Lecture 3: More Word Vectors
gigantic 巨大
co-occurrence 共同出现的
Linear Algebraic Structure of Word Senses, with Applications to Polysemy
这节课更加深入地讲述了词向量,主要分为
3.1 词向量的一些技巧和深入说明
- 关于上节课计算梯度时用到的“链式法则”,老师说,神经网络中的反向传播,实际上就是带存储的链式法则。
- 真正对skip-gram模型有意义的不是单词在文本中的位置,而是单词在窗口中的位置
- 优化时采用SGD不仅有速度快的优势,还有一个优势:神经网络喜欢噪音,而粗糙的SGD反而会成为一种更好的优化算法。
- 词向量初始化时,一般是选择较小的随机数。是在两个较小的数的范围内均匀采样得到的初始化词向量。
- 由于我们的目标函数通常是非凸的,初始化点的选取十分重要,后面会提到一些经验和技巧。
- 当我们在使用梯度下降优化
时,由于每个windows我们至多有
个词,但是我们是对整个
也就是
个词向量进行更新的,这就造成了
非常的稀疏!
- 有两种解决方式。一:对整个嵌入矩阵只更新相关的列(额外记录那些列的索引)
- 使用哈西散列
接下来是关于作业一的一些建议:
- 更新所有的权重/归一化因子过于消耗计算成本,所以在作业一中建议采用**负采样(negative sampling)**的方法实现skip-gram模型。
负采样的基本思想是:
train binary logistic regressions for a true pair(center word and word in its context window) versus a couple of noise pairs(the center word paired with a random word)
就是说每次 并非更新所有词向量,而是训练一对true pair和 对noise pairs。True pair即真实的语料库中中心词和语境词对,noise pairs是中心词和随机选取的词对。可以看到下图的目标函数 ,第一项是对true pair进行内积然后取它的sigmoid函数变为概率,再取对数,我们希望第二项的概率尽可能大;第二项是随机噪声对,我们对这 对噪声对先取负值,然后sigmoid一下,再取log,再求和。我们希望最大化这个 。

如何随机采样呢?这个
一般是个均匀分布,可以看到下图的
公式。

除了skip-gram,Word2Vec还有一个经典的模型叫CBOW。这个模型主要是根据语境词向量的sum来预测中心词。

- Word2Vec通过将相似的词放在相近的位置来优化目标函数。Word2Vec本身就是会抓取词的相似点,和词与词之间共现(共同出现)的频率。
既然Word2Vec会捕捉词之间的共现频率,我们为什么不直接捕捉词之间共现的count(计数)呢?
3.2 词的共现矩阵
上一节的问题答案是肯定的。解决方法就是使用共现矩阵,实际上共现矩阵出现的要比词向量还要早。
有两种实现共现矩阵的方式:
- 基于窗口的共现矩阵:类似Word2Vec,对每个中心词,计数窗口中的语境词的数量(可能会同时捕捉句法和语法信息)。
- 基于文档的共现矩阵:对每个文档进行词语的计数,多用在“潜在语义分析(LSA)”中。
这里举一个简单的基于窗口共现矩阵的例子。
- 例中窗口长度为1(实践中一般为5-10)
- 例中矩阵是对称的(语境词在中心词的左边还是右边不影响最终结果)
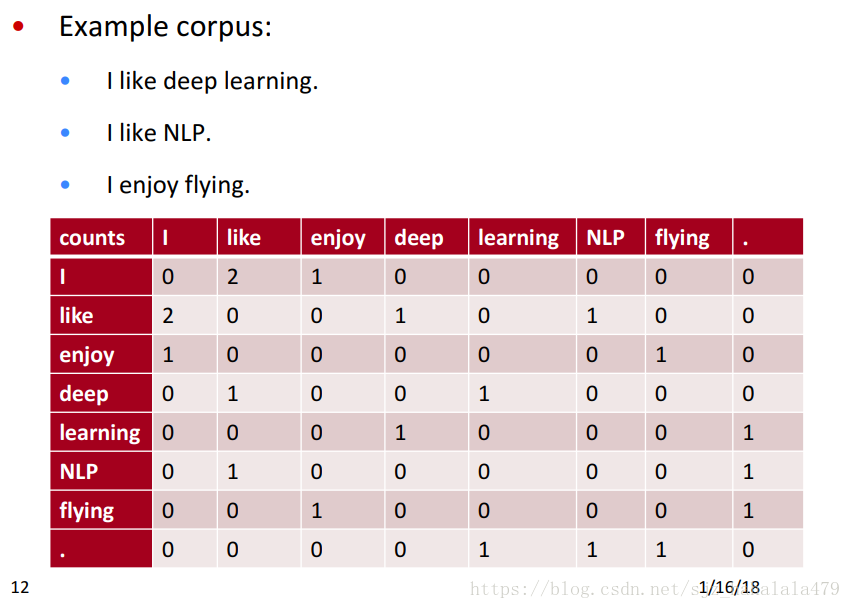
上图是个简单的共现矩阵例子。但是共现矩阵也是存在问题的:
- 矩阵的规模会随着词的增加而扩大。高维矩阵十分耗内存。使用共现矩阵之后的分类模型就会遇到稀疏的问题。从而影响鲁棒性。
解决方式就是降维!我们只保存矩阵中重要的信息,将重要的信息压缩到一个固定的,较小的维度中。数学上有一个经典的降维方法:SVD分解!!
奇异值分解 SVD
有几篇不错的博文讲SVD讲的很好,本文就不做赘述了:
可以跟着这篇做svd的推导
这篇对svd理解更加抽象一些

SVD有numpy函数可以直接使用,这里举一个刚刚例子的python代码:
import numpy as np
la = np.linalg
words = ['I','like','enjoy','deep','learning','nlp','flying','.']
X = np.array([
[0,2,1,0,0,0,0,0],
[2,0,0,1,0,1,0,0],
[1,0,0,0,0,0,1,0],
[0,1,0,0,1,0,0,0],
[0,0,0,1,0,0,0,1],
[0,1,0,0,0,0,0,1],
[0,0,1,0,0,0,0,1],
[0,0,0,0,1,1,1,0]
])
U,S,Vh = la.svd(X,full_matrices=False)
#选择U中最大的前两个奇异值画图
import matplotlib.pyplot as plt
for i in range(len(words)):
plt.text(U[i,0],U[i,1],words[i])
关于降维,还有一些优化技巧:
- 对于the\has\he这种没有实际意义但出现次数又很高的虚词,可以限制它的最大count,或者直接忽略它们
- 根据语境词与中心词距离的远近,赋予count不同的权重。比如和中心词最相邻的count我们记为1,隔大概5个位置的count我们记为0.5。
- 使用Pearson相关而非count,然后将赋值设为0
- …
当然还有其它优化共现矩阵的方法,比如下面这篇论文
An Improved Model of Semantic Similarity Based on Lexical Co-Occurrence
Rohde et al. 2005
SVD奇异值分解还是存在问题的:
- 计算百万级的文档的SVD矩阵还是很耗计算的;
- 不好扩展(新的词/文档不好加入)
- 和其它DL学习方式不同
3.3 Glove 模型
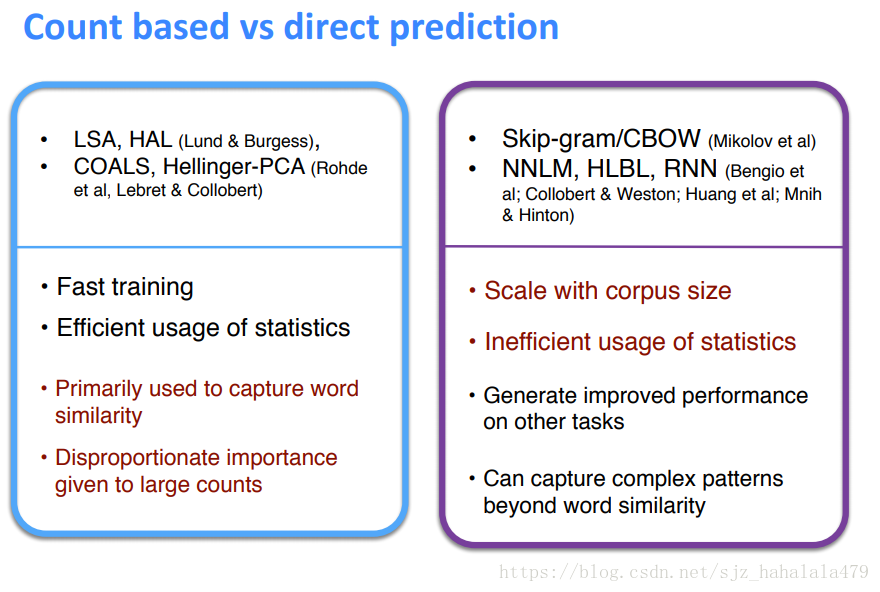
基于计数的词表示方法:训练的速度快;可以有效的使用统计数据;主要用于捕捉词的相似性;有个问题在于有些词的计数值和其重要性不成比例
直接预测的方法:训练速度会随着语料库的大小而伸缩;不能有效使用统计数据;可能会捕捉到一些词相似性外的复杂模式。
有没有一种模型,可以结合两类方法的优点呢?14年Pennington, Socher, Manning 提出了Glove模型。
Glove的目标函数如下:


3.4 词向量的评估
如何去评估词向量的好坏呢?有两种方式,一种内部的,一种外部的。

内部评估一般采用词向量类比的方式。