9. 自注意力和 Transformer
参考另外一篇文章:Attention机制详解
讲座计划
\1. 从循环(RNN)到基于注意力的 NLP 模型
\2. 介绍 Transformer 模型
\3. Transformer 的好结果
\4. Transformer 的缺点和变体
9.1.从 RNN 到基于注意力的 NLP 模型
9.1.1. 基于注意力 RNN 模型
截至到上周:(大多数)NLP 都是循环(RNN)模型!
2016 年,NLP 中的事实上的策略是:
首先,使用双向 LSTM 对句子进行编码(例如,翻译中的源句子),见图 9.1(a);
然后,把输出定义为一个序列(例如,翻译的目标句子),并使用 LSTM 生成(解码)它,见图 9.1(b);
最后,使用注意力以便允许灵活地访问记忆(Memory,即编码的隐藏状态),见图 9.1©。
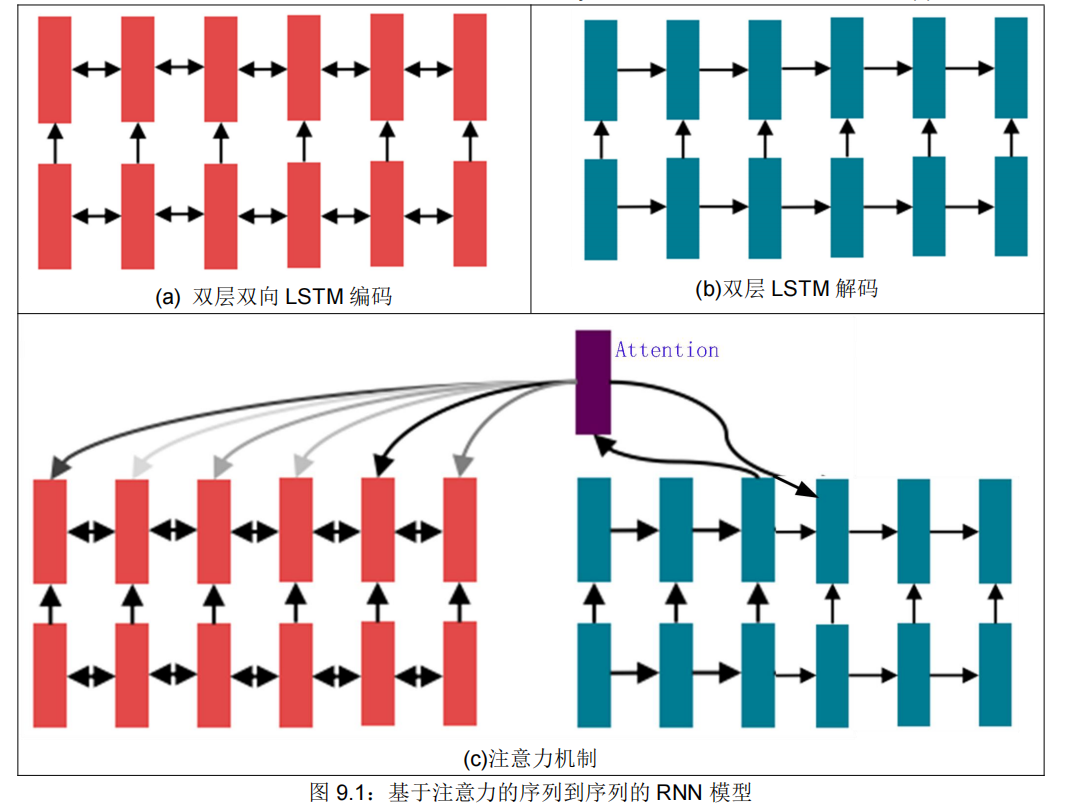
以上就是一个具有 2014~2017 年代特征的 RNN 模型。经过大量的试验和错误后,2021 年的今天,情况怎么样呢?
今天,我们可以用不同的模块,实现相同的目标!
今天,我们并没有试图激发全新的看待问题的方式(例如机器翻译),相反,我们正在努力寻找最好的构建模块来插入我们的模型并实现广泛的进展。
9.1.2. RNN 循环模型的问题
9.1.2.1. 线性交互距离
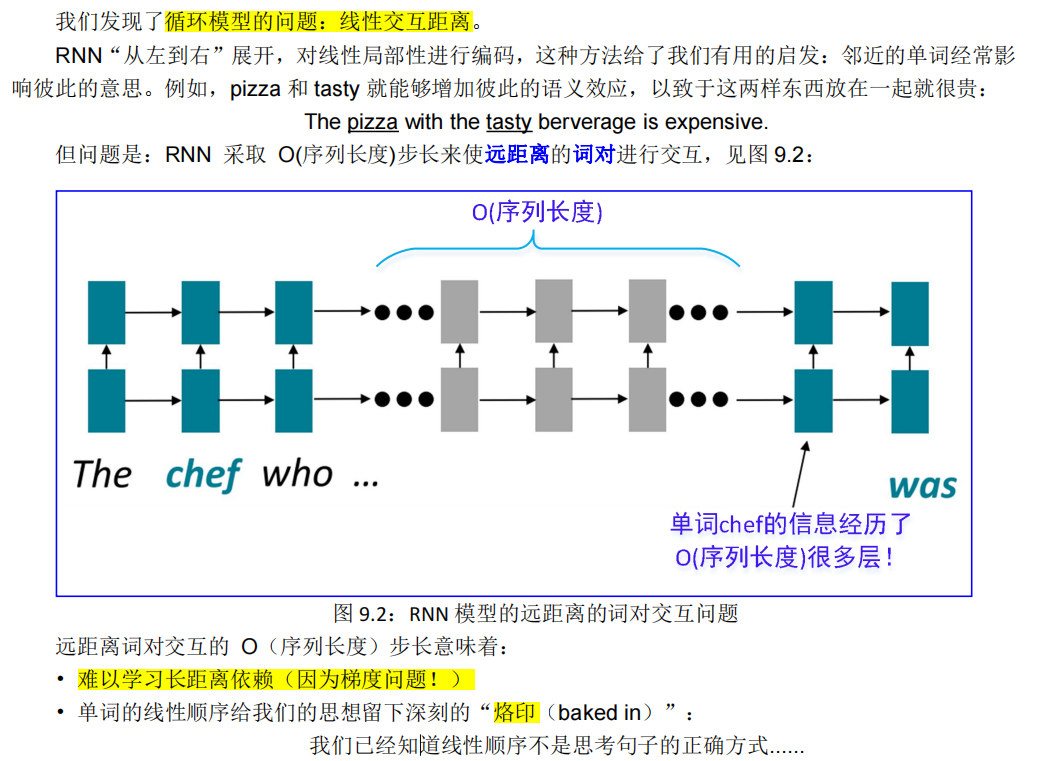
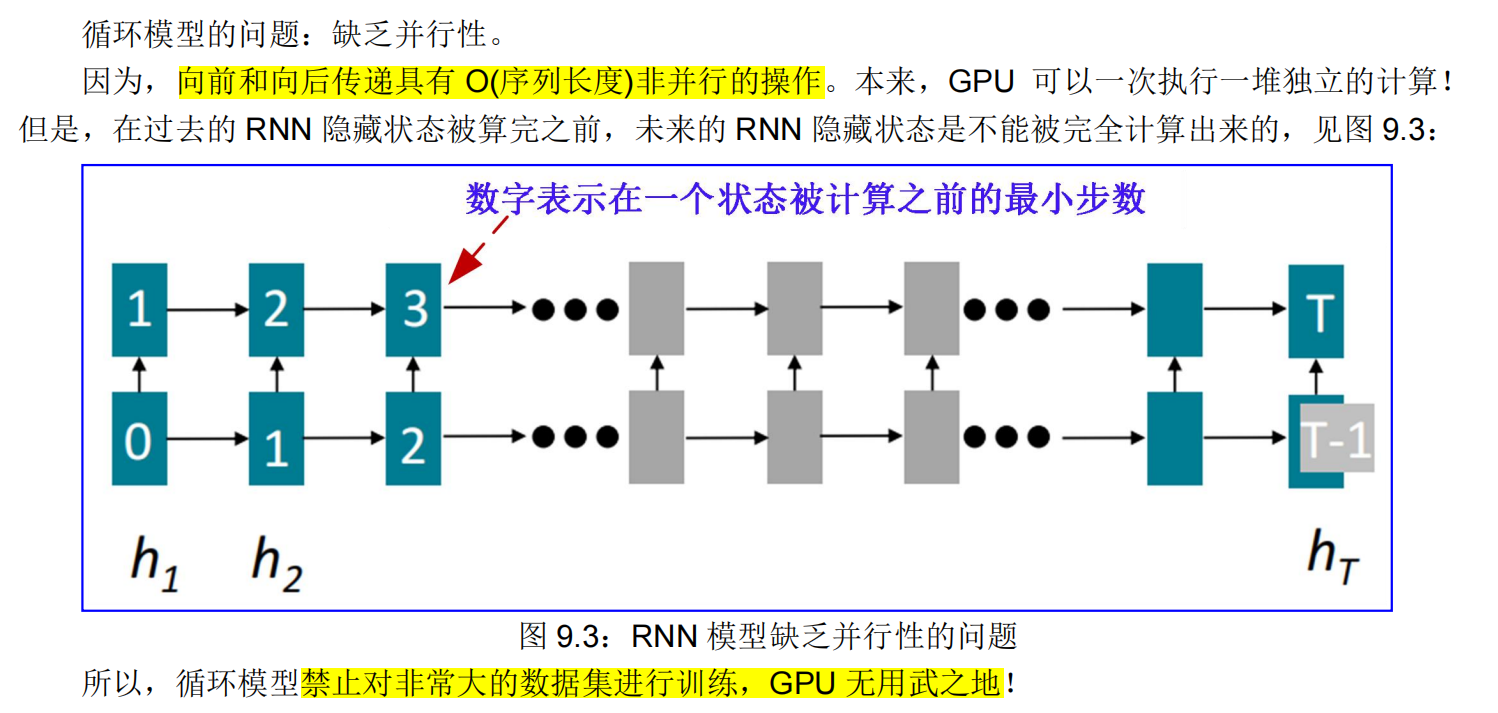
9.1.2.2. 缺乏并行性
9.1.3. 单词窗口
如果不是循环,那又是什么?单词窗口怎么样?
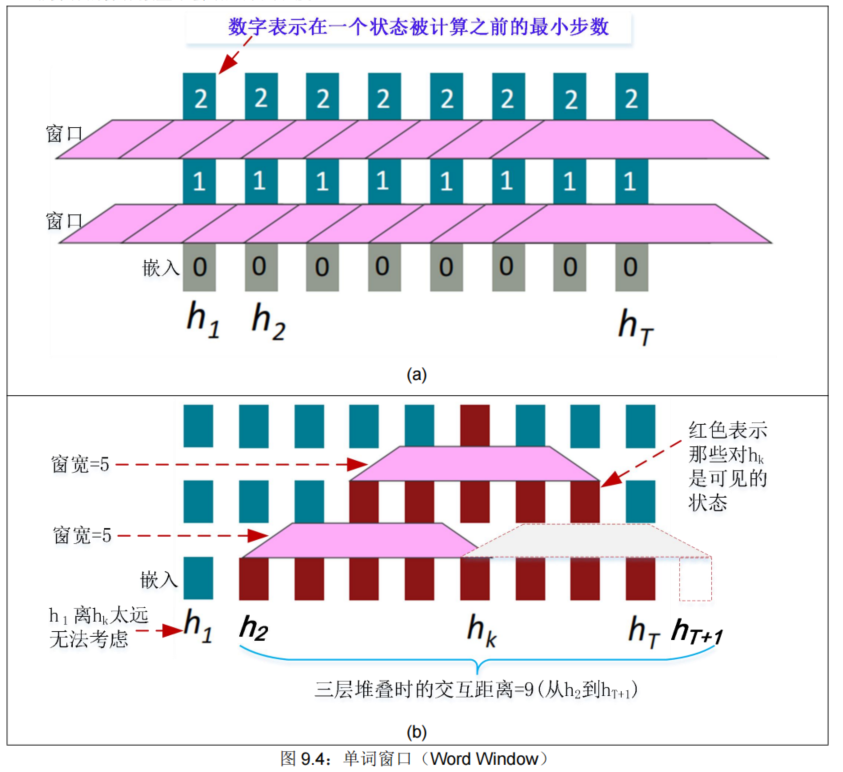
• Word 窗口模型聚合本地上下文(也称为 1D 卷积;我们稍后会深入讨论),见图 9.4(a)。
• 非并行的操作数量不会增加序列长度!
那么,单词窗口的长距离依赖情况如何呢?
• 堆叠单词窗口层允许更远单词之间的交互,见图 9.4(b)。
• 最大交互距离 = 序列长度 / 窗口大小(但如果你的序列太长,你就会忽略长距离上下文)。
9.1.4. 注意力
如果不是循环,那又是什么? 注意力怎么样?
• 注意力将每个单词的表示视为:一个查询(Q)去访问和合并来自一组值(V)的信息。
• 我们从上一章已经看到了从解码器到编码器的注意力;今天我们将在单独一个句子内来考虑注意力。
• 不可并行操作的数量不会增加序列长度。
• 最大交互距离:O(1),因为所有单词在每一层都交互,见图 9.5:
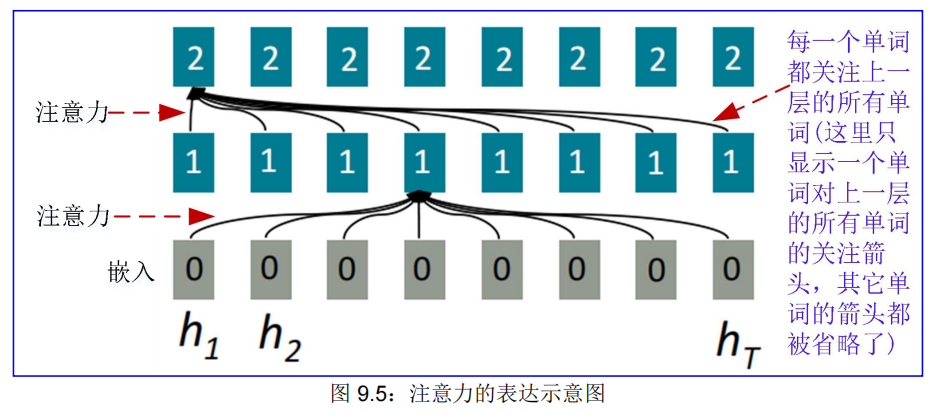
9.1.5. 自注意力★★

参考:
9.1.5.1. 位置问题的方案:序列顺序编码★
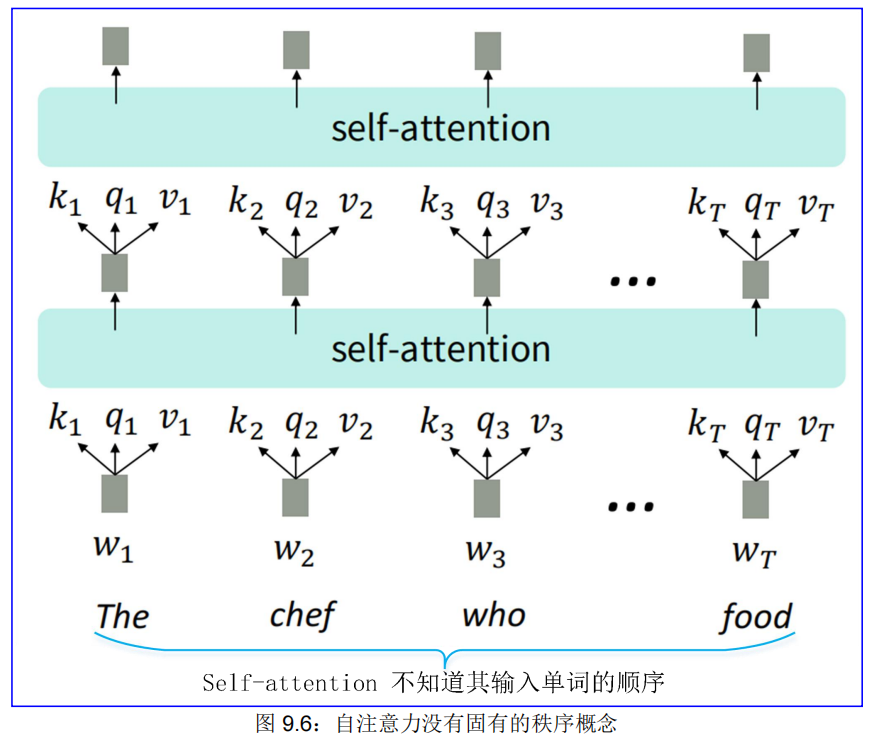
第一个障碍:位置问题。
自注意力是对集合的操作,它没有固有的顺序概念,即它不知道其输入的位置,见图 9.6:
(1)修复第一个 self-attention 问题:序列顺序

在深度自注意力网络中,我们在第一层就这样做!你可以也将它们连接起来,但人们大多只是添加…
-
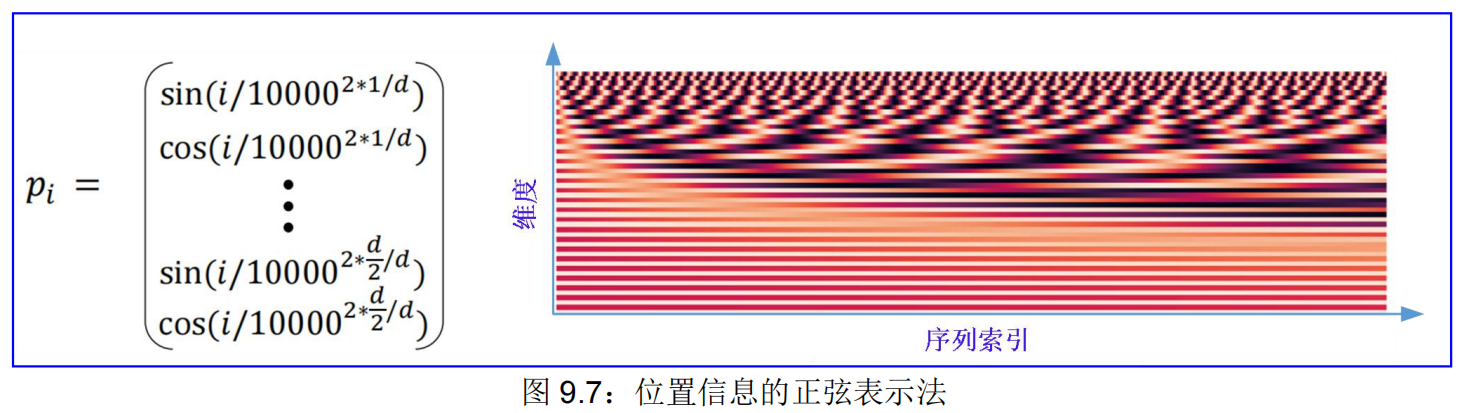
解决方案:通过正弦和余弦曲线,把位置表示为向量。
- 正弦位置表示:连接不同周期的正弦函数,见图 9.7:
- 优点:周期性表明“绝对位置”可能不那么重要,也许可以在周期重新开始时推断出更长的序列!
- 缺点:不可学习;推断也不起作用!注意,位置编码是写死的,不会更新,没有可训练学习的参数。
- 正弦位置表示:连接不同周期的正弦函数,见图 9.7:
-
所以,要从头开始学习(learned from scratch)位置表示的向量。
-
学习的绝对位置表示:让所有pi成为可学习的参数!
-
学习一个矩阵 p ∈ R d×T,并让每个pi成为该矩阵的一列!
优点:灵活性:学习每个位置以适应数据
缺点:肯定(definitely)不能外推到 1,…,T 之外的索引。
大多数系统都使用它!
有时人们会尝试更灵活的位置表示:
相对线性位置注意力,参见[Shaw et al., 2018];
基于依存句法的位置,参见[Wang et al., 2019]。
-
-
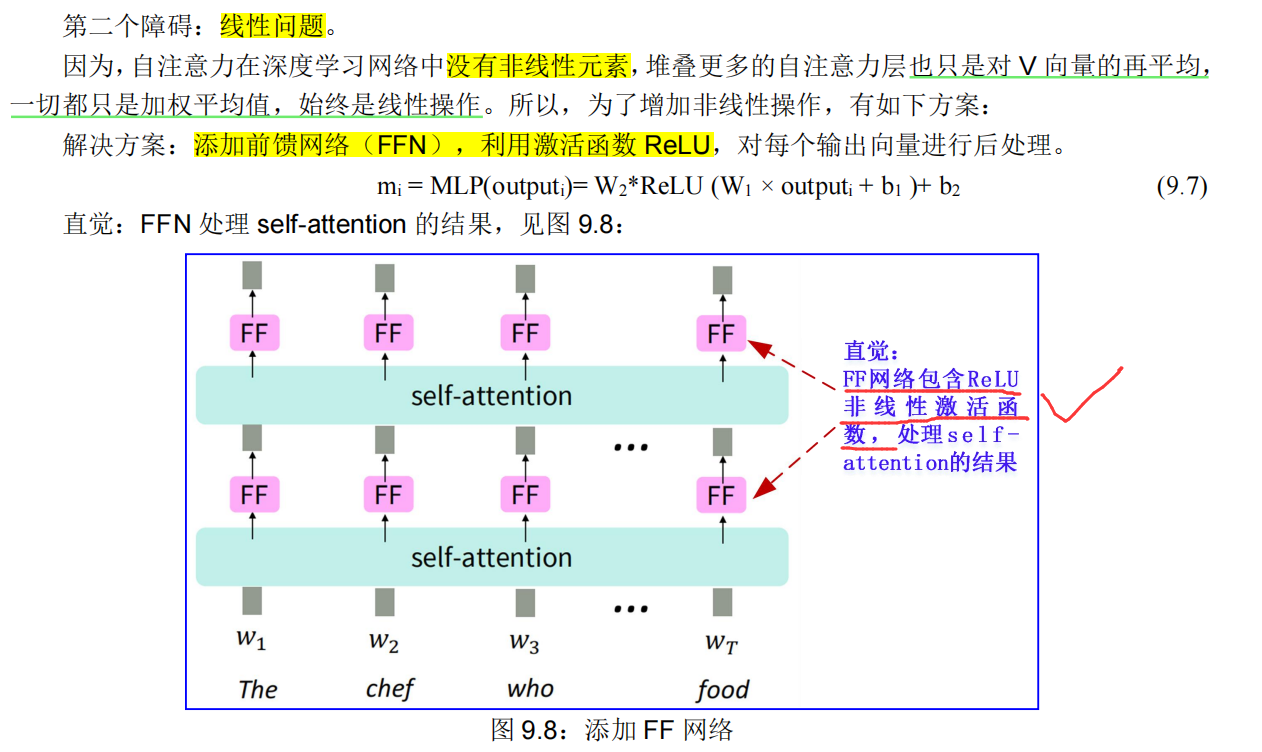
9.1.5.2. 线性问题的方案:非线性激活函数★
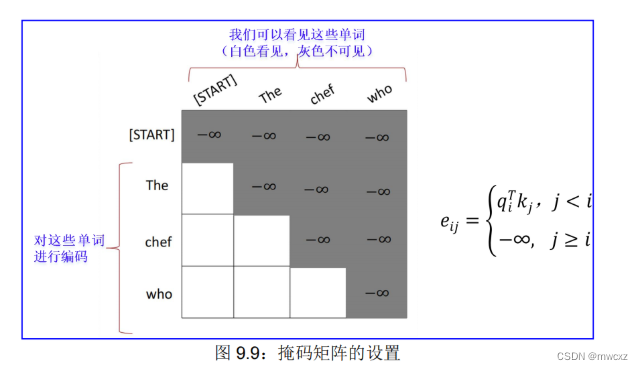
9.1.5.3. 预测问题的方案:掩码矩阵★
掩码:为了在不看未来的情况下并行化操作,防止有关未来的信息“泄漏”到过去(不能偷看未来)。

9.1.6. 小结
位置问题的解决方案:向输入添加位置表示。 pi
线性问题的解决方案:对每个自注意力输出应用相同的前馈网络。
预测问题的解决方案:通过人为地将注意力权重设置为 0 来掩盖未来!
自注意力构建块的必要性:
• 自注意力:Transformer 方法的基础。
• 位置表示:指定序列顺序,因为自注意力是其输入的一个无序函数。
• 非线性(ReLU):在自注意力模块的输出,经常作为简单的前馈网络(FFN)实施。
• 掩码:为了在不看未来的情况下并行化操作,防止有关未来的信息“泄漏”到过去(不能偷看未来)。
自注意力就是这些要点! 但这不是我们一直听说的 Transformer 模型。
9.2.Transformer 的详细解读
9.2.1. Transformer 多级视图
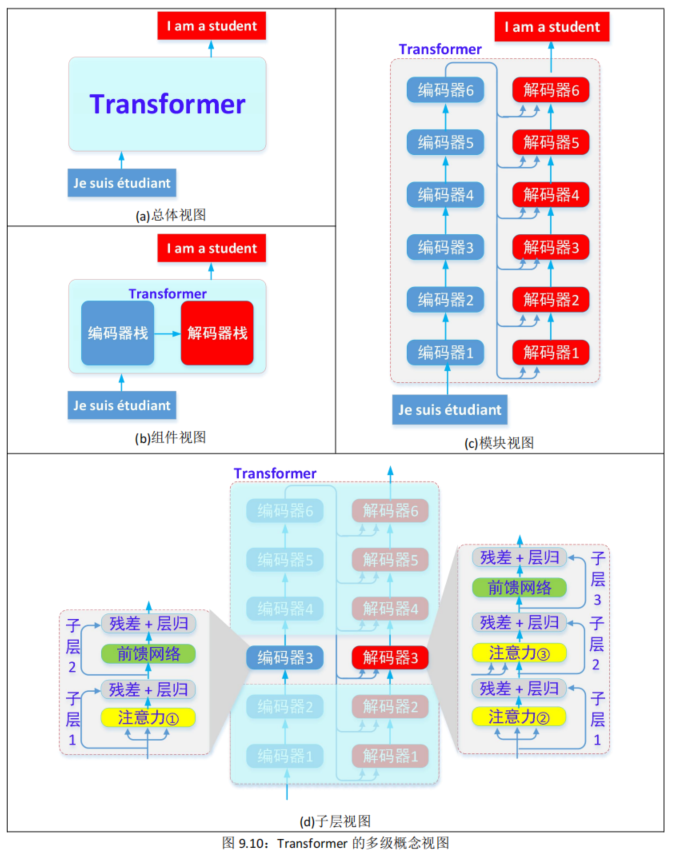
总体视图:Transformer 模型可被视为单个黑匣子。在机器翻译应用程序中,它会用一种语言输入一个句子,然后用另一种语言输出它的翻译,见图 9.10(a)。
组件视图:Transformer 由一个编码器组件(堆栈)、一个解码器组件(堆栈)及其连接组成,见图 9.10(b)。
模块视图:编码器栈是由 6 个编码器模块组成,解码器栈也是由 6 个解码器模块组成(数字 6 没有什么神奇之处,人们可以根据需要增减),见图 9.10©。
子层视图: 每个编码器模块包括两个子层:
子层 1:包括:注意力①、(残差+层归一化);
子层 2:包括:前馈网络、(残差+层归一化);
每个解码器模块包括三个子层:
子层 1:包括:注意力②、(残差+层归一化);
子层 2:包括:注意力③、(残差+层归一化);
子层 3:包括:前馈网络、(残差+层归一化);
见图 9.10(d)。
9.2.2. Transformer 编码器
Transformer 编码器模块中还剩下什么我们没有涉及到的?
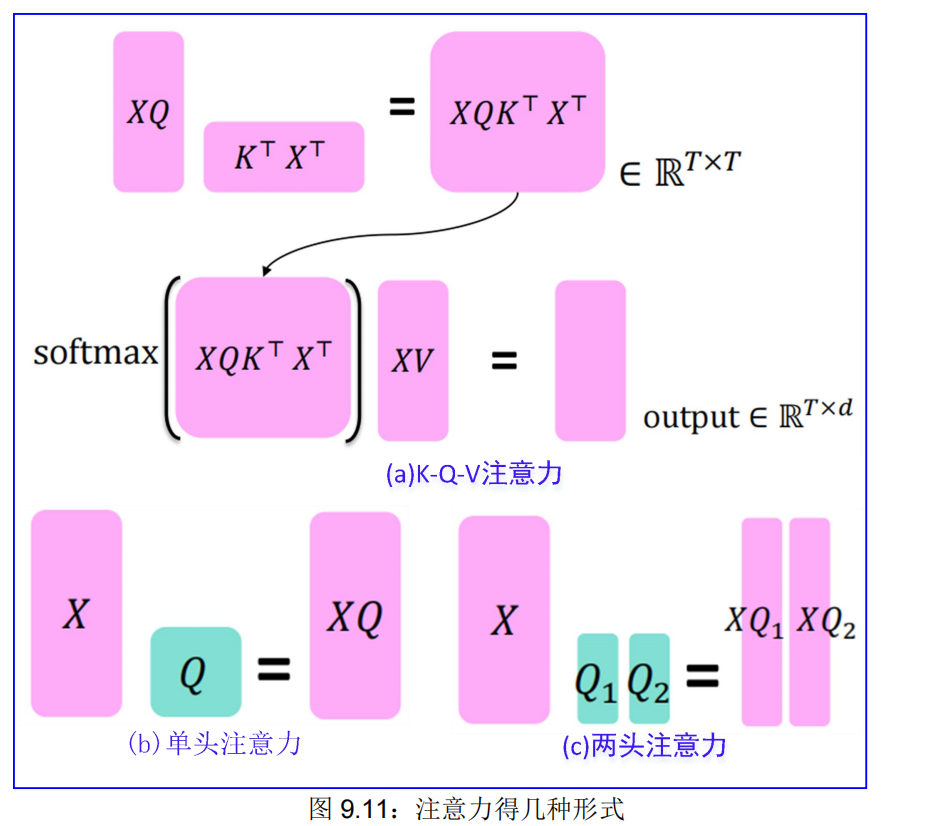
\1. K-Q-V 注意力:我们如何从单个词嵌入中得到 K、Q、V 向量?
2.多头注意力:在单层中关注多个地方。
\3. 帮助训练的技巧:
(1) 残差连接
(2) 层归一化
(3) 缩放点积
(4) 这些技巧并不能改善模型的能力,但它们有助于改善训练过程。当然,这两种改善都很重要。
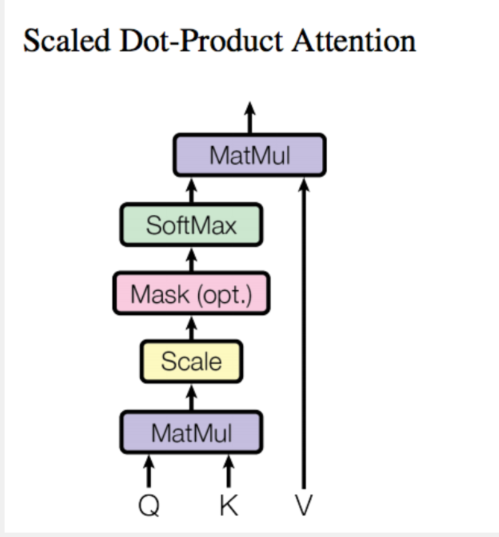
9.2.2.1. K-Q-V 注意力
参考self-attention计算公式图

9.2.2.2. 多头注意力★

9.2.2.3. 残差连接★
说白了 残差连接可以实现跳层操作,避免在一些不需要训练的地方浪费时间,就可以加快训练速度。

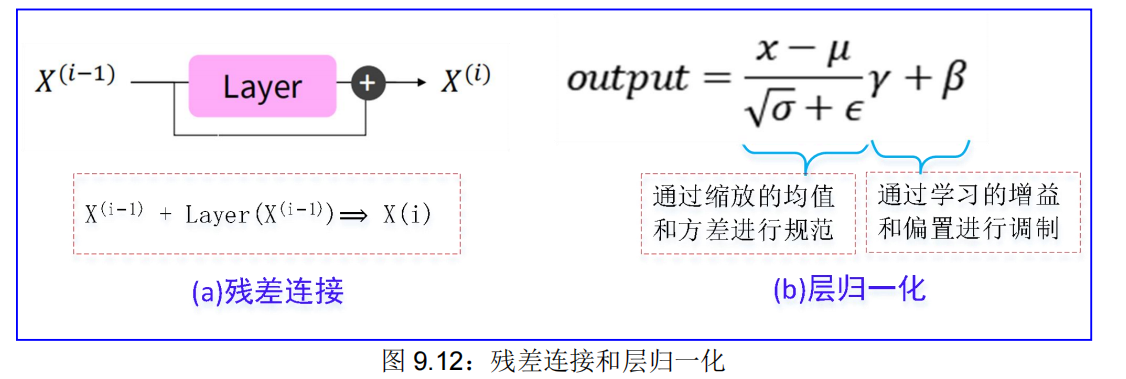
9.2.2.4. 归一化层★

9.2.2.5. 点积缩放★★

9.2.3. Transformer 解码器
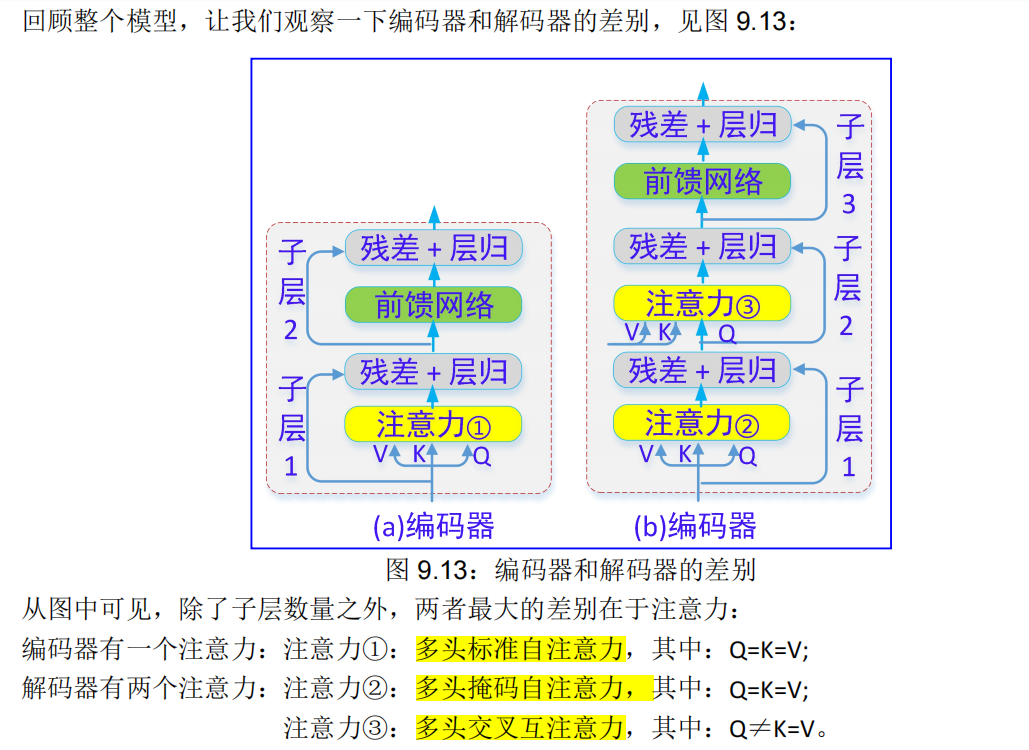
9.2.3.1. 掩码注意力★★★
解码器的多头掩码自注意力,Q、K、V 度来来同一数据源,即 Q=K=V,注意力的计算也是四个步骤:点积、缩放、分布、输出(见第 9.2.2.5),不过要注意,掩码操作(见第 9.1.5.3 节)在缩放计算之后。
9.2.3.2. 交叉注意力

9.2.4. Transformer 总体架构★
看下
Transformer 原始架构来自《Attention is All You Need》(弦外之音就是:RNN is NOT Need)论文,见图 9.14:
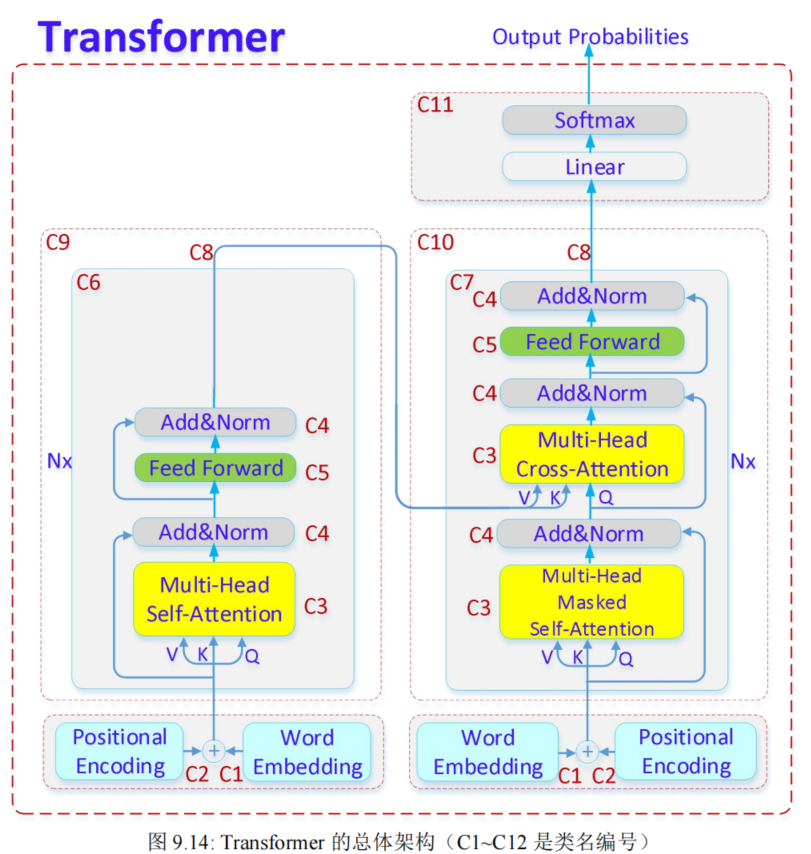
图 9.14 是在原始论文中 Transformer 架构图的基础上,稍作修改,为了方便描述和记忆,这里对源代码1中的 12 个类(class)名进行了编号:
C12:EncoderDecoder
C12 是编码器解码器,它是个总类,包括 2 个 C1、2 个 C2、1 个 C9、1 个 C10、1 个 C11;
C11:Generator
C11 是输出,包括一个**全连接层和一个 softmax 层**,负责把 top-N 候选输出序列找出来;
C10:Decoder
C10 是解码器栈,包含 6 个 C7 和 1 个 C8;
C9:Encoder
C9 是编码器栈,包含 6 个 C6 和 1 个 C8;
C8:LayerNorm
C8 是层归一化(带有可训练参数的,批归一化);
C7:DecoderLayer
C7 是解码器,包含 1 个 C3、2 个 C4 和 1 个 C5;
C6:EncoderLayer
C6 是编码器,包含 1 个 C3、2 个 C4 和 1 个 C5;
C5:PositionwiseFeedForward
C5 是**前馈网络(两层,全连接)**
C4:SubLayerConnection
C4 是残差连接和层归一化;
C3:MultiHeadedAttention
C3 是==多头注意力,包含三种:标准自注意力、掩码自注意力、交叉注意力==;
C2:PositionalEncoding
C2 是位置编码;
C1:Embeddings
C1 是词嵌入。
9.2.5. Transformer 十二个类★★
参考 Attention机制详解–(2)Self-Attention与Transformer–论文其他细节解读
9.2.5.1. Embeddings

9.2.5.2. PositionalEncoding★

9.2.5.3. Multi-Headed Attention★
注意力可以描述为将一个查询和一组键值对映射到一个输出,其中查询、键、值和输出都是向量。 输出是值的加权总和,其中分配给每个值的权重由查询与相应键的兼容性函数计算。

为什么要缩放**?**

为什么要多头?

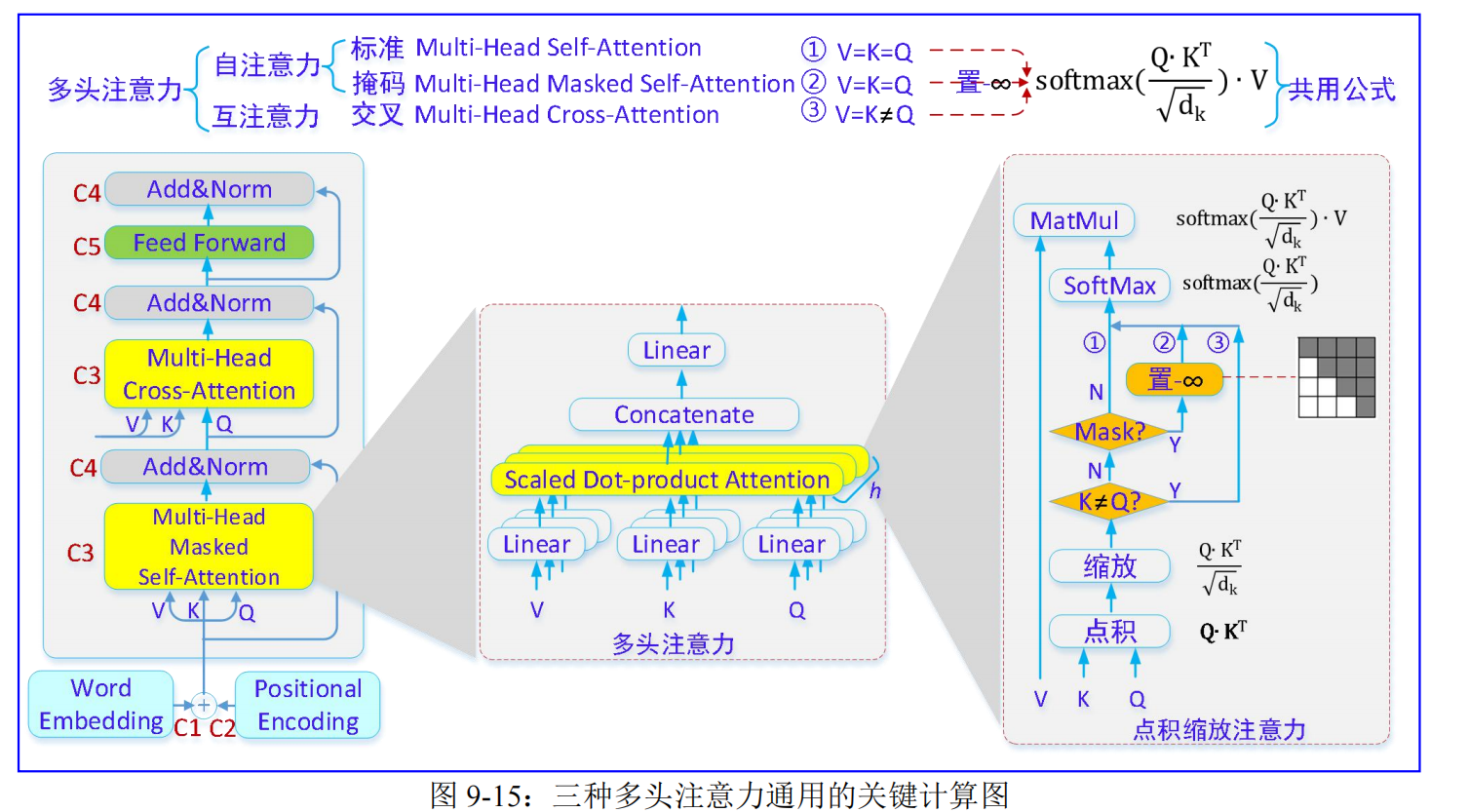
Transformer 以三种不同的方式使用多头注意力:
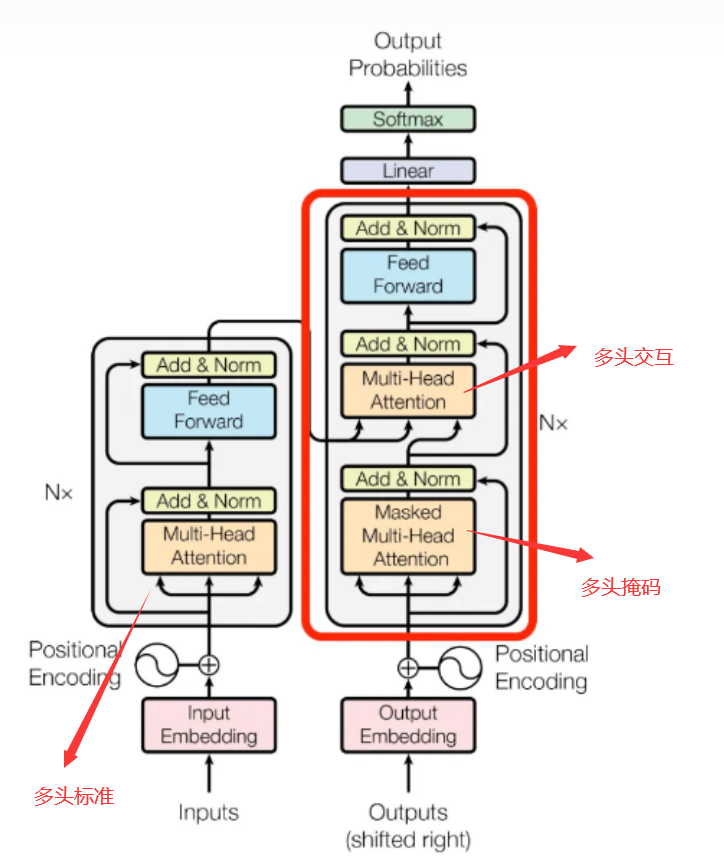
- 第一,多头标准自注意力:Multi-Headed Self-Attention
- 在编码器的自注意力(简称标准自注意力)模块中,所有的键、值和查询都来自同一个地方,在这种情况下,是编码器上一层的输出。编码器中的每个位置都可以参与编码器前一层中的所有位置。
- 第二,多头掩码自注意力:Masked Multi-Headed Self-Attention
- 为什么要掩码?
- 因为,解码器在预测的时候,采取自回归的方式,一个单词一个单词地顺序生成。在生成某一个单词的时候,会把前面所有已经生成的单词都输入进去。但==在训练时,只能使用当前单词前面的信息,不能使用后面的信息【避免窥测未来】==。
- 在解码器中的自注意力(简称掩码自注意力)模块中,允许解码器中的每个位置关注解码器中当前位置及之前(即左边)的所有位置。我们需要防止左边信息流过解码器以保留自回归特性。因此,在进行 softmax计算之前,那些与非法连接相对应的缩放点积注意力值**(相当于矩阵右上三角形里的值),都要被屏蔽掉(设置为 -∞)**。屏蔽方法就是加一个 Mask 矩阵,即让当前及以前的单词向量通过(矩阵白色部分),当前单词以后的设为-∞(矩阵灰色部分)。
- 为什么要掩码?
- 第三,多头交互注意力:Multi-Headed Cross-Attention
- 在解码器的互注意力(也称交叉注意力)层中,查询来自前一个解码器层,键和值来自编码器的输出。这允许解码器中的每个位置都参与输入序列中的所有位置。 这模仿了序列到序列模型中典型的编码器-解码器注意力机制。
- 三种多头注意力,共用同一个公式,计算过程是标准的四步:点积、缩放、分布、输出,见图 9.15:
9.2.5.4. SubLayerConnection★

9.2.5.5. PositionwiseFeedForward★

因为在 Multi-Head Attention 的内部结构中,我们进行的主要都是矩阵乘法(scaled Dot-Product Attention),即线性变换。而线性变换的学习能力是不如非线性变换的。所以,利用激活函数,对 Attention层计算出的 representation 的数值较大的部分则进行加强,而数值较小的部分则进行抑制,从而使得相关的部分表达效果更好。
Mor Geva 等人3指出:前馈层构成了变压器模型参数的三分之二,但它们在网络中的作用仍未得到充分探索。我们展示了基于 Transformer 的语言模型中的前馈层作为键值记忆运行,其中每个键与训练示例中的文本模式相关,每个值都会导致输出词汇的分布。我们的实验表明,学习到的模式是人类可解释的,下层倾向于捕捉浅层模式,而上层则学习更多语义模式。这些值通过诱导输出分布来补充键的输入模式,这些分布将概率集中在每个模式之后可能立即出现的标记上,特别是在上层。最后,我们证明了前馈层的输出是其记忆的组合,随后通过残差连接在整个模型的层中进行细化,以产生最终的输出分布(译者注:这里的记忆相当于 LSTM 里面的 Memory)。
9.2.5.8. LayerNorm★★


9.2.5.11. Generator★
这个类的作用是:通过对数值进行 linage+softmax 转换,预测下一个单词。
解码器栈的输出是一个 float 向量。我们怎么把这个向量转换为一个词呢?通过一个线性层再加上一个 Softmax 层实现转换,转换后的维度对应着输出类别的个数。若是翻译任务,则对应的是字典的大小。
首先,线性层是一个简单的全连接神经网络,将解码器栈的输出向量映射到一个更长的向量,这个向量被称为 logits 向量。假设词典有 10000 个单词,则 logits 向量有 10000 个数值,每个数表示一个单词的分数。
然后,Softmax 层会把**这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)**。
最后,选择最高概率所对应的单词,作为这个时间步的输出。
9.3.Transformer 的伟大成就
9.3.3. 预训练★★
不久之后,大多数 Transformers 结果还包括预训练(第 10 章)。
Transformer 的可并行性允许有效的预训练,并使它们成为事实上的标准。
通用语言理解评估基准(GLUE)是用于评估和分析多种已有自然语言理解任务的模型性能的工具。模型基于在所有任务的平均准确率进行评估。当前最佳结果可以在公开 GLUE 排行榜上查看。
在这个流行的基准上,所有顶级模型都是基于 Transformer(和预训练)的,见表 9.3:
9.4.Transformer 的优点和缺点
9.4.1. 优点:并行计算
自注意力相对于循环的好处之一是它是高度可并行化的。
9.4.2. 缺点:平方计算
自注意力中的平方计算:计算所有交互对意味着我们的**计算量与序列长度成二次方增长**!而对于循环模型,它只是线性增长!
作为序列长度函数的**平方计算,**它的操作总数随着 O(T 2d) 增长,其中 T 是序列长度,而 d 是维度。需要计算所有的交互对,时间复杂度是 O(T 2d),见图 9.16:
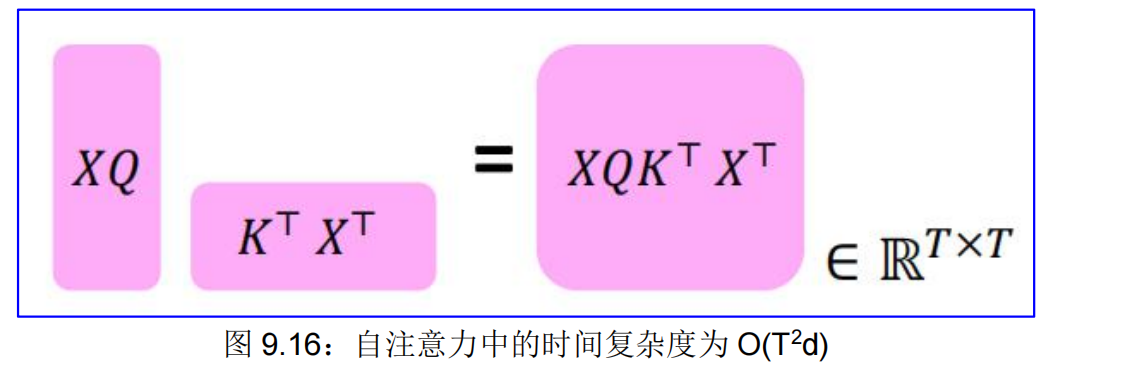
例如,假设 d=1000,那么,对于单个(较短的)句子,T≤ 30,T 2 ≤900。
在实践中,我们一般设置了一个界限,如 T = 512。
但是,如果我们想要处理长文档,T≥10,000,那么计算成本巨大。