############################################
# Testing functions below. DO NOT MODIFY! #
#############################################
def word2vec_sgd_wrapper(word2vecModel, tokens, wordVectors, dataset, C,
word2vecCostAndGradient=softmaxCostAndGradient):
batchsize = 50
cost = 0.0
grad = np.zeros(wordVectors.shape)
N = wordVectors.shape[0]
inputVectors = wordVectors[:N/2,:]
outputVectors = wordVectors[N/2:,:]
for i in xrange(batchsize):
C1 = random.randint(1,C)
centerword, context = dataset.getRandomContext(C1)
if word2vecModel == skipgram:
denom = 1
else:
denom = 1
c, gin, gout = word2vecModel(
centerword, C1, context, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient)
cost += c / batchsize / denom
grad[:N/2, :] += gin / batchsize / denom
grad[N/2:, :] += gout / batchsize / denom
return cost, grad
def test_word2vec():
""" Interface to the dataset for negative sampling """
dataset = type('dummy', (), {})()
def dummySampleTokenIdx():
return random.randint(0, 4)
def getRandomContext(C):
tokens = ["a", "b", "c", "d", "e"]
return tokens[random.randint(0,4)], \
[tokens[random.randint(0,4)] for i in xrange(2*C)]
dataset.sampleTokenIdx = dummySampleTokenIdx
dataset.getRandomContext = getRandomContext
random.seed(31415)
np.random.seed(9265)
dummy_vectors = normalizeRows(np.random.randn(10,3))
dummy_tokens = dict([("a",0), ("b",1), ("c",2),("d",3),("e",4)])
print "==== Gradient check for skip-gram ===="
gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
skipgram, dummy_tokens, vec, dataset, 5, softmaxCostAndGradient),
dummy_vectors)
gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
skipgram, dummy_tokens, vec, dataset, 5, negSamplingCostAndGradient),
dummy_vectors)
# print "\n==== Gradient check for CBOW ===="
# gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
# cbow, dummy_tokens, vec, dataset, 5, softmaxCostAndGradient),
# dummy_vectors)
# gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
# cbow, dummy_tokens, vec, dataset, 5, negSamplingCostAndGradient),
# dummy_vectors)
print "\n=== Results ==="
print skipgram("c", 3, ["a", "b", "e", "d", "b", "c"],
dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset)
print skipgram("c", 1, ["a", "b"],
dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset,
negSamplingCostAndGradient)
# print cbow("a", 2, ["a", "b", "c", "a"],
# dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset)
# print cbow("a", 2, ["a", "b", "a", "c"],
# dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset,
# negSamplingCostAndGradient)
if __name__ == "__main__":
test_normalize_rows()
test_word2vec()
(f)这个是实现SGD函数,这一个填写的部分比较简单。
拿到一个这样需要补全的程序,第一步首先需要明确自己需要补全的那部分程序是那部分了,第二步,if __name__=='__main__'看起,因为这个是程序的入口,然后根据程序的流程来理解。
对于sanity_check函数,就是调用sgd的一个接口。
对于sgd函数,参数的每个的意思都在下面。然后在迭代过程中,我们需要通过梯度来更新变量,尤其注意,不要忘记postprocessing函数,因为是一个迭代的过程,不能只在初始的时候对变量进行预处理(归一化),在迭代过程,也不能忘记呀。
对于save_params函数,就是每隔多少次的迭代,就保存一下参数的作用。
对于load_saved_params函数,就是导入之前保存的参数。
#!/usr/bin/env python
# Save parameters every a few SGD iterations as fail-safe
SAVE_PARAMS_EVERY = 5000
import glob
import random
import numpy as np
import os.path as op
import cPickle as pickle
def load_saved_params():
"""
A helper function that loads previously saved parameters and resets
iteration start.
"""
st = 0
for f in glob.glob("saved_params_*.npy"):
iter = int(op.splitext(op.basename(f))[0].split("_")[2])
if (iter > st):
st = iter
if st > 0:
with open("saved_params_%d.npy" % st, "r") as f:
params = pickle.load(f)
state = pickle.load(f)
return st, params, state
else:
return st, None, None
def save_params(iter, params):
with open("saved_params_%d.npy" % iter, "w") as f:
pickle.dump(params, f)
pickle.dump(random.getstate(), f)
def sgd(f, x0, step, iterations, postprocessing=None, useSaved=False,
PRINT_EVERY=10):
""" Stochastic Gradient Descent
Implement the stochastic gradient descent method in this function.
Arguments:
f -- the function to optimize, it should take a single
argument and yield two outputs, a cost and the gradient
with respect to the arguments
x0 -- the initial point to start SGD from
step -- the step size for SGD
iterations -- total iterations to run SGD for
postprocessing -- postprocessing function for the parameters
if necessary. In the case of word2vec we will need to
normalize the word vectors to have unit length.
PRINT_EVERY -- specifies how many iterations to output loss
Return:
x -- the parameter value after SGD finishes
"""
# Anneal learning rate every several iterations
ANNEAL_EVERY = 20000
if useSaved:
start_iter, oldx, state = load_saved_params()
if start_iter > 0:
x0 = oldx
step *= 0.5 ** (start_iter / ANNEAL_EVERY)
if state:
random.setstate(state)
else:
start_iter = 0
x = x0
if not postprocessing:
postprocessing = lambda x: x
expcost = None
for iter in xrange(start_iter + 1, iterations + 1):
# Don't forget to apply the postprocessing after every iteration!
# You might want to print the progress every few iterations.
cost = None
### YOUR CODE HERE
cost, grad = f(x)
x -= step * grad
postprocessing(x)
### END YOUR CODE
if iter % PRINT_EVERY == 0:
if not expcost:
expcost = cost
else:
expcost = .95 * expcost + .05 * cost
print "iter %d: %f" % (iter, expcost)
if iter % SAVE_PARAMS_EVERY == 0 and useSaved:
save_params(iter, x)
if iter % ANNEAL_EVERY == 0:
step *= 0.5
return x
def sanity_check():
quad = lambda x: (np.sum(x ** 2), x * 2)
print "Running sanity checks..."
t1 = sgd(quad, 0.5, 0.01, 1000, PRINT_EVERY=100)
print "test 1 result:", t1
assert abs(t1) <= 1e-6
t2 = sgd(quad, 0.0, 0.01, 1000, PRINT_EVERY=100)
print "test 2 result:", t2
assert abs(t2) <= 1e-6
t3 = sgd(quad, -1.5, 0.01, 1000, PRINT_EVERY=100)
print "test 3 result:", t3
assert abs(t3) <= 1e-6
print ""
if __name__ == "__main__":
sanity_check()
(g) 训练一个语料库,代码如下。
数据集采用的是斯坦福语义分析的数据集。词向量的维度为10,单词上下文窗户大小为5,WordVectors包含二个部分的向量,也就是我们常说的u,v的情况。外层是sgd函数,然后利用sgd的函数应用到word2vec_sgd_warpper上。
迭代40000次,,真的好花费时间呀。
然后对得到的词向量的情况,对其中的某些单词进行降维,来看最后的情况单词的情况。
#!/usr/bin/env python
import random
import numpy as np
from utils.treebank import StanfordSentiment
import matplotlib
matplotlib.use('agg')
import matplotlib.pyplot as plt
import time
from q3_word2vec import *
from q3_sgd import *
# Reset the random seed to make sure that everyone gets the same results
random.seed(314)
dataset = StanfordSentiment()
tokens = dataset.tokens()
nWords = len(tokens)
# We are going to train 10-dimensional vectors for this assignment
dimVectors = 10
# Context size
C = 5
# Reset the random seed to make sure that everyone gets the same results
random.seed(31415)
np.random.seed(9265)
startTime=time.time()
wordVectors = np.concatenate(
((np.random.rand(nWords, dimVectors) - 0.5) /
dimVectors, np.zeros((nWords, dimVectors))),
axis=0)
wordVectors = sgd(
lambda vec: word2vec_sgd_wrapper(skipgram, tokens, vec, dataset, C,
negSamplingCostAndGradient),
wordVectors, 0.3, 40000, None, True, PRINT_EVERY=10)
# Note that normalization is not called here. This is not a bug,
# normalizing during training loses the notion of length.
print "sanity check: cost at convergence should be around or below 10"
print "training took %d seconds" % (time.time() - startTime)
# concatenate the input and output word vectors
wordVectors = np.concatenate(
(wordVectors[:nWords,:], wordVectors[nWords:,:]),
axis=0)
# wordVectors = wordVectors[:nWords,:] + wordVectors[nWords:,:]
visualizeWords = [
"the", "a", "an", ",", ".", "?", "!", "``", "''", "--",
"good", "great", "cool", "brilliant", "wonderful", "well", "amazing",
"worth", "sweet", "enjoyable", "boring", "bad", "waste", "dumb",
"annoying"]
visualizeIdx = [tokens[word] for word in visualizeWords]
visualizeVecs = wordVectors[visualizeIdx, :]
temp = (visualizeVecs - np.mean(visualizeVecs, axis=0))
covariance = 1.0 / len(visualizeIdx) * temp.T.dot(temp)
U,S,V = np.linalg.svd(covariance)
coord = temp.dot(U[:,0:2])
for i in xrange(len(visualizeWords)):
plt.text(coord[i,0], coord[i,1], visualizeWords[i],
bbox=dict(facecolor='green', alpha=0.1))
plt.xlim((np.min(coord[:,0]), np.max(coord[:,0])))
plt.ylim((np.min(coord[:,1]), np.max(coord[:,1])))
plt.savefig('q3_word_vectors.png')
画出的单词的图像如下:



题目解释:使用已经训练好的词向量,然后进行一个语义情感分析的步骤,对于语料库中的每个句子,我们采用单词的平均词向量来作为句子的特征,然后预测句子的情感分析。分为了5个等级,训练一个softmax分类器来实现目的。
很负面(0),负面(1),中立(2), 积极(3),很积极(4)(a)完成句子向量特征的计算。利用句子中的词向量的平均来表示。
(b)解释为什么需要在分类时进行正则化。(normalization, regulariza就tion)
(c)填写超参数选择的代码来寻找最好的超参数。至少要在验证集和测试集上达到36.5%的准确率。
(d)使用自己训练的词向量来跑情感分类的程序,然后使用已经训练好的GLOVE模型来跑情感分类的程序,比较在训练集,验证集和测试集上的准确率。为什么预训练的GLOVE模型效果更好,明确并提出至少3个不同的原因。
(e)画出使用GLOVE词向量的训练集合验证集上的准确率曲线,采用log函数来做处理。剪短的解释从曲线中得到什么。
(f)分析模型产生错误的原因,简短的解释混淆矩阵。
(g)分析3个分类错误的例子来进行解释,并且简短的说明什么样的特征总能够将会被分类错误。尽力的找出错误的原因。
题目解答:
(a)就是利用句子的每个单词的词向量的平均来作为句子的特征,来进行处理。具体程序在后面。
但自己写的程序效率不是特别高,因为没有很好的利用到向量化的手段,需要不断的进行学习。
(b)正则化的好坏就在于防止过拟合。正则化的常用的方法为L1正则化,L2正则化。对于L2正则化而言,减少参数的数值,以便在数据发生偏移的时候,结果影响不大,也就是提高模型对于未知实例的泛化能力。
(c)在getRegularizarionValues函数中,通过函数来给values赋一系列的浮点数的值。
在chooseBestModel函数中,通过字典中的关键字dev来进行排序。
(d)结果显示:
对于youevectors而言:
=== Recap ===
Reg Train Dev Test
1.00E-02 30.946 32.334 29.910
1.10E-02 30.922 32.334 29.955
1.20E-02 30.946 32.334 29.910
1.32E-02 30.922 32.243 29.955
1.45E-02 30.840 32.153 30.000
1.59E-02 30.770 32.153 30.000
1.75E-02 30.735 32.243 29.910
1.92E-02 30.817 31.789 29.955
2.10E-02 30.735 31.698 29.955
2.31E-02 30.770 31.698 29.955
2.54E-02 30.618 31.608 30.000
2.78E-02 30.501 31.608 30.090
3.05E-02 30.524 31.698 29.910
3.35E-02 30.431 31.608 29.955
3.68E-02 30.360 31.698 29.819
4.04E-02 30.325 31.608 29.864
4.43E-02 30.302 31.880 30.045
4.86E-02 30.349 31.880 30.136
5.34E-02 30.384 31.971 29.955
5.86E-02 30.396 32.062 29.955
6.43E-02 30.349 32.153 30.000
7.05E-02 30.372 32.243 30.045
7.74E-02 30.325 32.425 30.045
8.50E-02 30.290 32.062 30.136
9.33E-02 30.302 31.880 29.955
1.02E-01 30.302 31.971 29.910
1.12E-01 30.314 31.789 29.729
1.23E-01 30.279 31.971 29.638
1.35E-01 30.185 31.789 29.774
1.48E-01 30.162 31.880 29.638
1.63E-01 30.044 31.789 29.502
1.79E-01 29.998 32.062 29.367
1.96E-01 29.963 31.971 29.412
2.15E-01 29.740 32.062 29.502
2.36E-01 29.635 31.698 29.321
2.60E-01 29.717 31.971 29.095
2.85E-01 29.494 32.062 29.005
3.13E-01 29.459 31.880 28.824
3.43E-01 29.506 31.789 28.778
3.76E-01 29.459 31.517 28.371
4.13E-01 29.424 31.335 28.326
4.53E-01 29.295 31.335 28.281
4.98E-01 29.260 31.244 28.326
5.46E-01 29.377 30.790 28.100
5.99E-01 29.412 31.244 28.054
6.58E-01 29.436 31.153 28.145
7.22E-01 29.389 30.881 28.145
7.92E-01 29.377 30.336 27.873
8.70E-01 29.190 29.973 27.783
9.55E-01 28.968 29.882 27.240
1.05E+00 28.816 29.609 27.059
1.15E+00 28.862 29.064 26.561
1.26E+00 28.663 28.520 26.335
1.38E+00 28.640 28.065 25.928
1.52E+00 28.546 27.520 25.928
1.67E+00 28.500 27.430 25.701
1.83E+00 28.265 27.339 25.339
2.01E+00 27.926 26.794 25.204
2.21E+00 27.938 26.431 24.887
2.42E+00 27.961 26.703 24.615
2.66E+00 27.891 26.703 24.525
2.92E+00 27.680 26.431 24.208
3.20E+00 27.680 26.158 23.846
3.51E+00 27.575 25.704 23.846
3.85E+00 27.551 25.704 23.665
4.23E+00 27.446 25.522 23.620
4.64E+00 27.353 25.522 23.394
5.09E+00 27.353 25.522 23.213
5.59E+00 27.317 25.704 23.122
6.14E+00 27.306 25.704 23.122
6.73E+00 27.271 25.704 23.122
7.39E+00 27.247 25.522 23.122
8.11E+00 27.247 25.522 23.122
8.90E+00 27.235 25.522 23.122
9.77E+00 27.247 25.522 23.077
1.07E+01 27.235 25.522 23.077
1.18E+01 27.235 25.522 23.077
1.29E+01 27.235 25.522 23.077
1.42E+01 27.235 25.522 23.077
1.56E+01 27.235 25.522 23.032
1.71E+01 27.235 25.522 23.032
1.87E+01 27.235 25.522 23.032
2.06E+01 27.235 25.522 23.032
2.26E+01 27.235 25.522 23.032
2.48E+01 27.235 25.522 23.032
2.72E+01 27.235 25.522 23.032
2.98E+01 27.247 25.522 23.032
3.27E+01 27.247 25.522 23.032
3.59E+01 27.247 25.522 23.032
3.94E+01 27.247 25.522 23.032
4.33E+01 27.247 25.522 23.032
4.75E+01 27.247 25.522 23.032
5.21E+01 27.247 25.522 23.032
5.72E+01 27.247 25.522 23.032
6.28E+01 27.247 25.522 23.032
6.89E+01 27.247 25.522 23.032
7.56E+01 27.247 25.522 23.032
8.30E+01 27.247 25.522 23.032
9.11E+01 27.247 25.522 23.032
1.00E+02 27.247 25.522 23.032
Best regularization value: 7.74E-02
Test accuracy (%): 30.045249对于pretrained而言:
=== Recap ===
Reg Train Dev Test
1.00E-02 39.923 36.331 37.195
1.10E-02 39.934 36.331 37.195
1.20E-02 39.911 36.240 37.195
1.32E-02 39.899 36.240 37.195
1.45E-02 39.899 36.421 37.285
1.59E-02 39.888 36.694 37.285
1.75E-02 39.876 36.603 37.240
1.92E-02 39.841 36.603 37.195
2.10E-02 39.853 36.694 37.285
2.31E-02 39.864 36.421 37.240
2.54E-02 39.864 36.421 37.421
2.78E-02 39.853 36.331 37.285
3.05E-02 39.853 36.421 37.376
3.35E-02 39.876 36.421 37.466
3.68E-02 39.841 36.331 37.511
4.04E-02 39.817 36.331 37.511
4.43E-02 39.829 36.331 37.466
4.86E-02 39.923 36.240 37.511
5.34E-02 39.888 36.240 37.466
5.86E-02 39.853 36.331 37.421
6.43E-02 39.876 36.331 37.330
7.05E-02 39.864 36.331 37.195
7.74E-02 39.864 36.421 37.195
8.50E-02 39.864 36.331 37.240
9.33E-02 39.853 36.331 37.195
1.02E-01 39.817 36.240 37.149
1.12E-01 39.735 36.240 37.195
1.23E-01 39.771 36.512 37.285
1.35E-01 39.735 36.512 37.466
1.48E-01 39.794 36.512 37.511
1.63E-01 39.806 36.512 37.466
1.79E-01 39.841 36.421 37.376
1.96E-01 39.747 36.421 37.330
2.15E-01 39.724 36.512 37.240
2.36E-01 39.665 36.512 37.195
2.60E-01 39.654 36.512 37.195
2.85E-01 39.560 36.421 37.330
3.13E-01 39.583 36.240 37.285
3.43E-01 39.642 36.240 37.285
3.76E-01 39.630 36.331 37.285
4.13E-01 39.630 36.331 37.285
4.53E-01 39.607 36.149 37.330
4.98E-01 39.618 36.149 37.330
5.46E-01 39.583 36.149 37.330
5.99E-01 39.583 36.149 37.285
6.58E-01 39.607 36.421 37.240
7.22E-01 39.548 36.512 37.285
7.92E-01 39.537 36.512 37.285
8.70E-01 39.525 36.603 37.376
9.55E-01 39.525 36.603 37.285
1.05E+00 39.478 36.512 37.330
1.15E+00 39.525 36.603 37.285
1.26E+00 39.537 36.512 37.330
1.38E+00 39.548 36.512 37.330
1.52E+00 39.490 36.512 37.285
1.67E+00 39.490 36.603 37.059
1.83E+00 39.466 36.694 37.195
2.01E+00 39.501 36.876 37.240
2.21E+00 39.431 36.694 37.240
2.42E+00 39.408 36.603 37.240
2.66E+00 39.302 36.876 37.195
2.92E+00 39.279 36.876 37.195
3.20E+00 39.197 36.966 37.104
3.51E+00 39.022 36.876 37.240
3.85E+00 39.115 36.694 37.285
4.23E+00 39.092 36.785 37.376
4.64E+00 39.010 36.876 37.285
5.09E+00 38.963 36.694 37.376
5.59E+00 39.010 36.512 37.466
6.14E+00 38.951 36.785 37.466
6.73E+00 38.928 36.876 37.783
7.39E+00 38.893 36.785 37.828
8.11E+00 38.846 36.694 37.828
8.90E+00 38.729 36.694 37.828
9.77E+00 38.647 36.876 37.738
1.07E+01 38.706 36.876 37.466
1.18E+01 38.659 37.239 37.511
1.29E+01 38.542 37.057 37.421
1.42E+01 38.448 36.876 37.330
1.56E+01 38.343 36.694 37.149
1.71E+01 38.319 36.966 37.240
1.87E+01 38.191 36.694 37.149
2.06E+01 38.191 36.603 37.059
2.26E+01 38.003 36.421 36.968
2.48E+01 37.863 36.331 36.833
2.72E+01 37.746 36.694 36.923
2.98E+01 37.617 36.966 36.697
3.27E+01 37.500 36.876 36.471
3.59E+01 37.512 36.785 36.290
3.94E+01 37.477 36.603 36.425
4.33E+01 37.383 36.512 36.244
4.75E+01 37.161 36.512 36.199
5.21E+01 37.125 36.421 36.290
5.72E+01 36.997 36.149 36.063
6.28E+01 36.821 35.786 36.154
6.89E+01 36.809 35.695 36.018
7.56E+01 36.610 35.876 35.882
8.30E+01 36.575 35.332 35.611
9.11E+01 36.482 34.968 35.656
1.00E+02 36.330 35.059 35.701
Best regularization value: 1.18E+01
Test accuracy (%): 37.511312对于Glove比自己训练的词向量性能更好的原因:
1,因为Glove使用的维度更高,使用的是50维,而我们自己训练的词向量是10维。
2,训练GLove时采用的是很大的语料库,然后可以得到一个更全面的效果,而我们训练的语料库数据量不够大,不能得到无偏的词向量。
3,对于Glove而言,使用到了全局的信息,使用了词向量共现的信息,而对于Word2vec而言,使用的是上下文的局部关系。
(e)画出的不同正则化参数的训练集,验证集的准确率的情况。(采用Glove训练的)

这幅图展现的是不同的正则化系数对于训练集和验证集的准确率的影响。对于正则化系数一直增大,对于训练集的准确率一直在下降,而验证集数据有一个小范围的上升的过程,说明起到了避免过拟合训练数据的效果,而正则化系数太大,二者的准确率都很低,说明模型太简单了,导致了模型没有很好的拟合数据。
(f)画出的混淆矩阵图形如下:(使用Glove模型)

分析上面的混淆矩阵,在很消极的数据中,很多的被分为了消极,次多被分为了积极;消极的数据中,很多被分为了消极,但也有次多的被分为了积极;在中立的数据汇总,很多被分为了消极,次多被分为了积极;在积极的数据中,很多的被分为积极,少部分被分为了消极;在很积极的数据中,很多被分为了积极,次多的被分为很积极。
在我们构建的这个模型中,对于积极的数据分类效果最好,其次是消极的数据,其次是很积极的数据,中立的数据,最后是很消极的数据。
总体来看,对于积极方面的数据效果更好,对于中立和消极的数据分类效果一般。
(g)分析三条分错的数据。
数据:
True Predicted Text
3 4 it 's a lovely film with lovely performances by buy and accorsi .
2 1 no one goes unindicted here , which is probably for the best .
3 1 and if you 're not nearly moved to tears by a couple of scenes , you 've got ice water in your veins .对于第一条:
从积极的数据预测为很积极的数据。因为这二者的界限很模糊,不是将明显的积极的数据分为消极的这类严重的错误。
对于第二条:
可能否定词和不确定的词有点多,所以将其偏向了消极的观点。
对于第三条:
涉及到了反语,有一些偏消极的词,没有学习到反语的意思,出错。
解释程序:这个程序的入口程序:main函数,参数为另一个函数getArguments。
首先说,getArguments函数,这个调用了argparse包,这个包用于从python内置的一个用于命令项选项与参数解析的模块,通过在程序中定义好需要的参数,然后argparse会帮我们从sys.argv中解析出这些参数,并自动生成帮助和使用信息。这个是需要在命令行下进行运行的。
具体讲解链接:https://www.jianshu.com/p/fef2d215b91d
https://blog.csdn.net/u013177568/article/details/62432761/
我觉得我差一点就阵亡在这个地方,但我最后还是解决了这个问题。在这个地方遇到的问题是我对于那个argparse包的不熟悉,不知道该怎么运行,具体详见上面的链接。
还有一个问题,因为我是windows环境,利用命令行的时候要cd到这个文件夹下运行,否则的话会报找不到文件的错误,因为是从系统盘C盘找的,这当然找不到了。
这里再贴一个链接,https://www.cnblogs.com/wangguoyuan-09/p/6866798.html,讲的是pycharm来运行命令行程序。
其次,说的是main函数,数据集采用的是斯坦福情感分析的数据集,然后根据命令行的参数(互斥的),选择是采用pretrained,还是采用yourvectors;然后读取到数据集中的训练集,验证集和测试集,抽取数据的特征;然后验证不同的正则化参数的训练结果,然后输出结果。对于pretrained的类别,还会画出图来进行错误分析。
对于getSentenceFeatures函数,就是(a)中,利用句子的每个单词的词向量的平均来作为整个句子的特征来进行处理。
对于getRegularizationValues函数,就是(b)中,得到一系列的正则化的参数,然后对这些数据进行排序。
对于chooseBestModel函数,就是(b)中,根据验证集的准确率来选择一个好的模型。
对于accuracy函数,就是通过向量化的手段,来得到准确率的计算。
对于plotRegVsAccuracy函数,就是通过画出正则化参数以及准确率的变化的曲线的函数。
对于outputConfusionMatrix是用来画出混淆矩阵的函数。
在这个地方有比较多的学习的地方:
1)对于混淆矩阵的画法,不是仅仅得到一个矩阵就OK, 也是可以画出图像的,很美观。
2)自己有很多可以借鉴的地方
贴出matplotlib官网的链接以便后续查看:https://matplotlib.org/api/pyplot_summary.html
对于outputPredictions是用来输出一个txt文档,里面记录了验证集数据的真实的标签,预测的标签,以及数据。
最后的程序实现如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import argparse
import numpy as np
import matplotlib
matplotlib.use('agg')
import matplotlib.pyplot as plt
import itertools
from utils.treebank import StanfordSentiment
import utils.glove as glove
from q3_sgd import load_saved_params, sgd
# We will use sklearn here because it will run faster than implementing
# ourselves. However, for other parts of this assignment you must implement
# the functions yourself!
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
def getArguments():
parser = argparse.ArgumentParser()
group = parser.add_mutually_exclusive_group(required=True)
group.add_argument("--pretrained", dest="pretrained", action="store_true",
help="Use pretrained GloVe vectors.")
group.add_argument("--yourvectors", dest="yourvectors", action="store_true",
help="Use your vectors from q3.")
return parser.parse_args()
def getSentenceFeatures(tokens, wordVectors, sentence):
"""
Obtain the sentence feature for sentiment analysis by averaging its
word vectors
"""
# Implement computation for the sentence features given a sentence.
# Inputs:
# tokens -- a dictionary that maps words to their indices in
# the word vector list
# wordVectors -- word vectors (each row) for all tokens
# sentence -- a list of words in the sentence of interest
# Output:
# - sentVector: feature vector for the sentence
sentVector = np.zeros((wordVectors.shape[1],))
for word in sentence:
sentVector += wordVectors[tokens[word]]
sentVector *= 1.0/len(sentence)
assert sentVector.shape == (wordVectors.shape[1],)
return sentVector
def getRegularizationValues():
"""Try different regularizations
Return a sorted list of values to try.
"""
# Assign a list of floats in the block below
values = np.logspace(-2, 2, num=100, base=10)
return sorted(values)
def chooseBestModel(results):
"""Choose the best model based on dev set performance.
Arguments:
results -- A list of python dictionaries of the following format:
{
"reg": regularization,
"clf": classifier,
"train": trainAccuracy,
"dev": devAccuracy,
"test": testAccuracy
}
Each dictionary represents the performance of one model.
Returns:
Your chosen result dictionary.
"""
# 对于利用dev的关键字来进行排序
bestResult = max(results, key=lambda x: x['dev'])
return bestResult
def accuracy(y, yhat):
""" Precision for classifier """
assert(y.shape == yhat.shape)
return np.sum(y == yhat) * 100.0 / y.size
def plotRegVsAccuracy(regValues, results, filename):
""" Make a plot of regularization vs accuracy """
plt.plot(regValues, [x["train"] for x in results])
plt.plot(regValues, [x["dev"] for x in results])
plt.xscale('log')
plt.xlabel("regularization")
plt.ylabel("accuracy")
plt.legend(['train', 'dev'], loc='upper left')
plt.savefig(filename)
def outputConfusionMatrix(features, labels, clf, filename):
""" Generate a confusion matrix """
pred = clf.predict(features)
cm = confusion_matrix(labels, pred, labels=range(5))
plt.figure()
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Reds)
plt.colorbar()
classes = ["- -", "-", "neut", "+", "+ +"]
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.savefig(filename)
def outputPredictions(dataset, features, labels, clf, filename):
""" Write the predictions to file """
pred = clf.predict(features)
with open(filename, "w") as f:
print >> f, "True\tPredicted\tText"
for i in xrange(len(dataset)):
print >> f, "%d\t%d\t%s" % (
labels[i], pred[i], " ".join(dataset[i][0]))
def main(args):
""" Train a model to do sentiment analyis"""
# Load the dataset
dataset = StanfordSentiment()
tokens = dataset.tokens()
nWords = len(tokens)
if args.yourvectors:
_, wordVectors, _ = load_saved_params()
wordVectors = np.concatenate(
(wordVectors[:nWords,:], wordVectors[nWords:,:]),
axis=1)
elif args.pretrained:
wordVectors = glove.loadWordVectors(tokens)
dimVectors = wordVectors.shape[1]
# Load the train set
trainset = dataset.getTrainSentences()
nTrain = len(trainset)
trainFeatures = np.zeros((nTrain, dimVectors))
trainLabels = np.zeros((nTrain,), dtype=np.int32)
for i in xrange(nTrain):
words, trainLabels[i] = trainset[i]
trainFeatures[i, :] = getSentenceFeatures(tokens, wordVectors, words)
# Prepare dev set features
devset = dataset.getDevSentences()
nDev = len(devset)
devFeatures = np.zeros((nDev, dimVectors))
devLabels = np.zeros((nDev,), dtype=np.int32)
for i in xrange(nDev):
words, devLabels[i] = devset[i]
devFeatures[i, :] = getSentenceFeatures(tokens, wordVectors, words)
# Prepare test set features
testset = dataset.getTestSentences()
nTest = len(testset)
testFeatures = np.zeros((nTest, dimVectors))
testLabels = np.zeros((nTest,), dtype=np.int32)
for i in xrange(nTest):
words, testLabels[i] = testset[i]
testFeatures[i, :] = getSentenceFeatures(tokens, wordVectors, words)
# We will save our results from each run
results = []
regValues = getRegularizationValues()
for reg in regValues:
print "Training for reg=%f" % reg
# Note: add a very small number to regularization to please the library
clf = LogisticRegression(C=1.0/(reg + 1e-12))
clf.fit(trainFeatures, trainLabels)
# Test on train set
pred = clf.predict(trainFeatures)
trainAccuracy = accuracy(trainLabels, pred)
print "Train accuracy (%%): %f" % trainAccuracy
# Test on dev set
pred = clf.predict(devFeatures)
devAccuracy = accuracy(devLabels, pred)
print "Dev accuracy (%%): %f" % devAccuracy
# Test on test set
# Note: always running on test is poor style. Typically, you should
# do this only after validation.
pred = clf.predict(testFeatures)
testAccuracy = accuracy(testLabels, pred)
print "Test accuracy (%%): %f" % testAccuracy
results.append({
"reg": reg,
"clf": clf,
"train": trainAccuracy,
"dev": devAccuracy,
"test": testAccuracy})
# Print the accuracies
print ""
print "=== Recap ==="
print "Reg\t\tTrain\tDev\tTest"
for result in results:
print "%.2E\t%.3f\t%.3f\t%.3f" % (
result["reg"],
result["train"],
result["dev"],
result["test"])
print ""
bestResult = chooseBestModel(results)
print "Best regularization value: %0.2E" % bestResult["reg"]
print "Test accuracy (%%): %f" % bestResult["test"]
# do some error analysis
if args.pretrained:
plotRegVsAccuracy(regValues, results, "q4_reg_v_acc.png")
outputConfusionMatrix(devFeatures, devLabels, bestResult["clf"],
"q4_dev_conf.png")
outputPredictions(devset, devFeatures, devLabels, bestResult["clf"],
"q4_dev_pred.txt")
if __name__ == "__main__":
main(getArguments())