写在前面:
1.笔记重点是python代码实现,不叙述如何推导。参考本篇笔记前,要有逻辑回归的基础(熟悉代价函数、梯度下降、矩阵运算和python等知识),没有基础的同学可通过网易云课堂上吴恩达老师的机器学习课程学习。网上也有一些对吴恩达老师课后作业的python实现,大多数都是用Jupyter Notebook写的,一些重点的细节处没有做详细的说明而且基本上没有绘制图像的代码(我自以为我的笔记和代码解决了这些问题 ^ _ ^ ),因此非常不利于新手学习。我把自己学习过程中整理的笔记和代码放到CSDN上希望对初学者有所帮助。
2.此笔记讲基于ex2data2.txt数据集的代码实现,ex2data2.txt数据集与ex2data1.txt数据集的格式基本一致,代码实现的流程上一致,不同处是特征提取和边界函数的图像绘制上。因此本篇笔记的代码是基于我的上一篇笔记《吴恩达机器学习逻辑回归python实现[对应ex2-ex2data1.txt数据集]》中提供的代码基础上修改,此篇笔记不再详细叙述其流程,重点叙述要修改的地方。ps:本篇笔记的代码中未进行正则化处理。
3.这篇笔记的重点:这篇笔记的案例是基于吴恩达机器学习逻辑回归课后作业中的ex2-ex2data2.txt数据集的。在ex2data1.txt数据集中边界函数是一个一元一次函数,因此,基于ex2data1.txt数据集画边界函数非常简单。而在ex2data2.txt数据集中我们要预设的边界函数是一个高阶函数,因此再使用上一篇笔记中的代码不能绘制出高阶函数的曲线,此外,在此笔记的案例中,两个特征不能满足边界函数的要求,需要通过数据集中的数据计算出多个新的特征,以满足边界函数的要求。这是此案例中要解决的两个难点。
1.训练数据对应的散点图
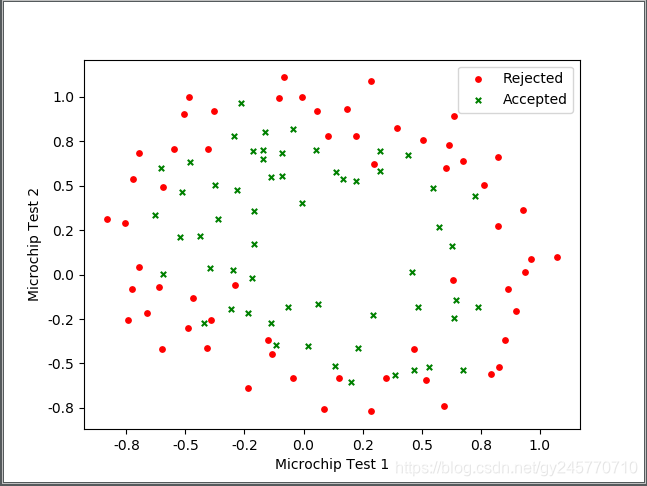
对应的python代码:
# 数据导入
def import_data():
# 定义x y数据 x1 y1:未通过 x2 y2:通过
x1 = []
y1 = []
x2 = []
y2 = []
# 导入训练数据
train_data = open("data/ex2data2.txt")
# 获取数据集的行数
lines = train_data.readlines()
# 循环处理所有的数据
for line in lines:
scores = line.split(",")
isQualified = scores[2].replace("\n", "")
if isQualified == "0":
x1.append(float(scores[0]))
y1.append(float(scores[1]))
else:
x2.append(float(scores[0]))
y2.append(float(scores[1]))
return x1, y1, x2, y2
# 图表绘制
def draw(x1, y1, x2, y2):
plt.xlabel("Microchip Test 1")
plt.ylabel("Microchip Test 2")
# 记号形状 颜色 点的大小 设置标签
plt.scatter(x1, y1, marker='o', color='red', s=15, label='Rejected')
plt.scatter(x2, y2, marker='x', color='green', s=15, label='Accepted')
# 注释的显示位置:右上角
plt.legend(loc='upper right')
# 设置坐标轴上刻度的精度
plt.gca().xaxis.set_major_formatter(ticker.FormatStrFormatter('%.1f'))
plt.gca().yaxis.set_major_formatter(ticker.FormatStrFormatter('%.1f'))
# 绘制
plt.show()
2.决策边界的定义
观察图像可知,此处的决策边界是非线性的,需要将决策边界定义为高阶函数。即定义
在本次实验中定义了最高为6阶函数,阶数可自行定义(阶数不能小于2),阶数越高模型会越过拟合(这个规律大家可在代码中自行测试,改变代码main函数中的degree的大小观察预测错误个数和绘制的图像),设置为6阶后,输入的特征由两个变为28个,因此需要对输入的特征进行重新构造,由两个特征构造为28个。
因为使用矩阵进行运算,特征数量的变化不会影响代码中决策边界函数的发生变化,即无论特征的个数如何变化,决策边界函数永远是θX的形式。因此决策边界函数的仍为:
# 定义边界函数
def hypothesis(theta, x):
return np.dot(x, theta)
由于在决策边界函数中,特征的个数由2个变为28个,而给出的数据集中只有两个特征,因此需要基于本节(2.决策边界的定义)开头给出的决策边界函数,计算出θ3至θ27所对应的特征。修改init_data函数,在读取数据集到矩阵中时把需要计算的特征计算出来并添加到矩阵中,代码如下:
# 初始化数据
def init_data(file, degree):
# 两次测试对应的特征矩阵
data = []
# 标记对应的矩阵
label = []
# 读取文件
train_data = open(file)
lines = train_data.readlines()
for line in lines:
scores = line.split(",")
# 去除标记后面的换行符
isQualified = scores[2].replace("\n", "")
# 添加特征x0,设置为1
data.append([1, float(scores[0]), float(scores[1])])
label.append(int(isQualified))
# 添加特征量
feature_handler(data, degree)
# 标记矩阵转置,返回特征矩阵和标记矩阵
return np.array(data), np.array(label).transpose()
# 添加特征量
def feature_handler(data, degree):
for i in range(0, len(data)):
for j in range(2, degree + 1):
for k in range(0, j + 1):
data[i].extend([np.power(data[i][1], k) * np.power(data[i][2], (j - k))])
3. sigmoid函数、代价函数、梯度下降函数、求解theta与上篇笔记中的代码一致,没有改变
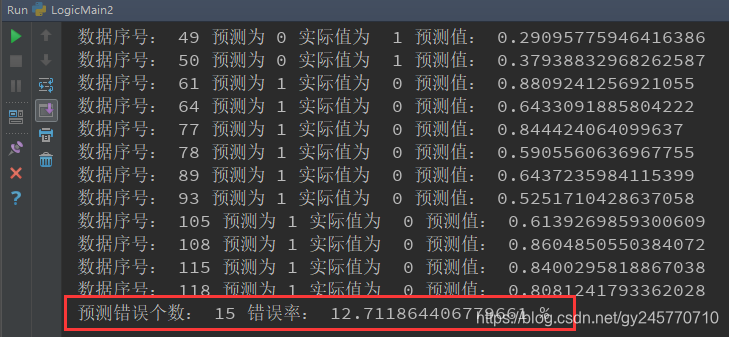
4. 添加验证函数
在上一篇笔记中,直接通过绘制边界函数的方式验证了最终的模型预测效果,而在这篇笔记中,我添加了验证函数,通过验证函数的结果和绘制边界图像两种方式一起验证最终的模型的预测效果。验证函数就是把求得的theta和特征带入到sigmoid函数中,如果计算的值大于等于0.5那么认为预测结果为1,即通过测试,否则认为预测结果为0,未通过测试。代码如下:
# 验证函数
def check(theta, check_file, degree):
#读取特征
data, label = init_data(check_file, degree)
# 将数据导入模型
check_label = sigmoid(theta, data)
# 对预测结果进行处理
error = 0
for i in range(0, len(check_label)):
if check_label[i] >= 0.5:
if label[i] != 1:
print("数据序号:", i + 1, "预测为 1 实际值为 ", label[i], "预测值:", check_label[i])
error += 1
else:
if label[i] != 0:
print("数据序号:", i + 1, "预测为 0 实际值为 ", label[i], "预测值:", check_label[i])
error += 1
print("预测错误个数:", error, "错误率:", error / len(check_label) * 100, "%")
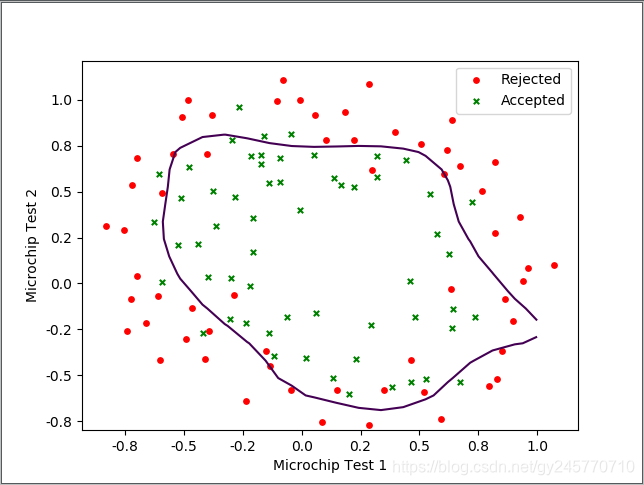
5.绘制决策边界图像
因为边界函数是一个高阶的方程,因此直接画出图形不好绘制。因此可以利用等高线 np.contour()绘图,高阶的函数得到的曲线一定是立体的,你可以想象成一个不规则的碗的形状扣下二维坐标轴的正上方。然后可以在碗上画出一圈一圈的等高线,那么在高度为0的那一条线正式与XY坐标轴平面相交的那条线,因此我们通过xy以及设定x y的值,并通过已经求得theta值结合预测边界函数求得z值,通过 np.contour()绘出高度为0的等高线就是我们的预测边界函数的图像了。可参考:https://blog.csdn.net/cowry5/article/details/80261260
代码如下:
# 决策边界图像绘制
def decision_boundary(theta):
x = np.linspace(-.8, 1.0, 20) # x坐标
y = np.linspace(-.8, 1.0, 20) # y坐标
xx, yy = np.meshgrid(x, y) # 生成网格数据
# 构造[1, x1, x2]格式的数据
feature = []
for i in range(0, x.shape[0]):
for j in range(0, x.shape[0]):
feature.append([1, x[i], x[j]])
# 添加剩余的特征
feature_handler(feature, 6)
# 计算z值
z = feature @ theta
# 保持维度一致
z = z.reshape(xx.shape)
# 绘制高度为0的等高线
plt.contour(xx, yy, z, 0)
#绘制测试数据的散点图
x1, y1, x2, y2 = import_data()
draw(x1, y1, x2, y2)
plt.show()
需要注意的是xx, yy = np.meshgrid(x, y) # 生成网格数据 这行代码生成了20*20个点,因此我们求得的z也应该是20个点,因此在 # 构造[1, x1, x2]格式的数据这一步时我们要构造40个点的坐标,而不是20个点的坐标。
6.主函数
'''主函数'''
if __name__ == '__main__':
# 数据观察
# x1, y1, x2, y2 = import_data()
# draw(x1, y1, x2, y2)
#预测边界函数的阶数
degree = 6
data, label = init_data("data/ex2data2.txt", degree)
# 初始化theta, 特征个数 = (阶数+1)*(阶数+2)/2
feature_number = int((degree+1)*(degree + 2)/2)
theta = np.zeros((feature_number, 1))
# 使用minimize函数求解
result = opt.minimize(fun=cost, x0=theta, args=(data, label), method='Newton-CG', jac=gradient)
# 数据校验
check(result.x, "data/ex2data2.txt", degree)
# 绘制边界函数图像
decision_boundary(np.mat(result.x).transpose(), degree)
在主函数中,我并没有将数据集按70%作为训练数据,30%作为验证数据,而是将所有的数据作为训练数据,而且验证函数验证时也将所有的训练数据进行验证。大家在实验时可按照7:3的比例将数据集分开。
边界函数绘制曲线如下图所示:
验证函数输出的结果:
7. 完整代码
from matplotlib import pyplot as plt
from numpy import *
import matplotlib.ticker as ticker
import numpy as np
import scipy.optimize as opt
# 数据导入
def import_data():
# 定义x y数据 x1 y1:未通过 x2 y2:通过
x1 = []
y1 = []
x2 = []
y2 = []
# 导入训练数据
train_data = open("data/ex2data2.txt")
# 获取数据集的行数
lines = train_data.readlines()
# 循环处理所有的数据
for line in lines:
scores = line.split(",")
isQualified = scores[2].replace("\n", "")
if isQualified == "0":
x1.append(float(scores[0]))
y1.append(float(scores[1]))
else:
x2.append(float(scores[0]))
y2.append(float(scores[1]))
return x1, y1, x2, y2
# 图表绘制
def draw(x1, y1, x2, y2):
plt.xlabel("Microchip Test 1")
plt.ylabel("Microchip Test 2")
# 记号形状 颜色 点的大小 设置标签
plt.scatter(x1, y1, marker='o', color='red', s=15, label='Rejected')
plt.scatter(x2, y2, marker='x', color='green', s=15, label='Accepted')
# 注释的显示位置:右上角
plt.legend(loc='upper right')
# 设置坐标轴上刻度的精度
plt.gca().xaxis.set_major_formatter(ticker.FormatStrFormatter('%.1f'))
plt.gca().yaxis.set_major_formatter(ticker.FormatStrFormatter('%.1f'))
# 绘制
# plt.show()
# 初始化数据
def init_data(file, degree):
# 两次测试对应的特征矩阵
data = []
# 标记对应的矩阵
label = []
# 读取文件
train_data = open(file)
lines = train_data.readlines()
for line in lines:
scores = line.split(",")
# 去除标记后面的换行符
isQualified = scores[2].replace("\n", "")
# 添加特征x0,设置为1
data.append([1, float(scores[0]), float(scores[1])])
label.append(int(isQualified))
# 添加特征量
feature_handler(data, degree)
# 标记矩阵转置,返回特征矩阵和标记矩阵
return np.array(data), np.array(label).transpose()
# 添加特征量
def feature_handler(data, degree):
for i in range(0, len(data)):
for j in range(2, degree + 1):
for k in range(0, j + 1):
data[i].extend([np.power(data[i][1], k) * np.power(data[i][2], (j - k))])
# 定义边界函数
def hypothesis(theta, x):
return np.dot(x, theta)
# 定义sigmoid函数
def sigmoid(theta, x):
z = hypothesis(theta, x)
return 1.0 / (1 + exp(-z))
# 定义代价函数
def cost(theta, X, y):
return np.mean(-y * np.log(sigmoid(theta, X)) - (1 - y) * np.log(1 - sigmoid(theta, X)))
# 梯度下降函数
def gradient(theta, X, y):
return (1 / len(X)) * X.T @ (sigmoid(theta, X) - y)
# 验证函数
def check(theta, check_file, degree):
#读取特征
data, label = init_data(check_file, degree)
# 将数据导入模型
check_label = sigmoid(theta, data)
# 对预测结果进行处理
error = 0
for i in range(0, len(check_label)):
if check_label[i] >= 0.5:
if label[i] != 1:
print("数据序号:", i + 1, "预测为 1 实际值为 ", label[i], "预测值:", check_label[i])
error += 1
else:
if label[i] != 0:
print("数据序号:", i + 1, "预测为 0 实际值为 ", label[i], "预测值:", check_label[i])
error += 1
print("预测错误个数:", error, "错误率:", error / len(check_label) * 100, "%")
# 决策边界图像绘制
def decision_boundary(theta, degree):
x = np.linspace(-.8, 1.0, 20) # x坐标
y = np.linspace(-.8, 1.0, 20) # y坐标
xx, yy = np.meshgrid(x, y) # 生成网格数据
# 构造[1, x1, x2]格式的数据
feature = []
for i in range(0, x.shape[0]):
for j in range(0, x.shape[0]):
feature.append([1, x[i], x[j]])
# 添加剩余的特征
feature_handler(feature, degree)
# 计算z值
z = feature @ theta
# 保持维度一致
z = z.reshape(xx.shape)
# 绘制高度为0的等高线
plt.contour(xx, yy, z, 0)
# 绘制测试数据的散点图
x1, y1, x2, y2 = import_data()
draw(x1, y1, x2, y2)
plt.show()
'''主函数'''
if __name__ == '__main__':
# 数据观察
# x1, y1, x2, y2 = import_data()
# draw(x1, y1, x2, y2)
#预测函数的阶数
degree = 6
data, label = init_data("data/ex2data2.txt", degree)
# 初始化theta, 特征个数 = (阶数+1)*(阶数+2)/2
feature_number = int((degree+1)*(degree + 2)/2)
theta = np.zeros((feature_number, 1))
# 使用minimize函数求解
result = opt.minimize(fun=cost, x0=theta, args=(data, label), method='Newton-CG', jac=gradient)
# 数据校验
check(result.x, "data/ex2data2.txt", degree)
# 绘制预测图像
decision_boundary(np.mat(result.x).transpose(), degree)