学习笔记:cs224n3
学习视频:cs224n3
学习课件:cs224n3
上课的好处,就在于每节课老师都会解决几个问题,跟着老师的思路走,然后就可以清晰知道这节课学习了什么。
1,还是继续聊聊word2vec
对于word2vec而言,要遍历整个语料库的每个词,然后预测词的上下文的情况,根据损失函数的随机梯度下降,来求解二个词向量的情况。要更新的参数高达|V|*2*m。尤其对于传统的word2vec而言,在softmax的时候,存在很大的问题,因为数据量太大了,进行softmax的时候有很多的问题。
为了解决这个问题,所以,出现了二种Word2vec的实现,分层softmax和负采样,然后根据到底是知道中心词求上下文,还是知道上下文来求中心词,有CBOW,Skip-gram的实现方式。
其中分层softmax涉及到了哈夫曼树,负采样是更为简单的一种实现。
贴出原理贴:http://www.hankcs.com/nlp/word2vec.html#h3-12
对于skip-gram的实现,损失函数如下:
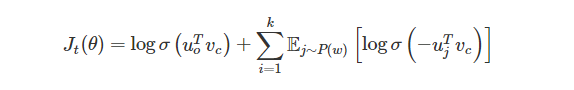
损失函数,用大白话来解释就是,使得出现在上下文的词向量的相似度尽可能高,对于不出现在上下文窗口的词,相似度尽可能的低。此时是通过窗口来作为训练单位,一个窗口或者几个窗口更新一下参数。
2,其他的词向量的处理办法
早在word2vec之前,就出现了很多的词向量的度量方法,这些方法基本都是基于统计共现矩阵。现在来一一解开面纱。
1)基于窗口的共现矩阵。
比如字典有N个词,那么会有一个N*N的一个记录表,来记录词的共现情况。每个元素表示二个词在语料库中共现的次数。
在这种词向量的度量中,首先很大,维度很大,与词表大小有关,其次,很难进行再次学习,也就是有新词来的时候,整个矩阵都需要改变,并且这种词向量的度量方式可能比one-hot好点,但稀疏性也是很高的。
2)SVD
在1)的基础上,我们为了降低维度,所以用了奇异值分解的手段,也就是将N维的向量,降低到k维,K可以是一个固定的低维的向量。还有一些可以改进的点,比如,去除停止词,也就是限制高频词的频次,词频可以用皮尔逊相关系数来进行代替,还可以根据与中心词的距离来衰减词频的权重,而不是统一的给一个度量,窗口不同的位置给予不同的权重。
在SVD中,计算复杂度还是很高的,不方便来训练新词,与深度学习的训练框架有很大的区分,移植性不强。
3,Glove的出现
对于基于统计共现矩阵的方法而言,有效的利用了共现的统计信息,但没有考虑到词语的相似度,语境的相似度问题,而且对于大规模的语料的应用也是很不妥的,计算复杂度很高。对于基于神经网络的词向量的方法而言,有窗口的存在,可以捕捉到局部的统计信息,利用到了上下文,也就是语境的信息,但无法利用到单词的全局统计信息。
所以,为了综合二大类方法,GlOVE出现了。对于第一种方法,可以说串行的词向量抽取,第二种方法,可以说是并行的词向量抽取的方法。用个专业的名词来解释,syntagmatic models/paradigmatic models 详细看这篇文章。https://www.cnblogs.com/Determined22/p/5780305.html
对于Glove的损失函数:
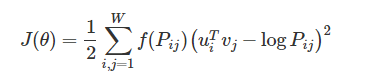
其中,u,v向量等价,最后的向量为二个的求和平均(当然这个平均可以说有也可以说无,毕竟就是一个常数项,放在那里都行)。P为共现矩阵,然后f函数是一个调节的参数。
对于GLove而言,有点在于可以扩展到大语料库,当然,其也适用于小规模的语料库和小向量。
4,对于词向量模型的评价
分为了内部(intrinsic),外部(extrinsic)二种评测的办法。
对于内部的评测方法,可以专门的测验,就是通过与人标注的结果来进行比对,好处是计算块,但坏处是不知道这种提升在实际中是不是有那么大的用处。
对于外部评测,需要在实际的系统应用中进行调节,这种调节起来就很慢了,而且解耦合做的不好,你根本不知道什么起到了作用,你不知道什么没有起到作用。
具体的来说,对于内部的评测方法,一般可以通过可视化的方法,通过词语之间的某些联系来进行测试,判断是否具有平行的关系来进行表述。对于外部评测来说,肯定就是通过外在应用的评价的好坏来进行判断了。
5,对于词向量的调参
1)窗口是否对称,是否只考虑到了单边的效果。
2)向量维度的大小设定是否合理。
3)窗口的大小设置是否合理。