总结:
1、softmax 函数公式,作用在输出层,把预测值转换成输出值的概率分布。
2、softmax函数加一个常量,结果不变,这个性质可以用在指数太大防止数值溢出,将x-max(x),其中x是矩阵,max(x)是行最大值。
3、sigmod函数,激活函数,把线性变成非线性。
4、损失函数
5、从损失函数到x输入的求导。
一、softmax

1.1 证明SoftMax对于任何输入向量x和任何常量c,结果不变。(1)式中x+c意味着把常数c加到x的每一个维度上。在实践中,利用
c = -max(xi,axis=1)(即求每一行的最大值),就是每一个xi值减去没一行的最大值,防止e^xi值溢出,而且这样比改变运算结果。
证明:softmax(x) = softmax(x + c)
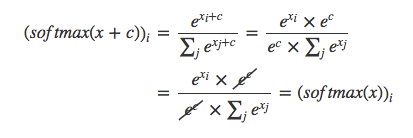
1.2 python实现sotfmax函数,要求既能处理向量,也能处理矩阵
学习到的知识点:
1.2.1 x_max = np.max(x, axis=1, keepdims=True) keepdims 运算后的结构保持矩阵结构
1.2.2 x = np.exp(x - x_max) / np.sum(np.exp(x - x_max), axis=1) #axis = 1, 每一行一个样本,每一个样本的概率归一化
1.2.3 np.allclose(test1, ans1, rtol=1e-05, atol=1e-06) #allclose方法,比较两个array是不是每一元素都相等,默认在1e-05的误差范围内import numpy as np
def softmax(x):
"""Compute the softmax function for each row of the input x. #每行是一个样本,每一列是各类的评分,归一化以每一行为对象。
It is crucial that this function is optimized for speed because
it will be used frequently in later code. You might find numpy
functions np.exp, np.sum, np.reshape, np.max, and numpy
broadcasting useful for this task.
Numpy broadcasting documentation:
http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html
You should also make sure that your code works for a single
D-dimensional vector (treat the vector as a single row) and
for N x D matrices. This may be useful for testing later. Also,
make sure that the dimensions of the output match the input.
You must implement the optimization in problem 1(a) of the
written assignment!
Arguments:
x -- A D dimensional vector or N x D dimensional numpy matrix.
Return:
x -- You are allowed to modify x in-place
"""
orig_shape = x.shape
if len(x.shape) > 1:
# Matrix
### YOUR CODE HERE
x_max = np.max(x, axis=1, keepdims=True) #取每行的最大值, keepdims保持二维的特性,这样在下一步相减情况下,不会出错
x = np.exp(x - x_max) / np.sum(np.exp(x - x_max), axis=1, keepdims=True) #axis = 1, 每一行一个样本,每一个样本的概率归一化
# raise NotImplementedError
### END YOUR CODE
else:
# Vector 列向量,只有一个样本。
### YOUR CODE HERE
x_max = np.max(x)
x = np.exp(x - x_max) / np.sum(np.exp(x - x_max))
# raise NotImplementedError
### END YOUR CODE
assert x.shape == orig_shape
return x
# from q1_softmax import softmax
# return 20 if softmax(测试值) == 正确值 else 0
def test_softmax_basic():
"""
Some simple tests to get you started.
Warning: these are not exhaustive.
"""
print("Running basic tests...")
test1 = softmax(np.array([1,2]))
print(test1)
ans1 = np.array([0.26894142, 0.73105858])
assert np.allclose(test1, ans1, rtol=1e-05, atol=1e-06) #allclose方法,比较两个array是不是每一元素都相等,默认在1e-05的误差范围内
test2 = softmax(np.array([[1001,1002],[3,4]]))
print(test2)
ans2 = np.array([
[0.26894142, 0.73105858],
[0.26894142, 0.73105858]])
assert np.allclose(test2, ans2, rtol=1e-05, atol=1e-06)
test3 = softmax(np.array([[-1001,-1002]]))
print(test3)
ans3 = np.array([0.73105858, 0.26894142])
assert np.allclose(test3, ans3, rtol=1e-05, atol=1e-06)
print("You should be able to verify these results by hand!\n")
def test_softmax():
"""
Use this space to test your softmax implementation by running:
python q1_softmax.py
This function will not be called by the autograder, nor will
your tests be graded.
"""
print("Running your tests...")
### YOUR CODE HERE
# raise NotImplementedError
### END YOUR CODE
if __name__ == "__main__":
test_softmax_basic()
test_softmax()
二、神经网络的基础
2.1 推导sigmoid函数的导数


2.2 θ是全连接层输出,送到softmax,然后再经过cross entropy函数计算损失函数,求loss函数对θ的导数
softmax 求导 https://blog.csdn.net/cassiePython/article/details/80089760
https://blog.csdn.net/softee/article/details/54098277
https://blog.csdn.net/u014594538/article/details/81025963
https://blog.csdn.net/longxinchen_ml/article/details/51765418
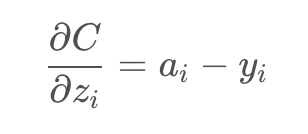

2.3 推导出单隐层神经网络关于输入x的梯度(也就是推导出∂J/∂x,其中J是神经网络的损失函数)。这个神经网络在隐层采用了sigmoid激活函数,在输出层采用了softmax函数。y是one-hot编码向量,使用了交叉熵损失。(使用σ′(x)作为sigmoid梯度,并且你可以任意为推导过中的中间变量命名)

这里的求导其实是将上面几问的求导相乘,再乘以一个x的求导就可以了。

2.4 上面所说的这个神经网络有多少个参数?我们可以假设输入是Dx维,输出是Dy,隐层单元有H个。

(x+1)* h + (h+1)*y
2.5 在q2_sigmoid.py中补充写出sigmoid激活函数的和求它的梯度的对应代码。并使用python q2_sigmoid.py进行测试,同样的,测试用例有可能不太详尽,因此尽量检查下自己的代码。

#!/usr/bin/env python
import numpy as np
def sigmoid(x):
"""
Compute the sigmoid function for the input here.
Arguments:
x -- A scalar or numpy array. x
Return:
s -- sigmoid(x)
"""
### YOUR CODE HERE
s = 1/(1+np.exp(-x))
### END YOUR CODE
return s
def sigmoid_grad(s):
"""
Compute the gradient for the sigmoid function here. Note that
for this implementation, the input s should be the sigmoid
function value of your original input x.
Arguments:
s -- A scalar or numpy array.
Return:
ds -- Your computed gradient.
"""
### YOUR CODE HERE
ds = s * (1 - s)
### END YOUR CODE
return ds
2.6 为了方便debugging,我们需要写一个梯度检查器。在q2_gradcheck.py中补充出来,使用python q2_gradcheck.py测试自己的代码。

梯度检查器,就是求导的定义。
# First implement a gradient checker by filling in the following functions
def gradcheck_naive(f, x):
""" Gradient check for a function f.
Arguments:
f -- a function that takes a single argument and outputs the
cost and its gradients
x -- the point (numpy array) to check the gradient at
"""
rndstate = random.getstate()
random.setstate(rndstate)
fx, grad = f(x) # Evaluate function value at original point #fx 是平方和函数,grad 2*x函数
h = 1e-4 # Do not change this!
# Iterate over all indexes ix in x to check the gradient.
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
ix = it.multi_index
# Try modifying x[ix] with h defined above to compute numerical
# gradients (numgrad).
# Use the centered difference of the gradient.
# It has smaller asymptotic error than forward / backward difference
# methods. If you are curious, check out here:
# https://math.stackexchange.com/questions/2326181/when-to-use-forward-or-central-difference-approximations
# Make sure you call random.setstate(rndstate)
# before calling f(x) each time. This will make it possible
# to test cost functions with built in randomness later.
### YOUR CODE HERE:
x[ix] += h
random.setstate(rndstate)
new_f1 = f(x)[0]
x[ix] -= 2*h
random.setstate(rndstate)
new_f2 = f(x)[0]
x[ix] += h
numgrad = (new_f1 - new_f2) / (2 * h)
### END YOUR CODE
# Compare gradients
reldiff = abs(numgrad - grad[ix]) / max(1, abs(numgrad), abs(grad[ix]))
if reldiff > 1e-5:
print("Gradient check failed.")
print("First gradient error found at index %s" % str(ix))
print("Your gradient: %f \t Numerical gradient: %f" % (
grad[ix], numgrad))
return
it.iternext() # Step to next dimension
print("Gradient check passed!")
2.7 现在,在q2 neural.py中,写出只有一个隐层且激活函数为sigmoid的神经网络前向和后向传播代码。使用python q2_neural.py测试自己的代码。

#!/usr/bin/env python
import numpy as np
import random
from q1_softmax import softmax
from q2_sigmoid import sigmoid, sigmoid_grad
from q2_gradcheck import gradcheck_naive
def forward_backward_prop(X, labels, params, dimensions):
"""
Forward and backward propagation for a two-layer sigmoidal network
Compute the forward propagation and for the cross entropy cost,
the backward propagation for the gradients for all parameters.
Notice the gradients computed here are different from the gradients in
the assignment sheet: they are w.r.t. weights, not inputs.
Arguments:
X -- M x Dx matrix, where each row is a training example x.
labels -- M x Dy matrix, where each row is a one-hot vector.
params -- Model parameters, these are unpacked for you.
dimensions -- A tuple of input dimension, number of hidden units
and output dimension
"""
### Unpack network parameters (do not modify)
ofs = 0
Dx, H, Dy = (dimensions[0], dimensions[1], dimensions[2])
W1 = np.reshape(params[ofs:ofs+ Dx * H], (Dx, H))
ofs += Dx * H
b1 = np.reshape(params[ofs:ofs + H], (1, H))
ofs += H
W2 = np.reshape(params[ofs:ofs + H * Dy], (H, Dy))
ofs += H * Dy
b2 = np.reshape(params[ofs:ofs + Dy], (1, Dy))
# Note: compute cost based on `sum` not `mean`.
### YOUR CODE HERE: forward propagation
h = sigmoid(np.dot(X,W1) + b1)
yhat = softmax(np.dot(h,W2) + b2)
### END YOUR CODE
### YOUR CODE HERE: backward propagation
cost = np.sum(-np.log(yhat[labels==1])) / X.shape[0]
d3 = (yhat - labels) / X.shape[0]
gradW2 = np.dot(h.T, d3)
gradb2 = np.sum(d3,0,keepdims=True)
dh = np.dot(d3,W2.T)
grad_h = sigmoid_grad(h) * dh
gradW1 = np.dot(X.T,grad_h)
gradb1 = np.sum(grad_h,0)
### END YOUR CODE
### Stack gradients (do not modify)
grad = np.concatenate((gradW1.flatten(), gradb1.flatten(),
gradW2.flatten(), gradb2.flatten()))
return cost, grad
def sanity_check():
"""
Set up fake data and parameters for the neural network, and test using
gradcheck.
"""
print("Running sanity check...")
N = 20
dimensions = [10, 5, 10]
data = np.random.randn(N, dimensions[0]) # each row will be a datum
labels = np.zeros((N, dimensions[2]))
for i in range(N):
labels[i, random.randint(0,dimensions[2]-1)] = 1
params = np.random.randn((dimensions[0] + 1) * dimensions[1] + (
dimensions[1] + 1) * dimensions[2], )
gradcheck_naive(lambda params:
forward_backward_prop(data, labels, params, dimensions), params)
def your_sanity_checks():
"""
Use this space add any additional sanity checks by running:
python q2_neural.py
This function will not be called by the autograder, nor will
your additional tests be graded.
"""
print("Running your sanity checks...")
### YOUR CODE HERE
# raise NotImplementedError
### END YOUR CODE
if __name__ == "__main__":
sanity_check()
your_sanity_checks()