学习笔记:cs224n7
学习视频:cs224n7
学习课件:cs224n7
这节课开始,就涉及到了我最弱的那部分了。但慢慢来,跨过这个坎,说不定就变成我最强的能力了。
一,什么是深度学习框架
简单来说,就是有标准的模板,里面有各种好用的模板,可以快速上手,然后也可以方便交流。尤其对于梯度的计算,真的是方便,不用人每天纠结于导数的数学之中,把人解放出来,能够更好的集中于问题的解决,站在巨人的肩膀上,可以更好的干活。
常见的深度学习框架:https://www.cnblogs.com/xinbaby829/p/6949777.html
1,tensorflow, 图计算的开源类库, 使用数据流图进行数值计算的开源软件库,可以自动的计算梯度,是一个很底层的软件库, 可以提供GPU,CPU的接口。
2,Theano,比较底层的库,更适合于做数值计算的优化,也可以自动计算梯度, 但不提供GPU计算。
3,Keras,更上层的一个库,使用更加简洁方便。可以工作在Theano和tensorflow之上。
4,Lasagne,与Keras类似,建立在Theano之上。但发展没有Keras好。
5,Caffe, 主要关注与计算机视觉之中,不够灵活,文档比较少,安装比较困难,但caffe的文档比较匮乏,所以,上手会相对慢很多。
6,DSSTNE,封装好的,只做推荐系统的库。
7,Torch, 主要是基于Lua语言的,这与深度学习流行语言的的大趋势不同,肯定还是限制了其发展。
8,MXNet, 多GPU扩展能力。
9,DL4J, 文档写的极其好,兼容JVM。
10,Cognitive Toolkit, 与Keras类似,但没有激起很多水花。
二,图计算编程模型
将数值计算以图的形式描述。
图的节点,表示某种运算,支持任意数量的输入和输出。
图的边是张量(tensor),也可以说是高维矩阵, 在节点之间流动。
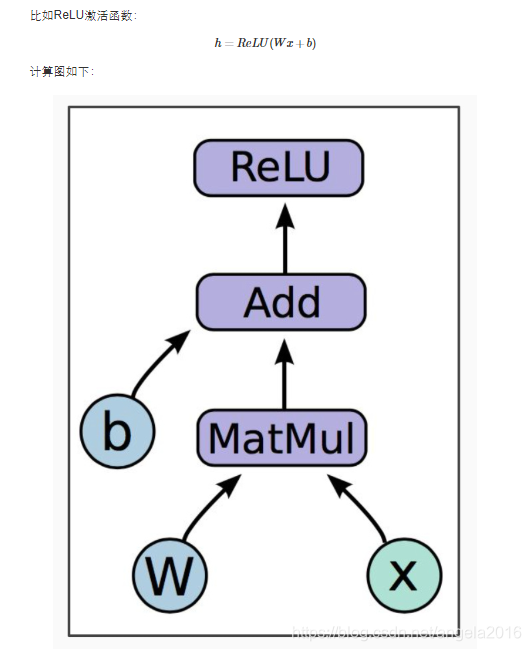
在上图中,W,b为变量,是模型的参数,变量可以存储下来,作为模型的一部分发布。x为占位符(placeholder), 只有在执行的时候填充输入数据,编程的时候指定大小即可,真是运行执行才有真正的数据。

上述的代码。真实的含义,是搭建一个框架,然后只是描述一些图的意思。不能够执行,如果需要执行,需要通过绑定到某个软硬件执行环境中。(session到CPU, GPU, Google的TensorProcessingUnit之上)。

第一个run是初始化所有的变量,第二个run初始化占位符,也就是给定输入数据。
三,如何训练一个模型
上面其实就是定义一个图,那么定义好一个图之后,我们前向推导,需要知道损失函数,后向推导,我们需要进行梯度下降等。

![]()
这样前向,后向传播操作都定义好了,下一步就是绑定就行了。

四, 总结
1,创建图,然后前向传播,后向传播弄好。
2,初始化session
3,在session中执行